- The paper presents a dual-phase framework where an explorer generates multiple reasoning paths and a synthesizer integrates them.
- The A2R framework achieves a 75% performance improvement over self-consistency baseline while reducing costs by 30%.
- The study demonstrates enhanced training stability through on-policy updates and precise temperature control to manage entropy.
A2R: An Asymmetric Two-Stage Reasoning Framework for Parallel Reasoning
Introduction
The paper "A2R: An Asymmetric Two-Stage Reasoning Framework for Parallel Reasoning" (2509.22044) introduces a novel framework designed to enhance the reasoning capabilities of LLMs. The Asymmetric Two-Stage Reasoning (A2R) framework addresses the disparity between the latent potential of LLMs and their performance in single-attempt reasoning tasks. This framework leverages parallel reasoning to bridge the gap between a model's prowess across multiple solution pathways and its typical single-pass performance.
Two-Stage Reasoning Framework
The A2R framework is predicated on a dual-phase approach: exploration and synthesis. Initially, the "explorer" model generates multiple reasoning paths in parallel by employing repeated sampling. This parallel approach circumvents the traditional sequential computation limitations and scales reasoning vertically compared to existing methodologies. Subsequently, a "synthesizer" model integrates the generated paths in a refined second stage of reasoning.
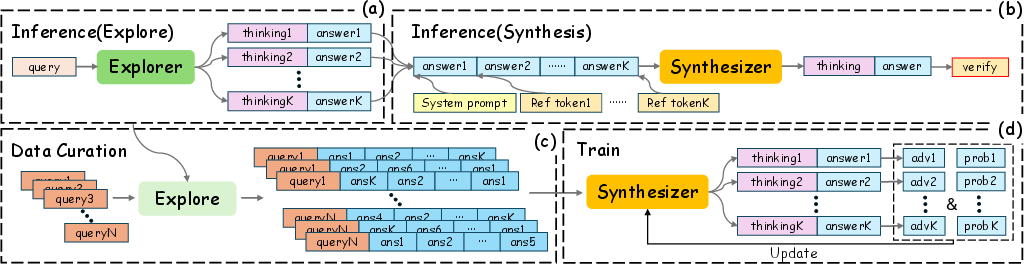
Figure 1: Overview of the A2R framework, illustrating the generation of multiple reasoning traces and candidate solutions.
Innovations and Methodology
