- The paper introduces a novel benchmark that evaluates LLMs on generating comprehensive, article-level reports from real-world industrial tables.
- It employs a multi-stage annotation pipeline and three distinct evaluation criteria (NAC, ICC, GEC) to ensure numerical accuracy, content coverage, and reasoning depth.
- The study reveals that even top-performing models struggle with large and complex tables, highlighting the need for improved table understanding and synthesis.
T2R-bench: A Comprehensive Benchmark for Article-Level Report Generation from Real-World Industrial Tables
Motivation and Task Definition
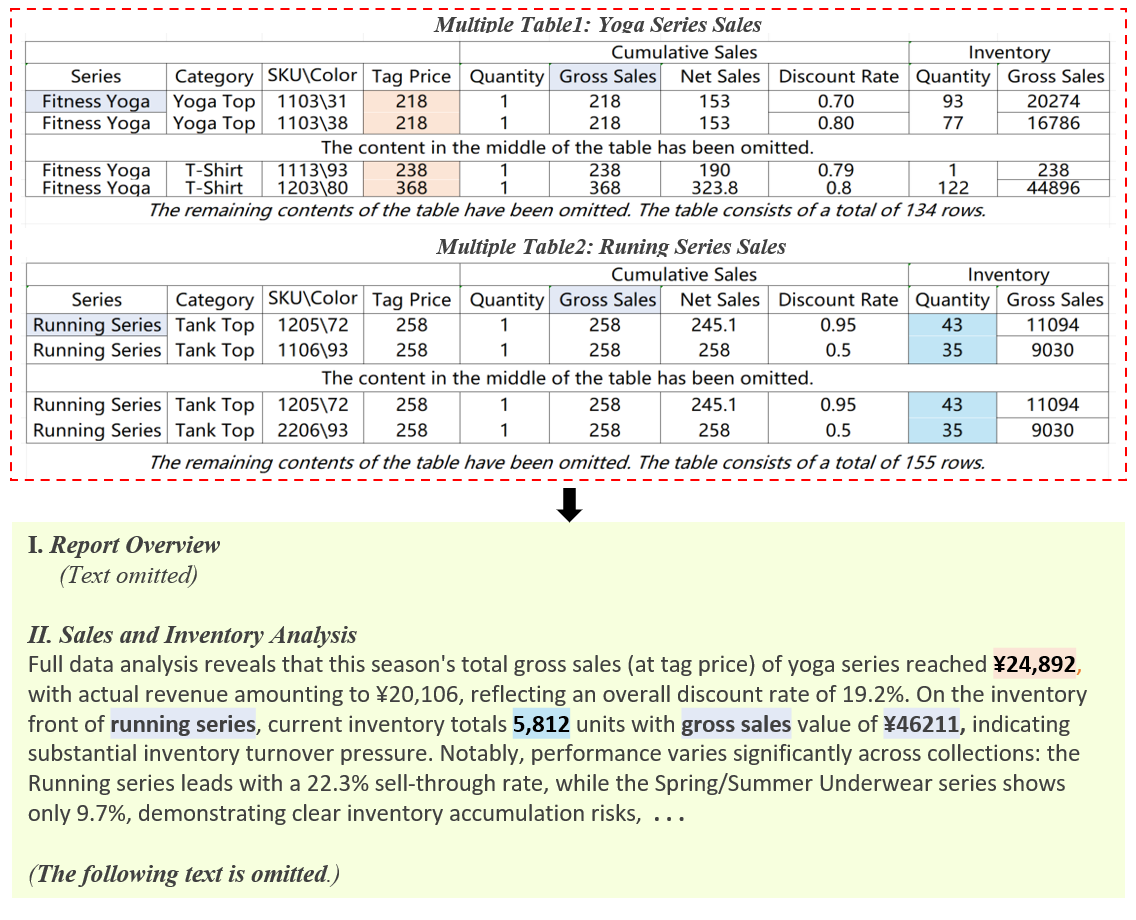
The T2R-bench paper addresses the critical gap in evaluating LLMs for the table-to-report (T2R) task, which requires generating comprehensive, article-level reports from complex, real-world industrial tables. Unlike prior benchmarks that focus on table question answering (QA) or table-to-text generation, T2R-bench targets the synthesis of multi-paragraph, analytical, and actionable reports that reflect the demands of business intelligence, industrial analytics, and enterprise reporting.
