- The paper presents a two-stage architecture that uses native parallel reasoning and summarization to enhance LLM performance, improving accuracy by up to 12.3% for 1.5B models.
- The methodology employs specialized control tokens and thought embeddings to generate diverse reasoning paths, effectively mitigating the tunnel vision effect.
- Experimental results on benchmarks such as AIME 2024 demonstrate improved interpretative capabilities with minimal latency overhead, ensuring efficient scaling of LLM test-time compute.
ParaThinker: Native Parallel Thinking as a New Paradigm to Scale LLM Test-time Compute
Introduction to the ParaThinker Framework
The paper on "ParaThinker: Native Parallel Thinking as a New Paradigm to Scale LLM Test-time Compute" introduces a novel methodology for enhancing the computational scalability of LLMs at test time by leveraging native parallel reasoning. The motivation behind this work is to overcome the limitations imposed by existing sequential reasoning strategies that often lead to diminishing returns in performance improvements despite increased computational resources, a situation described as the "Tunnel Vision" problem.
ParaThinker proposes a framework that enables the generation and integration of multiple reasoning paths in parallel, effectively circumventing Tunnel Vision and unlocking greater reasoning potential in LLMs. This approach offers substantial performance improvements in reasoning tasks while maintaining computational efficiency.
Understanding the Scaling Bottleneck
The core limitation of current LLM test-time scaling methods is the sequential nature of reasoning, which can lock the model into suboptimal paths. This is referred to as "Tunnel Vision," where initial reasoning steps commit the model to a particular line of thought, hindering its ability to explore alternative, potentially more effective reasoning paths.
The study demonstrates that the test-time scaling bottleneck is not an intrinsic limitation of model capabilities but rather a consequence of the sequential reasoning strategy. This inefficiency is illustrated by the plateau in performance gains as additional computation is allocated to a single reasoning path (Figure 1).