A2R is introduced as a plug-and-play framework to improve model performance on complex reasoning tasks. The framework boasts a performance improvement of 75% when compared to a model's baseline self-consistency. Furthermore, a systematic exploration of the explorer and synthesizer roles reveals an efficacious asymmetric scaling paradigm, defined by a "small-to-big" model variant. This configuration, combining a smaller explorer with a larger synthesizer, surpasses the performance of a monolithic model while incurring approximately 30% lower costs.
Experimentation and Results
Experiments conducted on complex reasoning benchmarks such as AIME 2024, AIME 2025, and BeyondAIME demonstrate the effectiveness of A2R. The framework achieves substantial gains, underscoring its potential in real-world applications that require robust and efficient reasoning mechanisms.
The results indicate a strong positive correlation between the capacity of the synthesizer and the resulting performance improvements. This insight paved the way for creating A2R-Efficient, which leverages a smaller explorer paired with a larger, reinforcement learning-fine-tuned synthesizer.
On-Policy Optimization
The study explored on-policy versus off-policy updates to optimize the synthesis phase with reinforcement learning, enhancing the synthesizer's capacity to critically evaluate candidate solutions. The on-policy approach ensures stable training dynamics and superior results by performing updates fully on-policy.
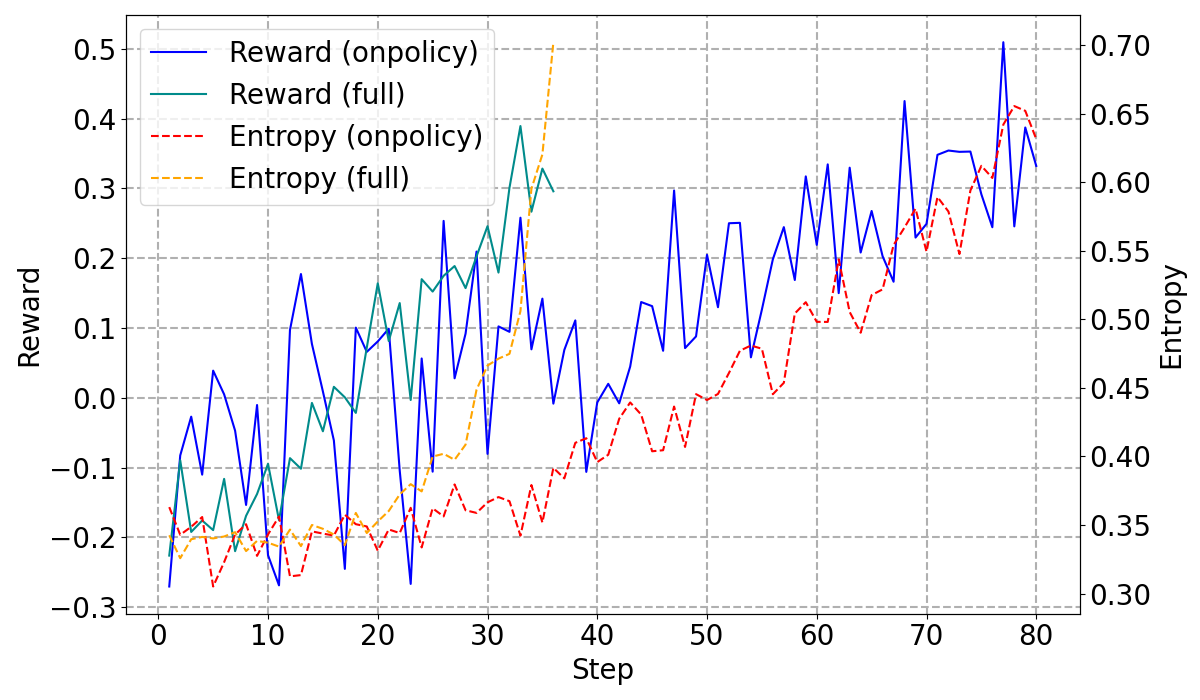
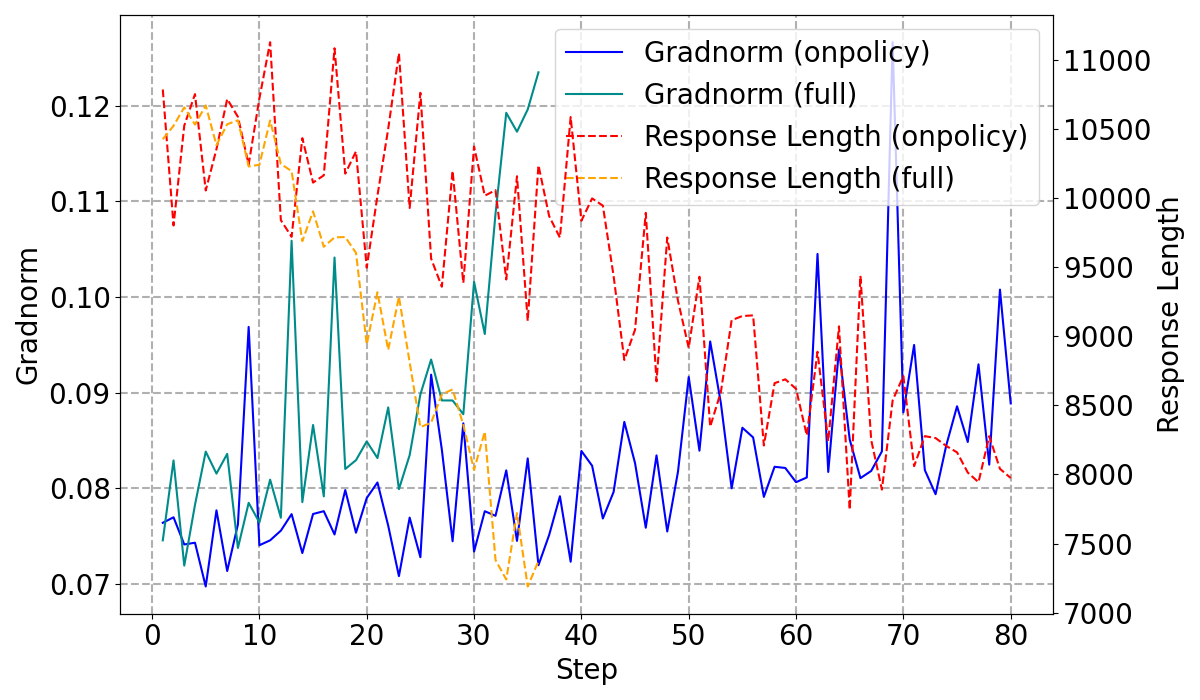
Figure 2: On-Policy vs. Off-Policy Training Dynamics, highlighting the stability offered by on-policy updates.
Temperature Control for Entropy Management
A crucial aspect of the training stability involves controlling the policy entropy via temperature adjustments. Lowering the temperature to 0.7 stabilizes entropy, yielding higher performance bounds and reduced training instability.