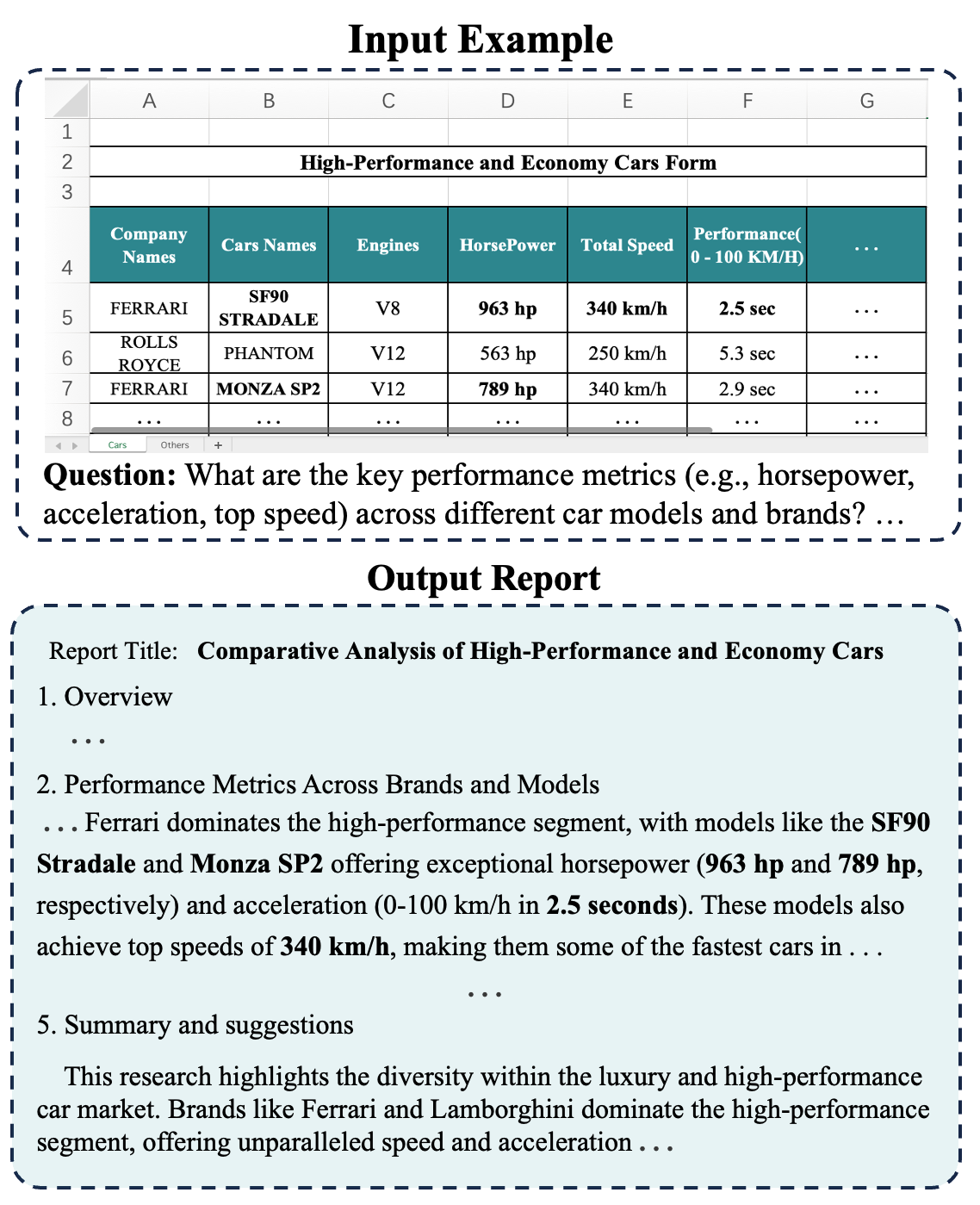
Figure 1: The table-to-report task requires models to analyze numerical data from tables and generate comprehensive, coherent, and accurate reports, including descriptions, analysis, and conclusions.
