DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Abstract: General reasoning represents a long-standing and formidable challenge in artificial intelligence. Recent breakthroughs, exemplified by LLMs and chain-of-thought prompting, have achieved considerable success on foundational reasoning tasks. However, this success is heavily contingent upon extensive human-annotated demonstrations, and models' capabilities are still insufficient for more complex problems. Here we show that the reasoning abilities of LLMs can be incentivized through pure reinforcement learning (RL), obviating the need for human-labeled reasoning trajectories. The proposed RL framework facilitates the emergent development of advanced reasoning patterns, such as self-reflection, verification, and dynamic strategy adaptation. Consequently, the trained model achieves superior performance on verifiable tasks such as mathematics, coding competitions, and STEM fields, surpassing its counterparts trained via conventional supervised learning on human demonstrations. Moreover, the emergent reasoning patterns exhibited by these large-scale models can be systematically harnessed to guide and enhance the reasoning capabilities of smaller models.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces two new AI models that are good at “thinking through” problems:
- DeepSeek-R1-Zero
- DeepSeek-R1
The main idea is to teach LLMs to reason better using reinforcement learning (RL)—a training method where the model tries things, gets rewarded for good behavior, and learns from that. The authors show that a model can learn powerful reasoning skills even without lots of human-written examples, and then improve readability and general usefulness with a small amount of carefully chosen data.
What questions are the researchers trying to answer?
The paper explores three simple questions:
- Can an AI learn strong reasoning skills using only reinforcement learning, without first being taught with human-made examples?
- If we add a small amount of high-quality “starter” examples, can we make the AI’s reasoning clearer, more readable, and even better?
- Can we “teach” smaller, cheaper models to reason well by training them on the outputs of a larger reasoning model?
How did they train the models? (Methods explained simply)
Think of training the AI like coaching a student through practice problems:
- Reinforcement Learning (RL): The model tries to solve problems (like math or coding). If it gets the answer right or follows the rules (like writing its “thinking” in a certain format), it earns points (rewards). Over time, it learns better ways to think and solve.
- Accuracy rewards: Points for getting the final answer right.
- Format rewards: Points for writing its reasoning in a clear structure, like putting the thinking between
> ...and the final result between<answer> ... </answer>.
- Group Relative Policy Optimization (GRPO): Imagine a group of attempts for the same question. Instead of hiring a separate “judge” model, the AI compares its own group of answers and learns from which ones scored better. This saves training cost but still teaches it which strategies work.
- DeepSeek-R1-Zero (pure RL): The model starts with no special human examples. It just practices a lot with RL and learns reasoning by itself. It becomes very good but sometimes writes in a messy way (mixing languages, hard to read).
- DeepSeek-R1 (multi-stage training): To fix the messy writing and improve general skills, they add a small “cold start” stage:
- Cold-start fine-tuning: A small set of human-friendly examples of long, clear reasoning. This helps the model learn a readable style.
- RL focused on reasoning: More practice on math, coding, science, and logic with rewards for accuracy and language consistency (keep the reasoning in the right language).
- Rejection sampling + supervised fine-tuning (SFT): They generate many solutions, keep the good ones, and also add data for general tasks like writing and Q&A. Then they train again to make the model helpful and coherent.
- RL for all scenarios: Final polishing with rewards that balance being helpful, safe, and still strong at reasoning.
Distillation (teaching smaller models): The big model (DeepSeek-R1) generates lots of good reasoning examples. Smaller models (like Qwen and Llama versions) are trained on those examples to “learn the style” and become much better at reasoning without expensive RL. This is like learning from a top student’s solved practice papers.
What did they find?
