- The paper introduces a novel framework leveraging 3D Gaussian Splatting and motion-aware tracking for online dynamic scene reconstruction.
- It employs a motion mask prediction strategy that fuses optical flow residuals with semantic segmentation to disentangle static and dynamic regions.
- Experimental results demonstrate competitive camera tracking and high-quality novel view synthesis, outperforming several baseline SLAM methods.
Progressive Dynamic Scene Reconstruction via Gaussian Splatting from Monocular Videos
Introduction and Motivation
Dynamic scene reconstruction from monocular video is a critical capability for robotics, AR, and autonomous systems, requiring temporally consistent spatial understanding of both static and dynamic elements. Existing SLAM methods typically filter out dynamic content or require RGB-D input, while offline approaches are not scalable to long sequences and feedforward transformer-based methods lack global consistency and detailed appearance modeling. The ProDyG framework addresses these limitations by enabling online, globally consistent, and detailed dynamic scene reconstruction using 3D Gaussian Splatting (3DGS) from monocular RGB or RGB-D streams.

Figure 1: ProDyG robustly tracks the camera and progressively reconstructs static and dynamic scene components using 3D Gaussian Splatting from an online RGB stream.
System Architecture and Methodology
ProDyG integrates a motion-agnostic SLAM backend with a progressive dynamic reconstruction pipeline. The architecture leverages Splat-SLAM for robust camera tracking and introduces a novel motion mask prediction strategy, combining optical flow residuals and semantic segmentation via SAM2 to disentangle static and dynamic regions.
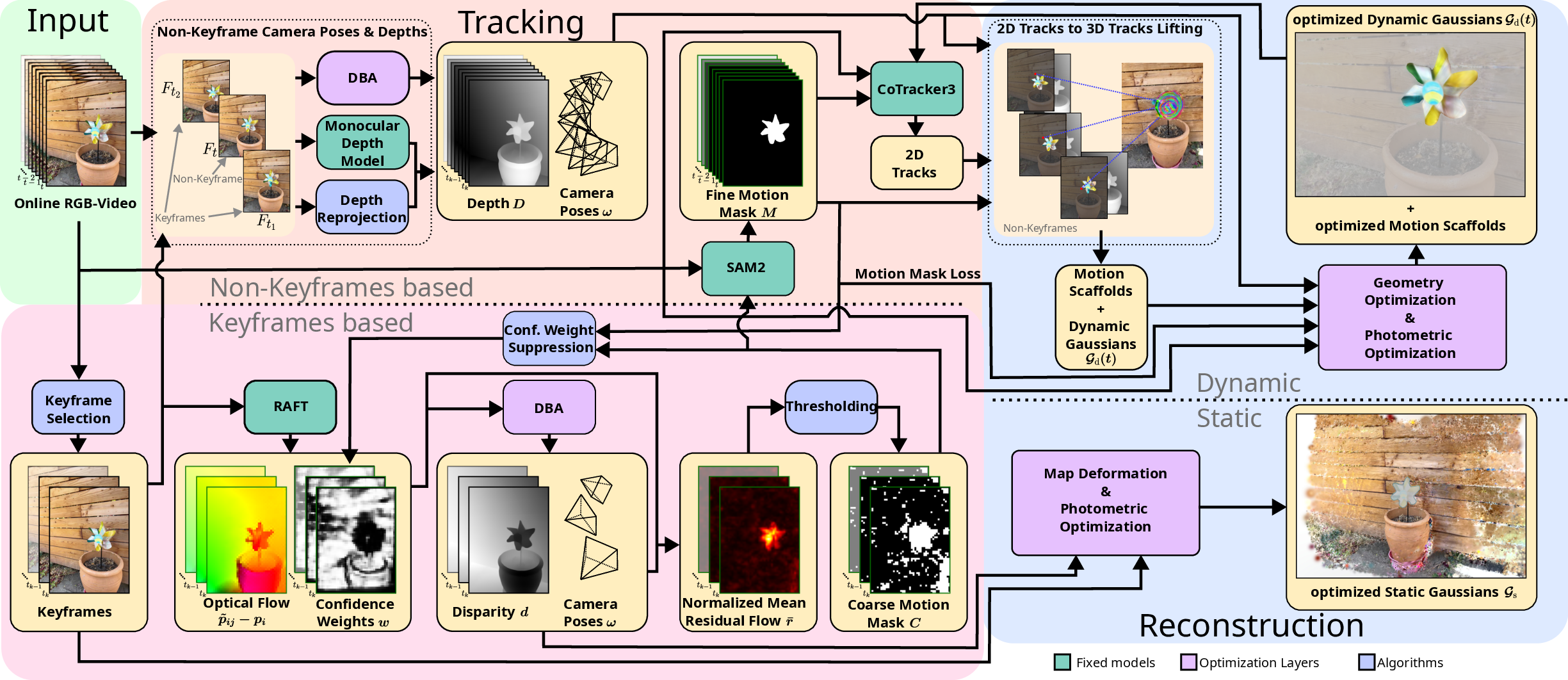
Figure 2: ProDyG architecture: motion-agnostic tracking, keyframe-based mask generation, and progressive reconstruction of static and dynamic Gaussians using Motion Scaffolds.
Motion-Agnostic Camera Tracking
Camera tracking is performed using Dense Bundle Adjustment (DBA) over a factor graph of keyframes, disparities, and optical flow. Coarse motion masks are generated by thresholding the normalized mean magnitude of residual flow, which isolates dynamic regions by subtracting camera-induced flow from estimated optical flow. These masks are refined using SAM2, which produces fine-grained semantic motion masks via point prompting at connected regions.




