- The paper introduces PAD3R, which disentangles object and camera motions to enable dynamic 3D reconstruction from monocular videos.
- It uses a personalized PoseNet, neural skinning deformation, and bidirectional tracking supervision to enhance reconstruction fidelity.
- Experimental results on Consistent4D and Artemis datasets show superior performance over baselines using LPIPS, CLIP, and FVD metrics.
PAD3R: Pose-Aware Dynamic 3D Reconstruction from Casual Videos
PAD3R introduces a method for reconstructing dynamic 3D objects from monocular videos captured in casual settings. This paper addresses challenges in dynamic 3D reconstruction by disentangling object and camera motions, leveraging generative diffusion priors, and employing novel tracking strategies.
Methodology
Object-centric Camera Pose Initialization
PAD3R begins by selecting a video frame as the canonical keyframe to obtain a static 3D Gaussian model using an image-to-3D method. This model serves as the foundation for training PoseNet, a personalized pose estimator built on DINO-v2 backbones, to predict accurate object-centric camera poses, essential for initializing the dynamic reconstruction.
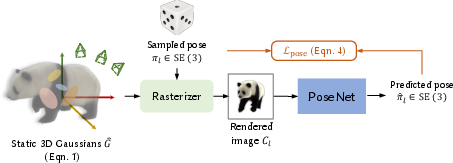
Figure 1: Training personalized PoseNet using random camera poses rendered from a static Gaussian model.
PoseNet training involves synthesizing images from the optimized Gaussian model and applying augmentations to learn robust camera poses in relation to the object. This initialization is crucial for later stages of dynamic reconstruction and helpful in scenarios lacking static constraints.
Dynamic Gaussian Splats Reconstruction
The reconstruction process applies a neural skinning deformation model, predicting per-frame deformations anchored to mesh vertices. A hybrid deformation framework blending Linear Blend Skinning (LBS) and Dual Quaternion Skinning (DQS) enhances the model's ability to capture articulated dynamics.
Dense tracking supervision introduces 2D tracking models that capture temporal correspondences and motion dynamics, which, when combined with multi-chunk point tracking, improves reconstruction by leveraging bidirectional point overlap between video frames for solid supervision guidance.
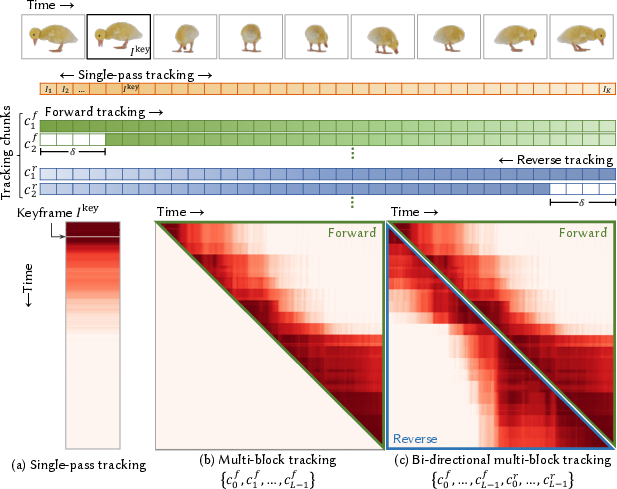
Figure 2: Co-visibility of tracked points enhances coverage through a bi-directional multi-block tracking strategy.
Optimization comprises various losses focused on ensuring reconstruction fidelity—photometric, ARAP regularization for maintaining rigidity, and stage-specific camera motion refinement. Integrating these components yields high-fidelity reconstructive capabilities across complex scenes.
Experimental Results
Quantitative results on datasets like Consistent4D and Artemis demonstrate PAD3R's superior performance in geometric fidelity and temporal coherence, especially under dynamic camera settings. The approach excels across LPIPS, CLIP, and FVD metrics. It maintains robustness even with constrained viewpoint variation, illustrating its adaptability.

Figure 3: Comparison against baseline methods shows superior view synthesis fidelity in PAD3R reconstructions.
A comprehensive performance analysis further illustrates PAD3R's consistency in delivering accurate reconstructions across varying view coverage angles, outperforming baseline models such as DreamMesh4D and BANMo.
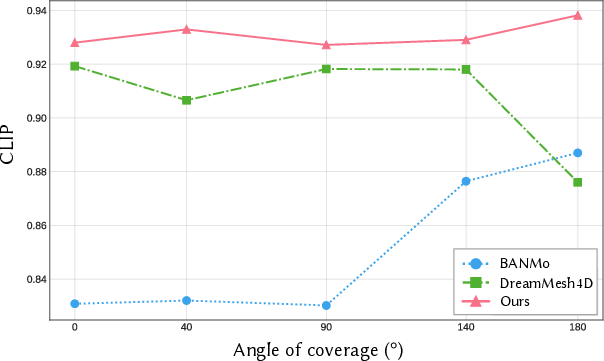
Figure 4: PAD3R consistently delivers high reconstruction quality across diverse viewpoint coverage.
Ablation Studies
Ablation studies validate the significance of each design component—pose initialization with PoseNet, tracking regularizers, and camera modeling—demonstrating their collective impact on achieving robust and coherent dynamic reconstructions.

Figure 5: Ablation illustrates degradation without pose initialization and tracking regularization.
Conclusion
PAD3R leverages generative and computational advancements to tackle limitations in dynamic 3D reconstruction from monocular videos. By integrating instance-specific camera pose estimation, generative priors, and advanced tracking methodologies, it offers a robust framework applicable to diverse real-world scenarios. Despite challenges in real-time processing and dependency on 2D tracking fidelity, PAD3R provides transformative insights into dynamic 3D reconstruction, setting a direction for future explorations into integrating motion priors from diffusion models.
References
Refer to the paper for detailed citations and acknowledgments regarding foundational works in differentiable rendering, dynamic radiance fields, and generative modeling incorporated into PAD3R.