Here are the most important results and why they matter:
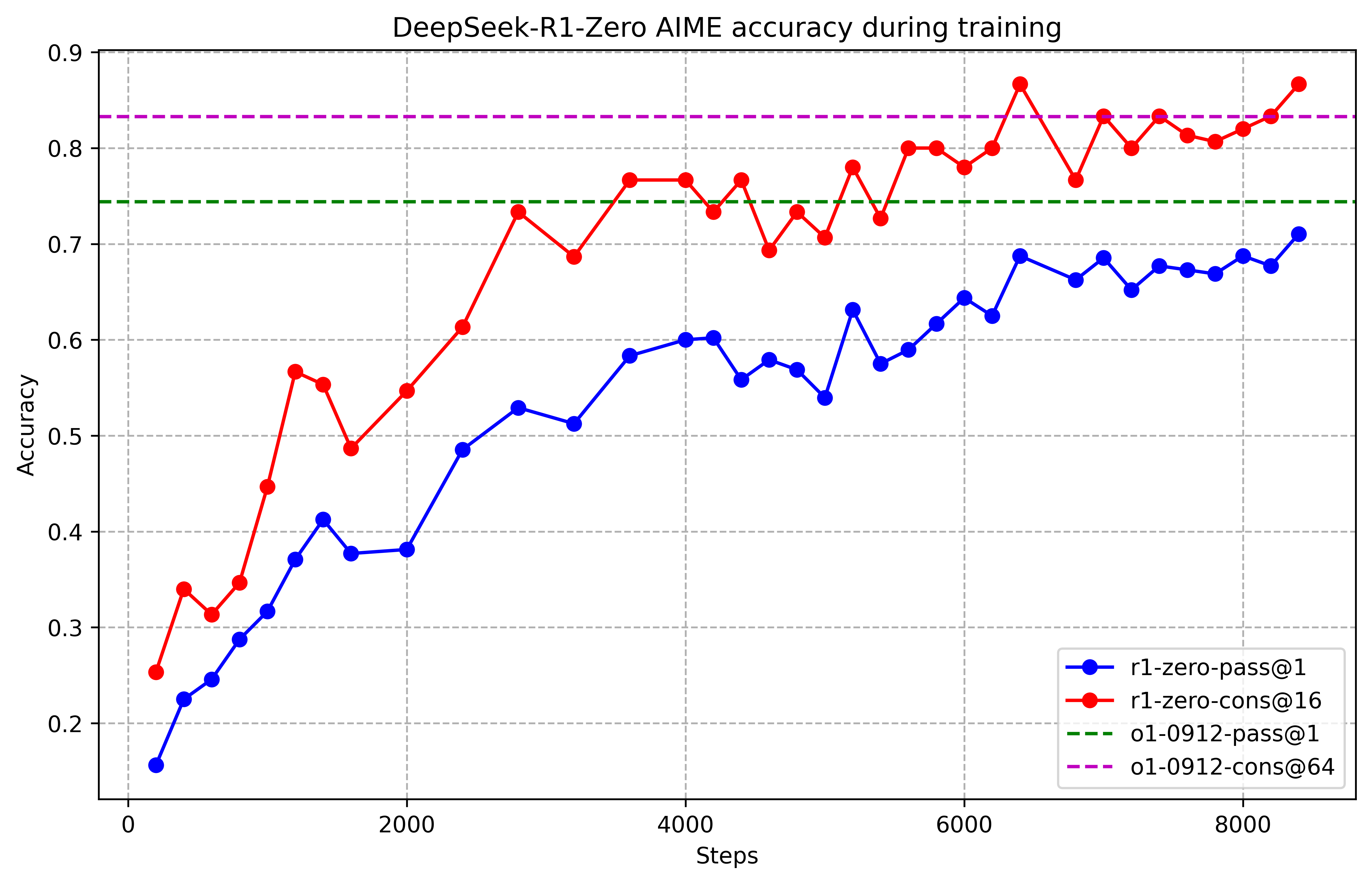
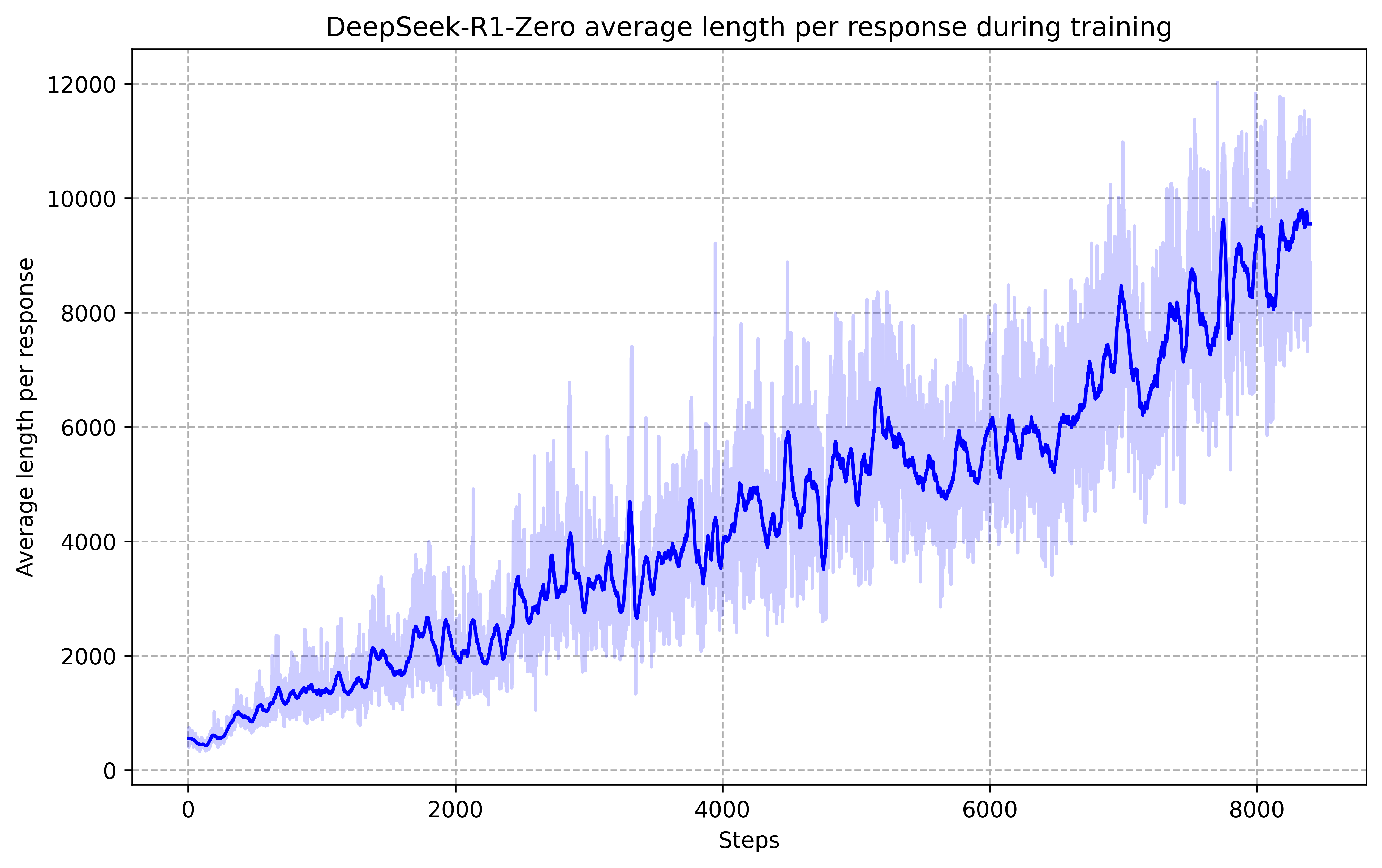
- Pure RL works: DeepSeek-R1-Zero learned strong reasoning without any human-labeled training. For example, on a hard math test (AIME 2024), it improved from about 16% to 71% accuracy, and up to 86.7% with majority voting (picking the most common answer from many tries). It also started “thinking longer” on tough problems and developed behaviors like checking its own work—almost like a natural “aha moment.”
