- The paper introduces a novel framework that integrates 25 curated enterprise datasets to evaluate LLM performance across key domains.
- It employs tailored prompts and few-shot learning to assess 13 open-source models, highlighting trade-offs between model size and accuracy.
- The evaluation leverages metrics like weighted F1, ROUGE-L, and entity F1 to guide the selection of cost-effective LLMs for enterprise applications.
Enterprise Benchmarks for LLM Evaluation
Introduction
The paper "Enterprise Benchmarks for LLM Evaluation" introduces a novel framework for the evaluation of LLMs within enterprise contexts. Unlike existing benchmarks, this framework addresses the need for domain-specific evaluations, particularly focusing on enterprise applications such as finance, legal, climate, and cybersecurity. The paper proposes a systematic approach to evaluating LLMs by using a curated set of enterprise datasets that span various NLP tasks.
Benchmarking Framework
The framework builds upon Stanford's HELM (Holistic Evaluation of LLMs) by integrating 25 publicly available datasets across different enterprise domains. This augmentation allows for the comprehensive assessment of LLM performance in specialized settings. By focusing on real-world application requirements, the framework provides a standardized method for evaluating the capabilities of LLMs across various tasks and domains.
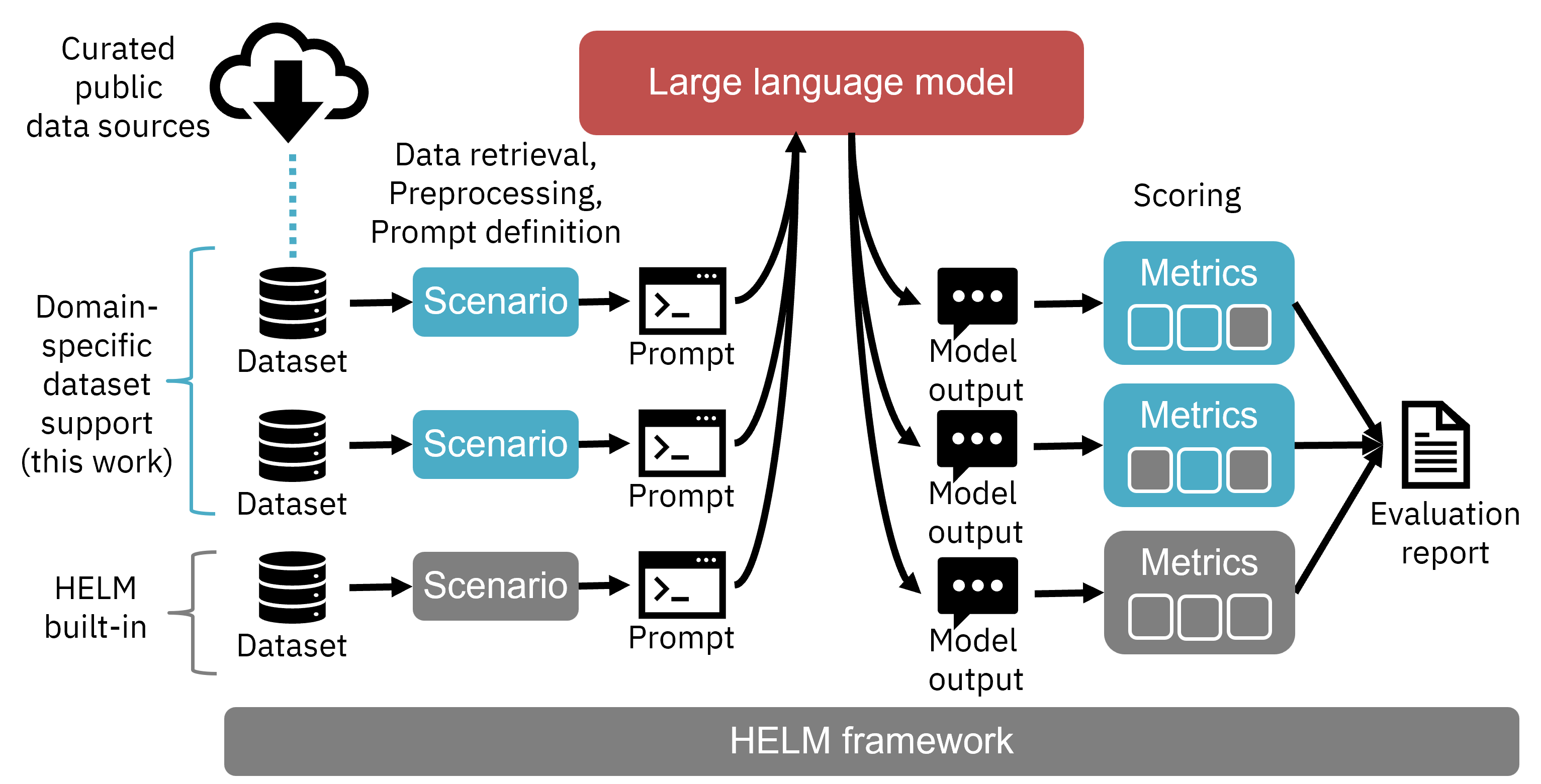
Figure 1: Overview of the enterprise benchmark framework for LLM evaluation.
Domain-Specific Datasets
The paper identifies four key enterprise domains—finance, legal, climate and sustainability, and cybersecurity—where domain-specific evaluation is crucial. Each domain is represented by a set of curated datasets that are open-source and cover a broad range of NLP tasks:
- Finance: Includes tasks like sentiment analysis, named entity recognition (NER), question answering (QA), and summarization.
- Legal: Comprises datasets focused on sentiment analysis, legal judgment prediction, and document summarization.
- Climate and Sustainability: Encompasses datasets for classifying climate-related sentiments and summarizing climate change claims.
- Cybersecurity: Involves classification and summarization of security-related documents, such as network protocol specifications and malware reports.
Evaluation and Results
The evaluation leverages 13 widely used open-source LLMs, including LLaMA2, GPT-NeoX-20B, FLAN-UL2, Phi-3.5, and Mistral 7B. The study examines these models across the proposed benchmarks, highlighting variations in performance relative to model size, training data, and architecture. The paper provides a detailed assessment of each model's effectiveness in handling enterprise-specific tasks and discusses the implications of model selection based on task requirements.
Prompts and Methodology
Prompts are crafted to suit each task in the evaluation framework, accommodating few-shot learning scenarios to optimize LLM capabilities. The methodology emphasizes the need for carefully designed prompts to ensure clarity and consistency across evaluations. Standard prompts are employed, with provisions for in-context learning examples to demonstrate model adaptability.
The paper evaluates the trade-offs between model parameter size and performance, emphasizing the importance of selecting cost-effective models suited to specific enterprise needs. Metrics such as weighted F1 scores, ROUGE-L, entity F1, and others are utilized to provide a comprehensive understanding of model performance across tasks.
Conclusion
In conclusion, the paper presents a robust framework for the evaluation of LLMs tailored to enterprise domains. By integrating diverse datasets and performance metrics, the framework addresses the gap in domain-specific LLM evaluation, providing practitioners with practical insights into model selection and optimization for enterprise applications. Future work involves the exploration of novel methodologies such as Retrieval-Augmented Generation and Chain-of-Thought prompting to further enhance the evaluation framework.