The T2R task is characterized by several unique challenges: (1) high table complexity and diversity (multi-table, complex headers, extremely large tables), (2) the need for deep reasoning and synthesis beyond fact extraction, and (3) the lack of suitable evaluation metrics for long-form, data-grounded report generation.
Benchmark Construction and Dataset Characteristics
T2R-bench comprises 457 real-world industrial tables, spanning 19 domains and four table types: single tables, multiple tables, complex structured tables, and extremely large-size tables. The data is sourced from public industrial datasets, government statistics, and open data platforms, with rigorous manual curation to ensure domain relevance, information density, and privacy compliance.
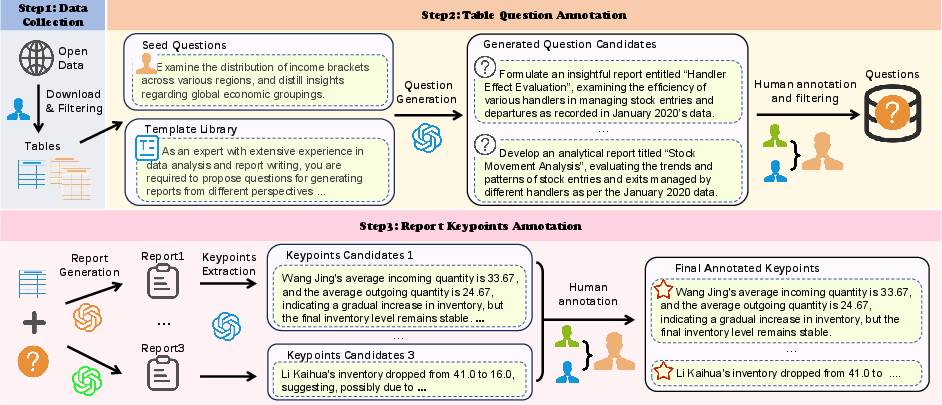
Figure 2: The construction pipeline for T2R-bench includes table data collection, question annotation, and report reference annotation, with multi-stage human and LLM involvement.
The annotation pipeline involves: (1) semi-automatic question generation using expert-designed prompts and LLM self-instruct, (2) dual-annotator filtering for question quality, and (3) report reference keypoint extraction, where multiple LLM-generated reports are distilled into core keypoints and further refined by