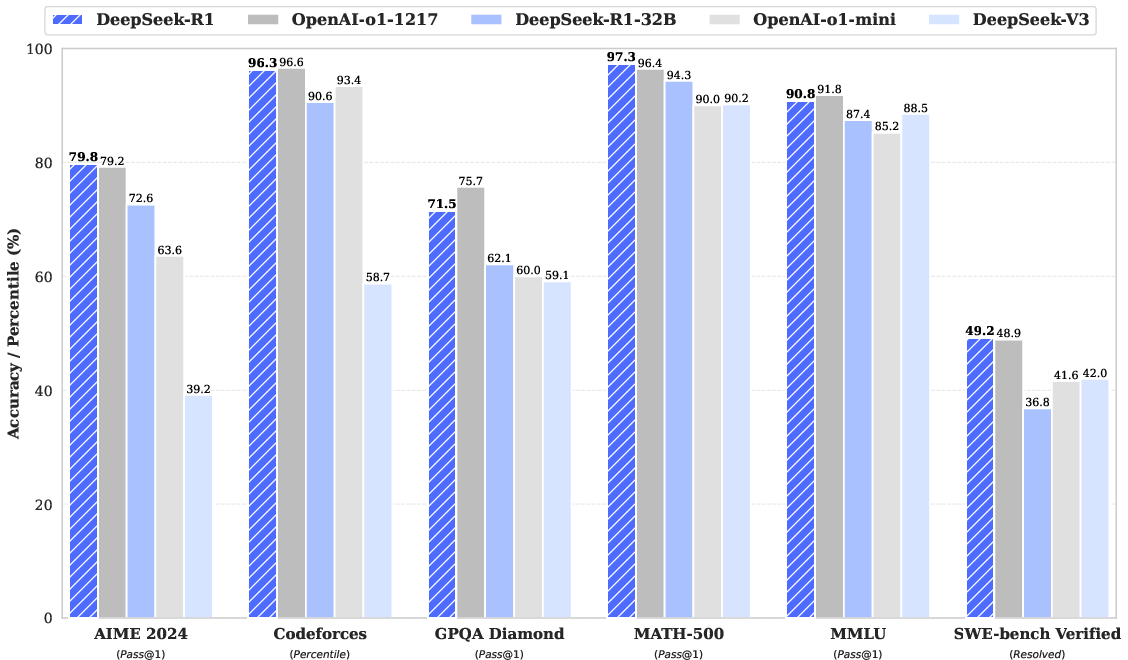
- Readability and general skills improve with a small cold start: DeepSeek-R1 (with a little curated training data before RL) became both smarter and easier to understand—cleaner reasoning, fewer language mix-ups, and better summaries. It reached performance close to OpenAI’s o1-1217 on math and coding and stayed competitive on knowledge tests.
- Strong benchmark performance:
- Math: DeepSeek-R1 scored around 79.8% on AIME 2024 and 97.3% on MATH-500—among the best.
- Coding: On Codeforces (a real competitive programming platform), it reached a rating of 2029, higher than about 96% of human competitors tested in that slice.
- Knowledge and writing: It did very well on exams like MMLU and in writing tests (AlpacaEval and ArenaHard), showing it’s not only good at math but also at general tasks.
- Distillation makes small models powerful:
- Smaller models trained on DeepSeek-R1’s outputs became strong reasoners. For example, a 14B distilled model beat a well-known 32B open-source model (QwQ-32B-Preview) on key benchmarks.
- The 32B and 70B distilled models reached near state-of-the-art results among dense (non-MoE) open models.
- Practical lessons:
- Reward models judging the “process” can cause “reward hacking” (the model learns to game the scoring rather than truly reason), so the authors leaned on rule-based checks and careful training.
- Search-based methods like MCTS (used in games like Go) didn’t scale well for language reasoning because the “search space” of text is too big and hard to measure step-by-step.
Why does this matter?
- RL can teach AI to reason: This shows that an AI can develop complex reasoning skills by practicing and getting feedback, even without huge sets of human-annotated examples.
- Clearer, safer, more helpful AI: With a small amount of human guidance and careful rewards, the model’s thinking becomes readable and aligned with what users want.
- Better, cheaper models for everyone: Distillation means strong reasoning can be shared with smaller models that are cheaper to run, helping researchers, students, and developers.
- Open-source impact: The authors released models and checkpoints (from 1.5B up to 70B) so the community can build on this work.
Simple takeaways and future impact
- You can teach a model to think better just by rewarding it for good problem-solving and clear explanations.
- Adding a small starter set of good examples makes the model’s thinking easier to read and improves general usefulness.
- Big models can “teach” small models, spreading advanced reasoning more widely.
- This approach could improve AI tutors, coding assistants, math solvers, research helpers, and any tool that benefits from careful, step-by-step thinking.
- Future models may push reasoning further by combining smarter RL strategies, better reward design, and improved safety and clarity—bringing AI closer to truly reliable, general problem-solving.
Collections
Sign up for free to add this paper to one or more collections.