Figure 3: Semantic-guided motion mask refinement: residual flow magnitude, coarse mask, and fine mask generation using SAM2.
The fine motion masks are used to suppress dynamic distractors during pose optimization, improving robustness in dynamic environments. The mask threshold is adaptively tuned based on the dynamic pixel ratio, and segmentation validity is ensured by prompt candidate filtering.
Scene Representation: Static and Dynamic Gaussians
The scene is represented as a set of 3D Gaussians, partitioned into static and dynamic components. Each Gaussian is parameterized by mean, rotation, scale, opacity, and color. Rendering is performed by projecting 3D Gaussians onto the image plane and compositing color, depth, and opacity using the 3DGS pipeline and RaDe-GS rasterizer.
Progressive Dynamic Reconstruction
Dynamic regions are reconstructed using Motion Scaffolds, a graph-based representation encoding per-timestep rigid transformations for each dynamic region. Dense 2D pixel trajectories are generated via CoTracker3 and lifted to 3D using estimated poses and depth maps. Motion Scaffolds are initialized from these tracks and optimized for geometric and photometric consistency using ARAP, velocity, acceleration, RGB, depth, and track losses. A novel motion mask loss penalizes dynamic Gaussian opacity in static regions, enforcing clean separation.
As new frames arrive, dynamic reconstruction is extended by tracking recently visible and newly-seen dynamic regions, lifting new tracks to 3D, and warping them for temporal consistency using Dual Quaternion Blending. Dynamic Gaussians are initialized at newly-seen pixels and jointly optimized with the expanded Motion Scaffolds.
Experimental Results
Camera Tracking
ProDyG achieves competitive tracking performance on the Bonn RGB-D Dynamic and TUM RGB-D datasets, outperforming the Splat-SLAM baseline and most RGB-D and RGB SLAM methods. The only method with superior tracking is WildGS-SLAM, which uses a test-time-optimized MLP for uncertainty masking and reconstructs only static backgrounds, allowing more aggressive suppression of dynamic distractors. ProDyG, in contrast, reconstructs globally consistent dynamic models and requires precise mask boundaries.
Novel View Synthesis
ProDyG demonstrates strong novel view synthesis (NVS) results on the iPhone dataset, outperforming the offline Shape of Motion method in PSNR and SSIM while operating fully online. Compared to MoSca, an offline method with similar motion field representation, ProDyG shows only minor disadvantages when using RGB-D input. ProDyG is the only method capable of online dynamic reconstruction and tracking from monocular RGB input, maintaining reasonable NVS quality even without depth.










Figure 4: Qualitative novel view synthesis results on iPhone: ProDyG yields accurate dynamic object silhouettes and high-quality renderings, outperforming online and offline baselines.
Limitations and Future Directions
ProDyG's dynamic representation is challenged by objects that move outside the viewing frustum and reappear, due to insufficient photometric constraints for Motion Scaffolds, leading to regularization-dominated optimization and potential deformations. The system requires per-scene test-time optimization, limiting real-time applicability. Handling large viewpoint changes remains difficult, suggesting the need for generative models or data-driven priors to hallucinate unseen regions. These limitations are shared with other monocular dynamic view synthesis methods and highlight directions for future research.
Conclusion
ProDyG establishes a robust framework for online, globally consistent dynamic scene reconstruction from monocular video, integrating motion-agnostic tracking, semantic-guided mask refinement, and progressive dynamic mapping via Motion Scaffolds and 3D Gaussian Splatting. The method achieves competitive tracking and novel view synthesis performance, supports both RGB and RGB-D input, and is the first to enable high-quality online dynamic reconstruction from monocular streams. Future work should address real-time optimization, occlusion handling, and generative completion for unseen regions to further advance dynamic scene understanding in practical applications.