human annotators. This process yields 910 high-quality questions and 4,320 annotated report keypoints.
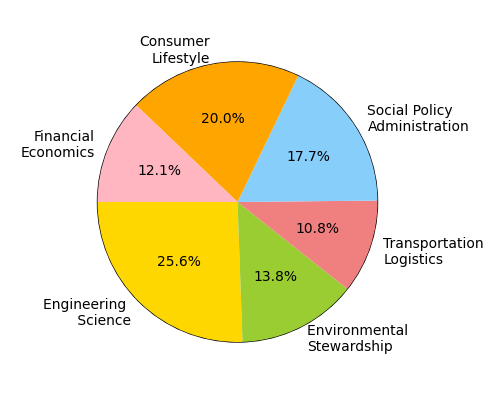
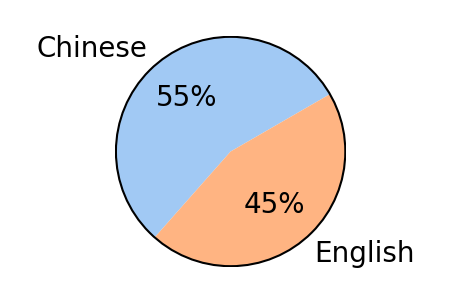
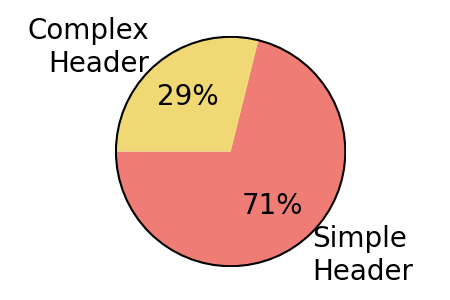
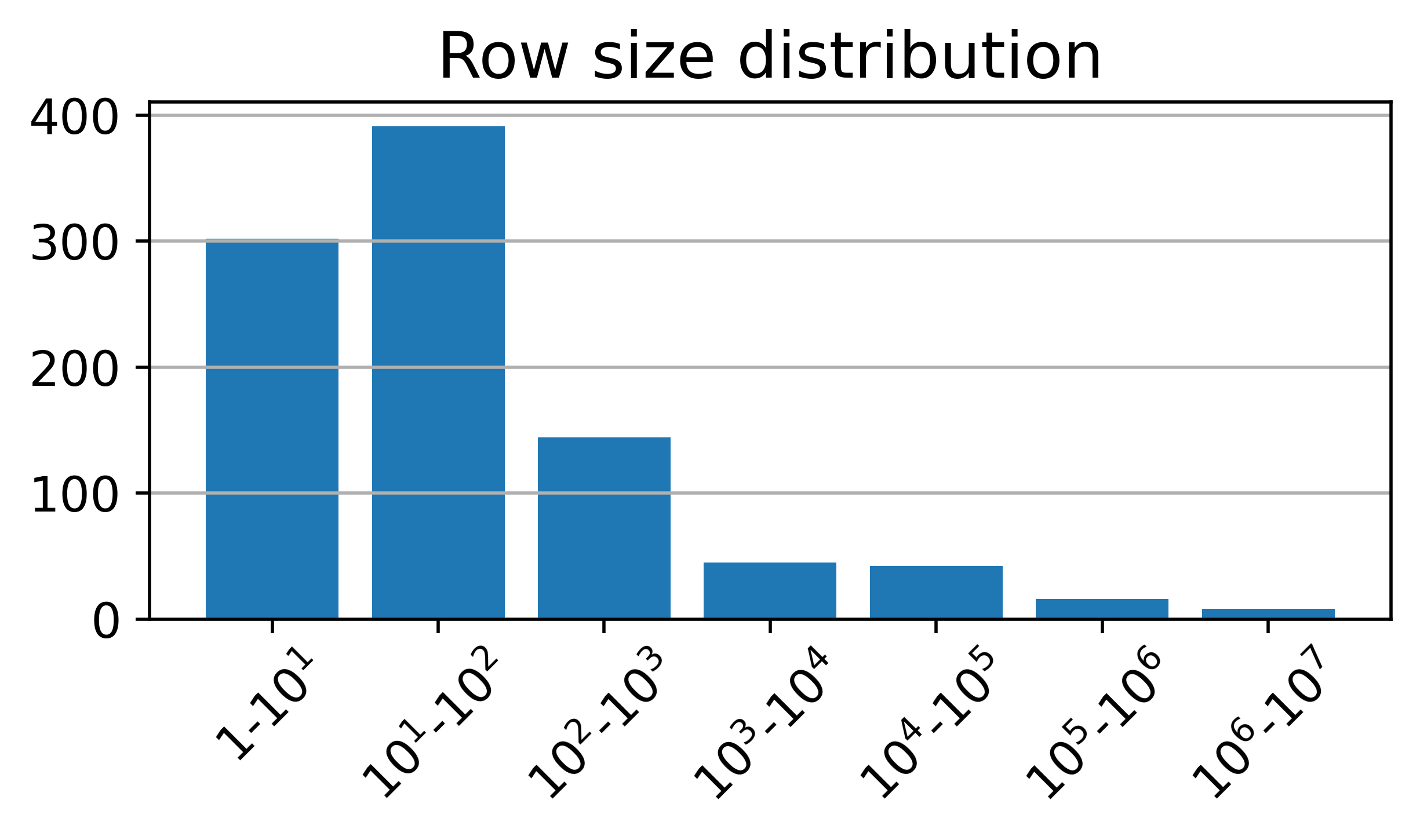
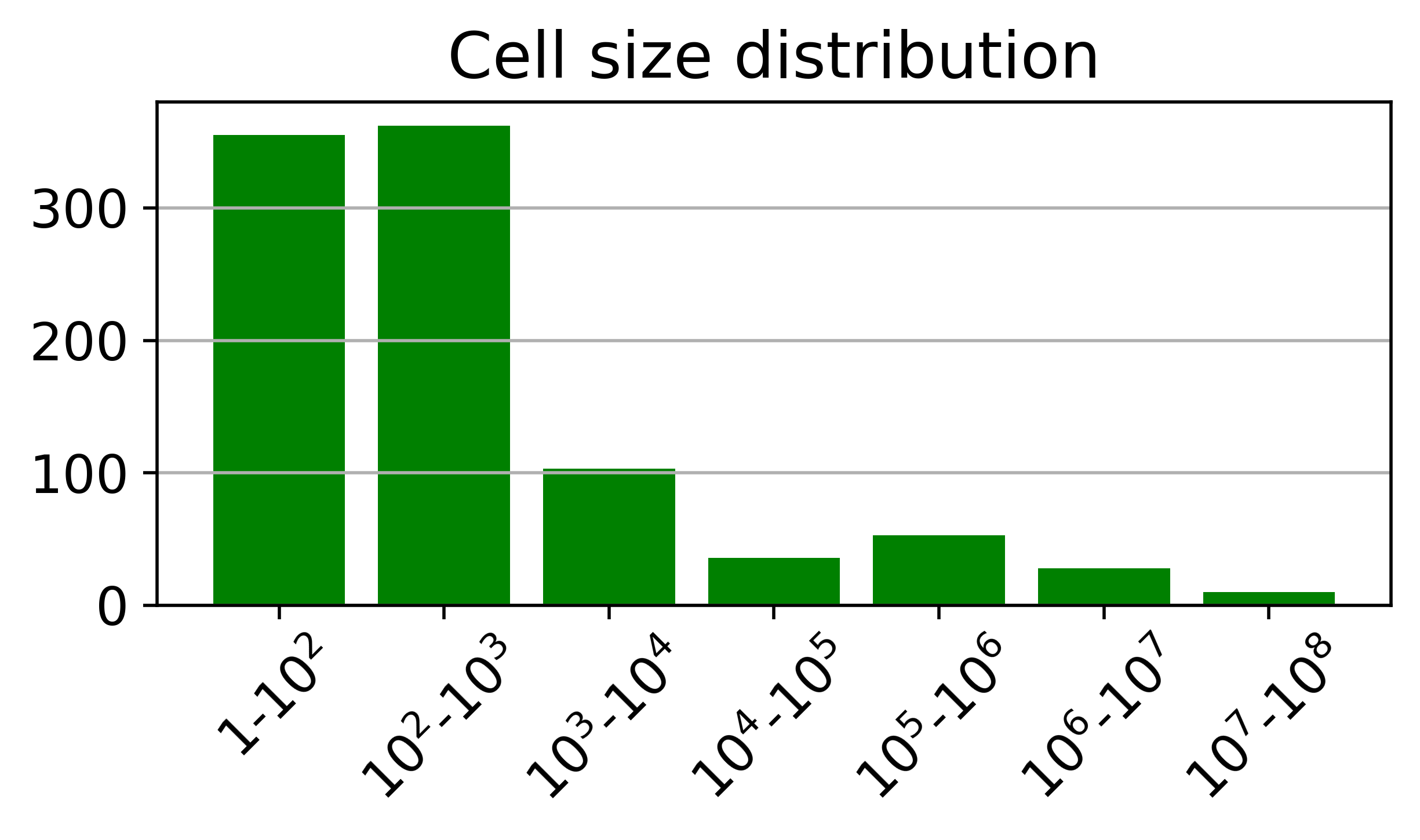
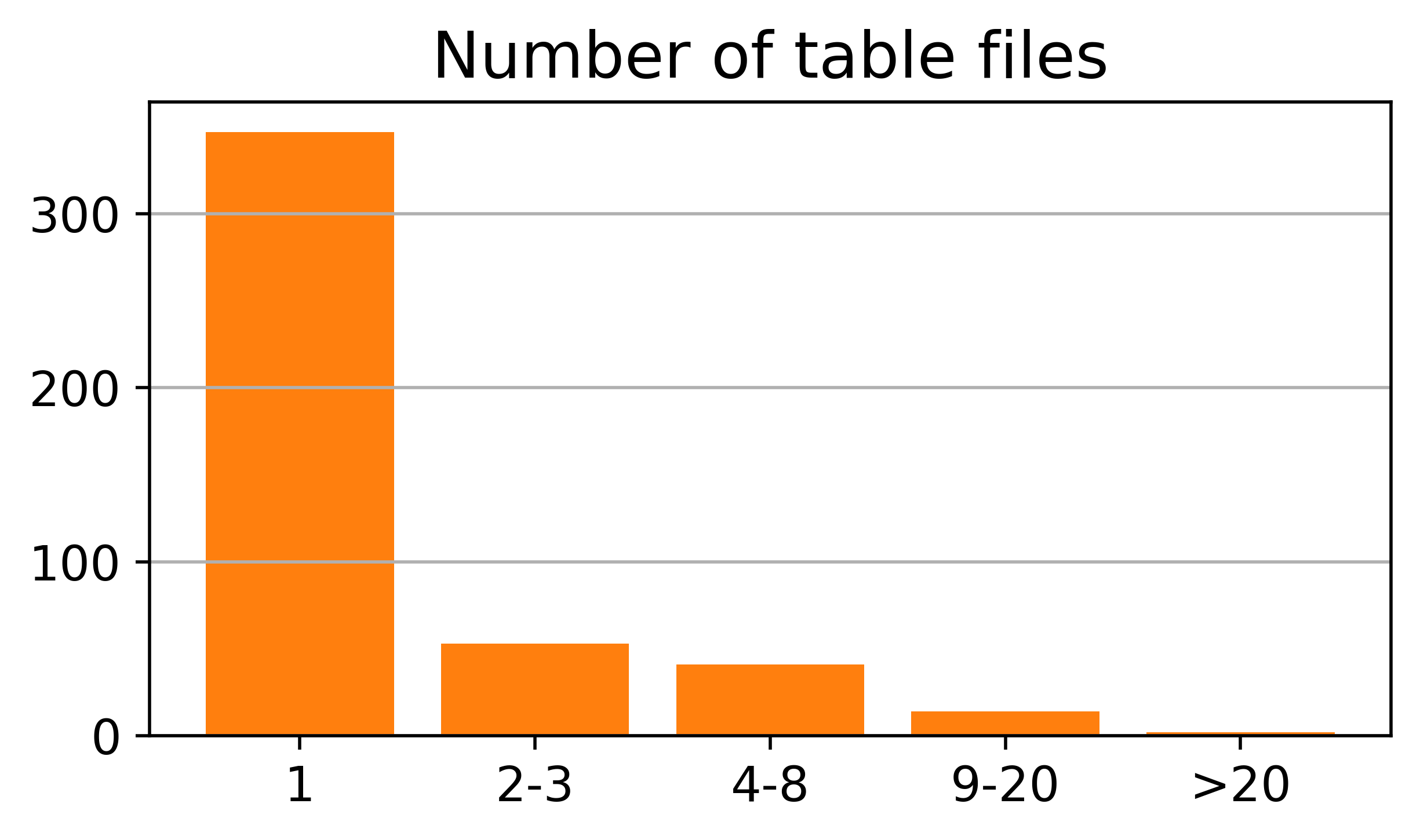
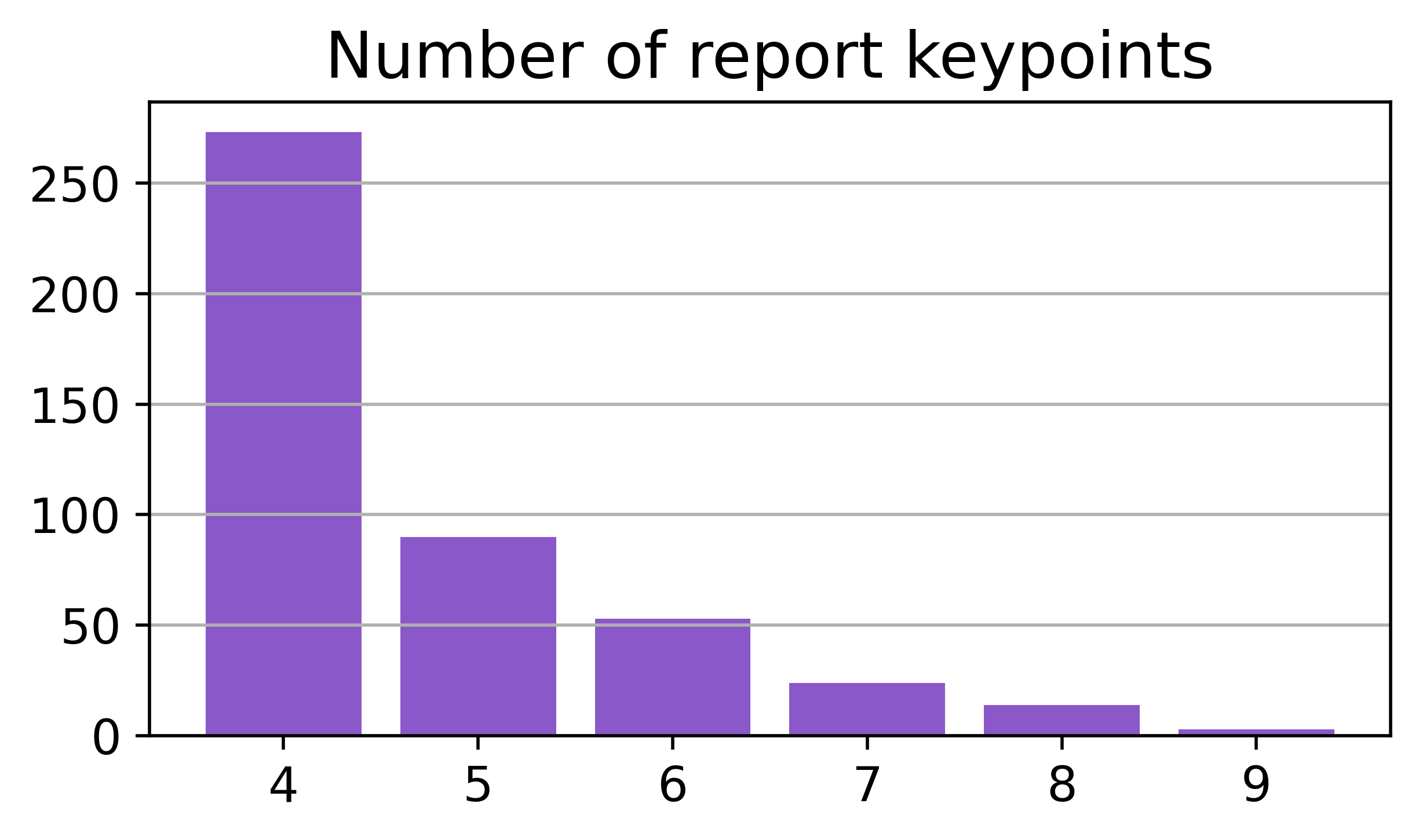
Figure 3: T2R-bench exhibits broad domain coverage, bilingual (Chinese/English) support, a high proportion of complex and large tables, and a diverse distribution of report keypoints per question.
Key dataset properties include:
- 8.3% of tables are extremely large (over 50,000 cells).
- 28.9% are complex structured tables (hierarchical headers, merged cells).
- 23.6% are multi-table scenarios.
- Bilingual coverage (Chinese and English) with balanced performance across languages.
Evaluation Criteria: Beyond Surface Metrics
Recognizing the inadequacy of standard text generation metrics (BLEU, ROUGE) for T2R, the authors propose a three-pronged evaluation framework:
- Numerical Accuracy Criterion (NAC): Measures the factual correctness of numerical statements in generated reports by extracting numerical claims, generating verification questions, and using code-generation LLMs to programmatically validate answers against the source tables. Majority voting among three code LLMs (Qwen2.5-32B-Coder-Instruct, Deepseek-Coder, CodeLlama-70B-Instruct) ensures robustness.
- Information Coverage Criterion (ICC): Quantifies semantic alignment between generated reports and annotated keypoints using a normalized mutual information (MI) formulation, with BERTScore as the similarity kernel. This captures both coverage and relevance of critical content.
- General Evaluation Criterion (GEC): Employs LLM-as-a-judge to rate reports on reasoning depth, human-like style, practicality, content completeness, and logical coherence, using a strict scoring rubric.