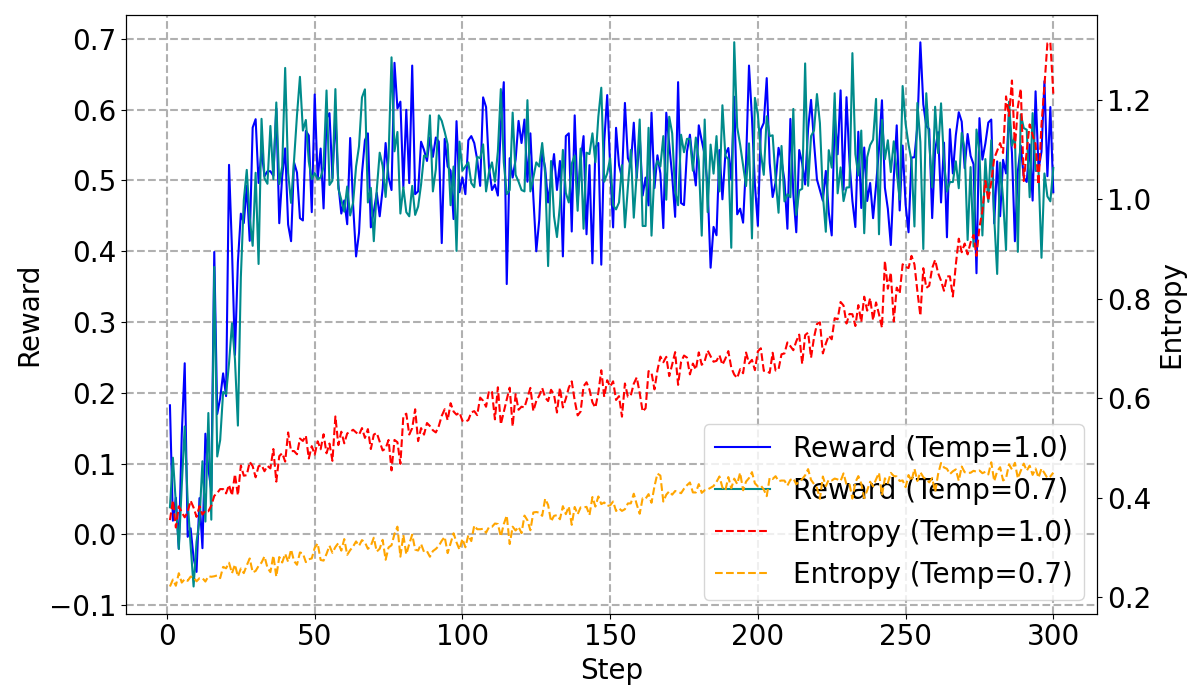
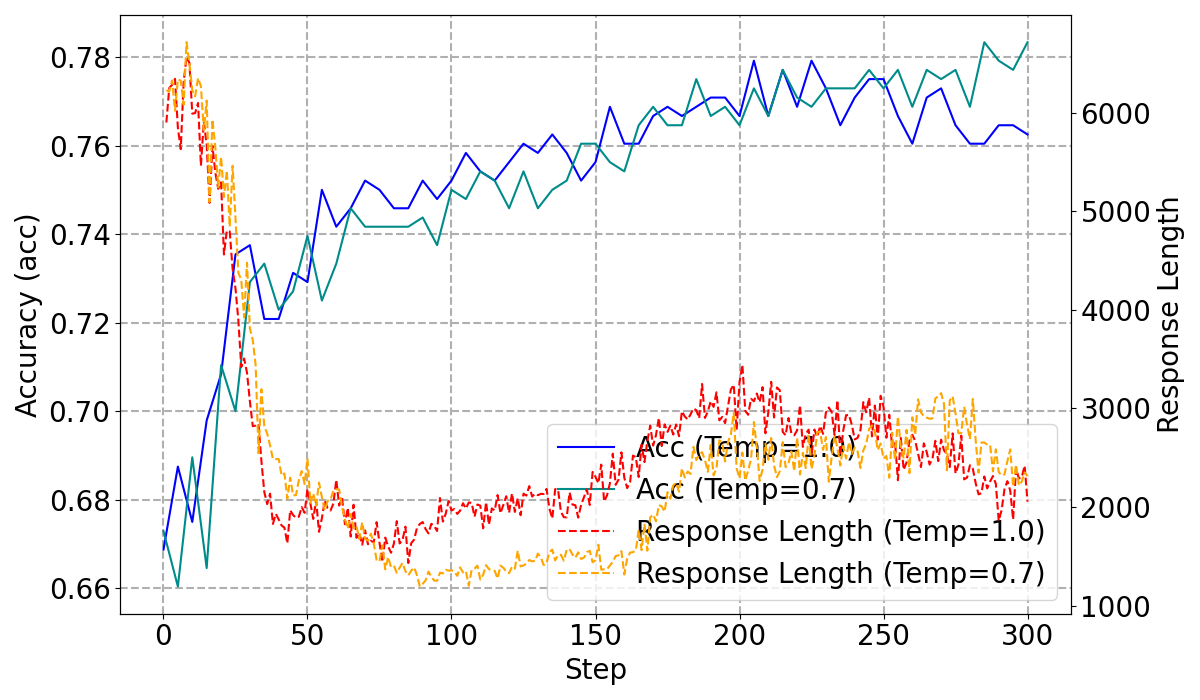
Figure 3: High-Temperature vs. Low-Temperature Training Dynamics, demonstrating the stabilized training process at lower temperatures.
Conclusion
The Asymmetric Two-Stage Reasoning framework, A2R, bridges the performance gap in LLMs by dividing the reasoning process into complementary phases of exploration and synthesis. Through A2R, LLMs can achieve their latent potential more reliably, providing efficient and enhanced computation strategies for complex reasoning tasks. The proposed asymmetric architecture establishes a principled method for reasoning augmentations, effectively optimizing computational resource allocation while delivering high performance with reduced costs. The insights presented pave the way for further developments in efficient AI reasoning methodologies, with implications for practical applications across various domains.