This framework is validated against human expert judgments, achieving high correlation (Pearson's r=0.908), and is more stringent than human evaluation, especially for factual and coverage errors.
Experimental Results and Analysis
Twenty-five state-of-the-art LLMs (open and closed source) are evaluated on T2R-bench. The best-performing model, Deepseek-R1, achieves only 62.71% average score across NAC, ICC, and GEC, with all models exhibiting substantial performance degradation on extremely large tables and multi-table scenarios.
Figure 4: LLM performance on NAC and ICC drops sharply as table cell count increases, highlighting the challenge of scaling to large tabular inputs.
Key findings:
Case studies and error analysis reveal:
- Frequent numerical hallucinations, especially in large or multi-table settings.
- Structural misinterpretation of complex headers and cross-table references.
- Truncation errors when table size exceeds context window.
- Missing keypoints and incomplete coverage, directly impacting ICC.
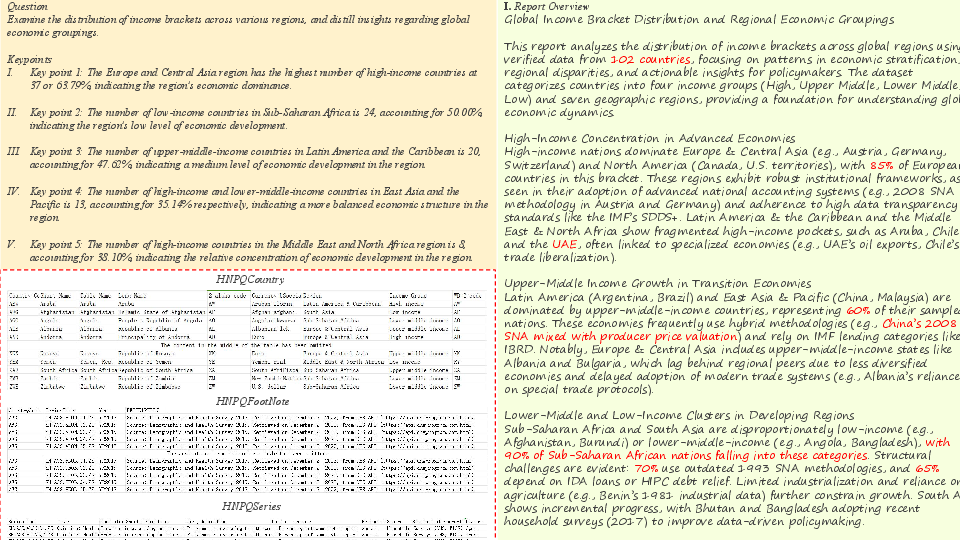
Figure 6: Case study of an English extremely large-size table, illustrating truncation and coverage errors in LLM-generated reports.

Figure 7: Case study of a Chinese complex structured table, highlighting numerical and structural reasoning failures.
Implications, Limitations, and Future Directions
T2R-bench exposes fundamental limitations in current LLMs' ability to perform deep, reliable, and scalable table-to-report generation. The low NAC and ICC scores, especially on large and complex tables, indicate that existing models lack robust mechanisms for numerical reasoning, structural comprehension, and long-context synthesis in industrial settings.
The benchmark's design—real-world data, bilingual support, multi-table and large-table coverage, and keypoint-based evaluation—sets a new standard for assessing practical table understanding and report generation. However, the authors note that further expansion in table diversity and the development of specialized architectures (e.g., hybrid symbolic-neural models, retrieval-augmented LLMs, or table-aware pretraining) are necessary to close the gap with human performance.
The evaluation framework, particularly the use of code LLMs for numerical verification and MI-based coverage metrics, provides a template for future benchmarks in data-to-text and long-form factual generation.
Conclusion
T2R-bench establishes a rigorous, high-coverage benchmark for the table-to-report task, revealing that even the strongest LLMs fall short of industrial requirements for article-level report generation from real-world tables. The benchmark, dataset, and evaluation methodology will drive research toward more reliable, scalable, and semantically faithful table understanding systems, with significant implications for business intelligence, automated analytics, and enterprise reporting.