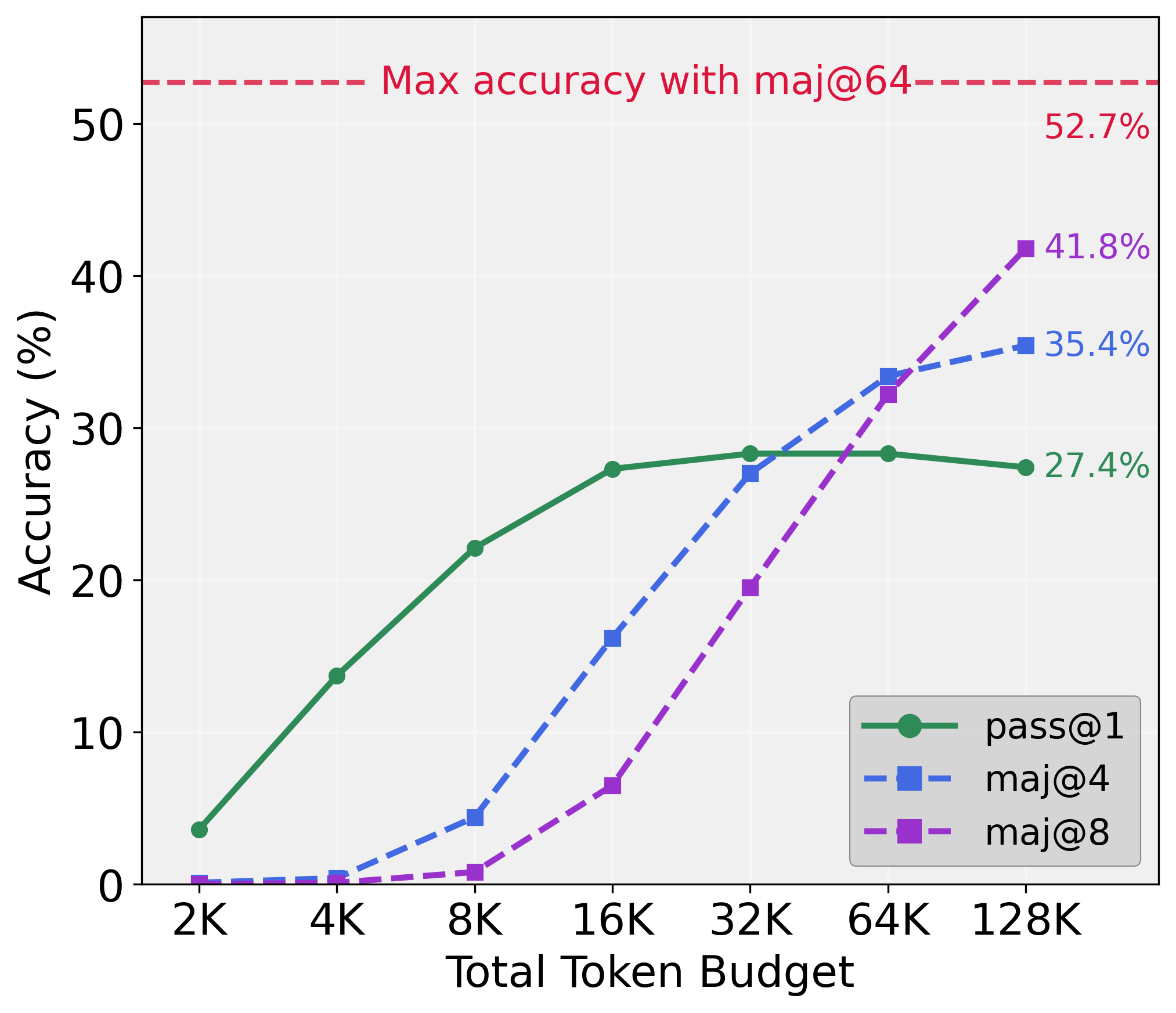
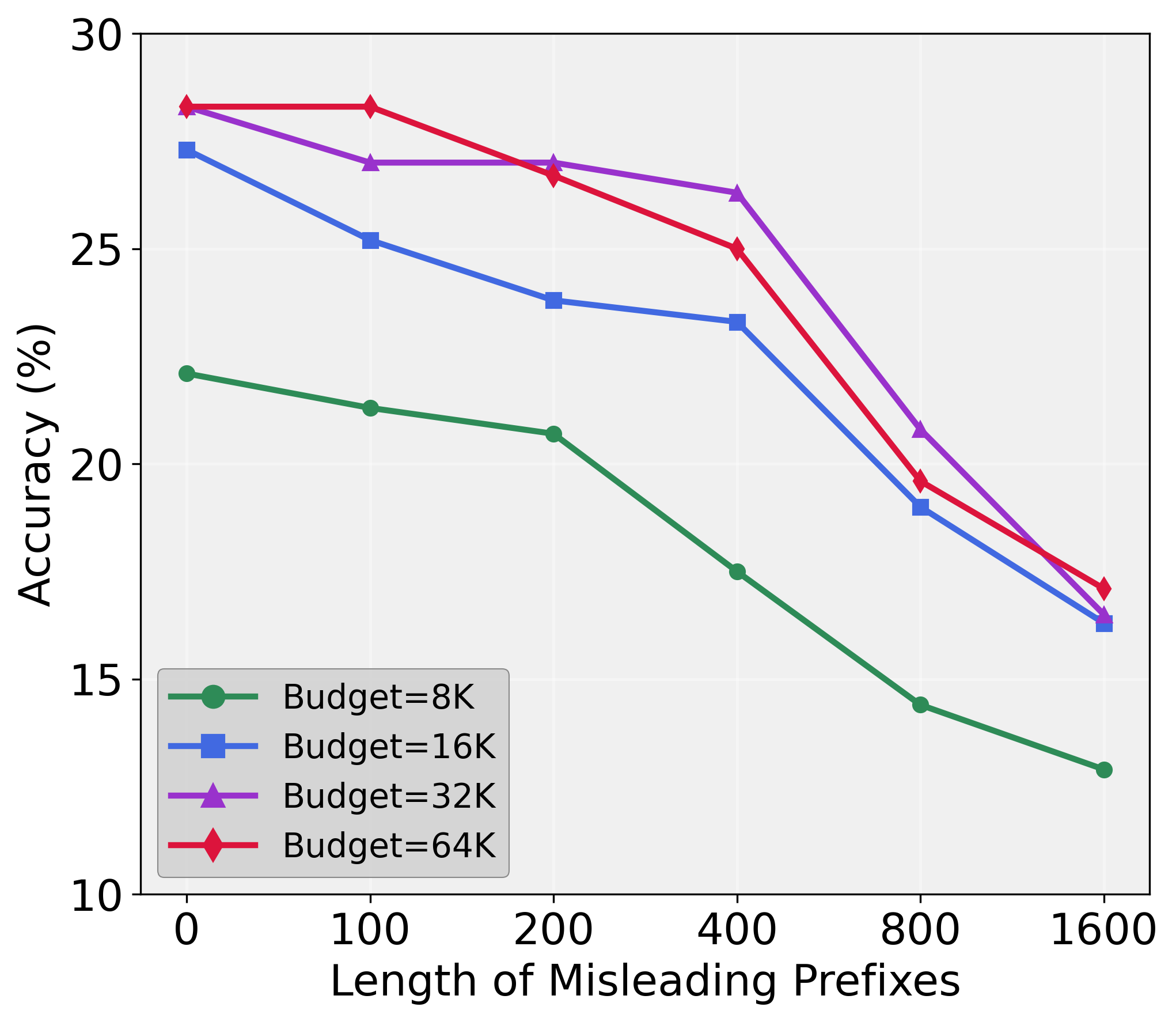
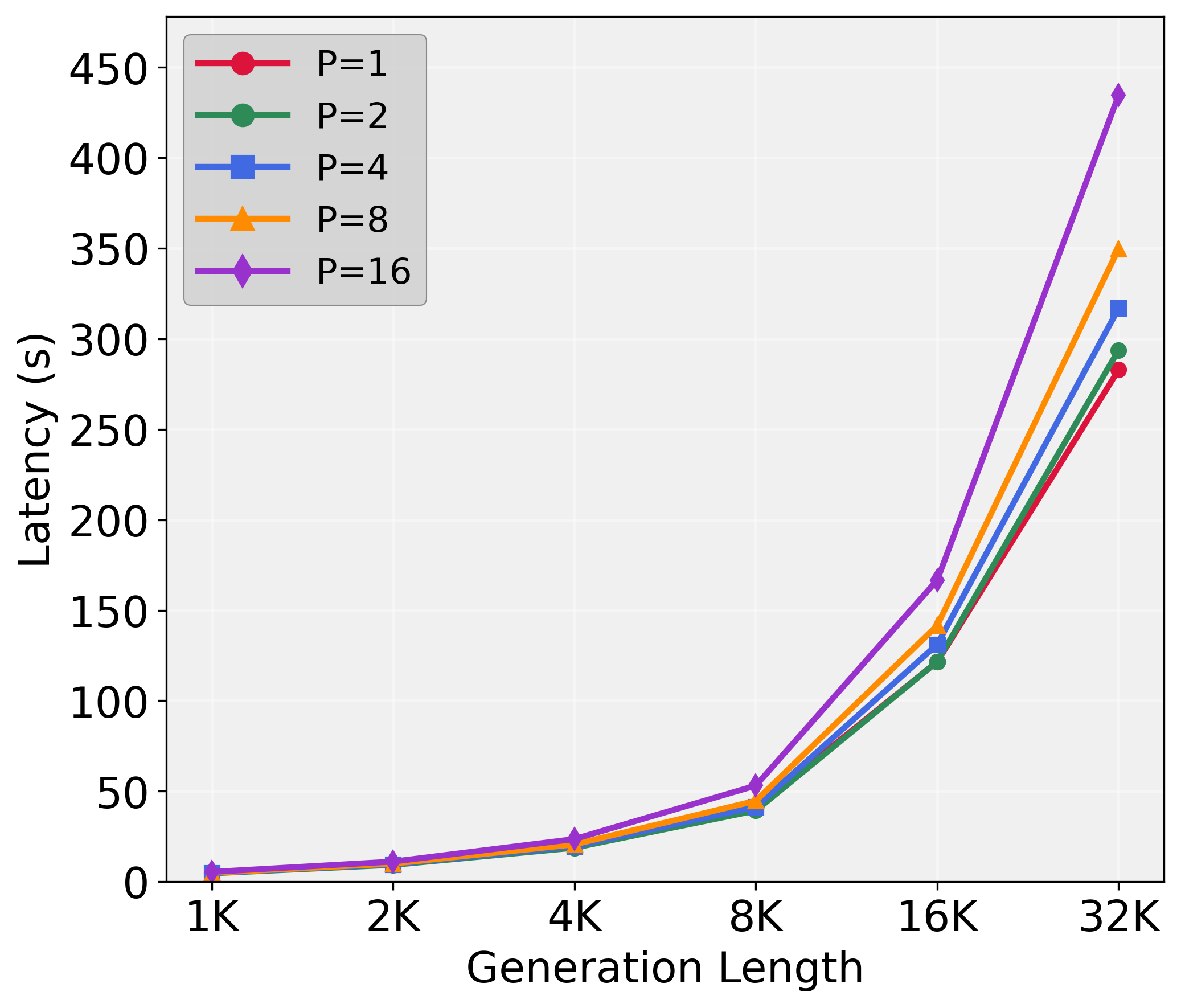
Figure 1: Scaling Bottleneck.
ParaThinker: Parallel Reasoning and Summarization
ParaThinker introduces a two-stage architecture that emphasizes parallel reasoning and summarization (Figure 2). In the first stage, the model simultaneously generates multiple reasoning paths, each guided by unique control tokens to promote diverse thought processes. Thought embeddings are used to differentiate the paths and prevent positional ambiguity.
In the second stage, these parallel paths are synthesized into a coherent final answer. This is achieved by reusing the Key-Value caches from the reasoning stage, thereby avoiding the need for costly re-prefilling.
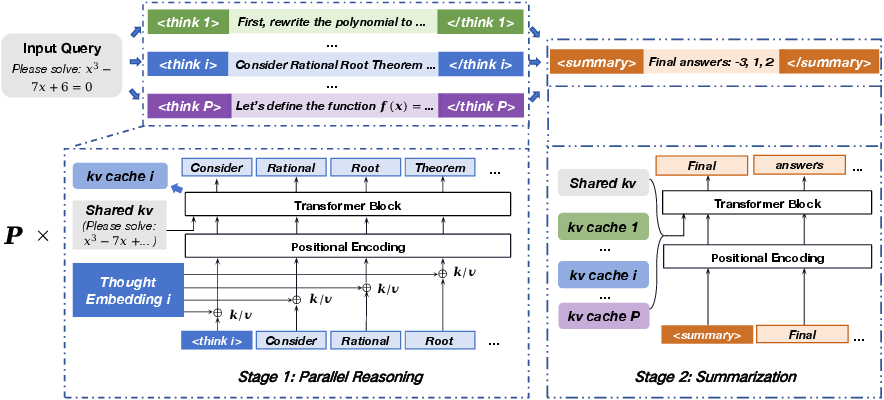
Figure 2: ParaThinker architecture.
On challenging reasoning benchmarks such as AIME 2024, ParaThinker exhibits significant accuracy improvements over traditional sequential approaches. Specifically, it achieves an average accuracy improvement of 12.3% for 1.5B models and 7.5% for 7B models when deploying eight parallel reasoning paths. Notably, this is accomplished with minimal latency overhead, demonstrating the efficiency of parallel inference.
The method utilizes specialized control tokens to trigger diverse thought processes which, coupled with the summarization mechanism, yield a robust strategy for aggregating multiple reasoning trajectories. This enhances the interpretative capabilities of smaller models, allowing them to surpass the performance of much larger counterparts.
Inference Efficiency and Trade-offs
ParaThinker offers substantial improvements in inference efficiency, as illustrated by its ability to generate reasoning paths in parallel without a linear increase in latency (Figure 3). This efficiency is attributed to better memory bandwidth utilization and higher arithmetic intensity, crucial for handling multiple concurrent processing threads.
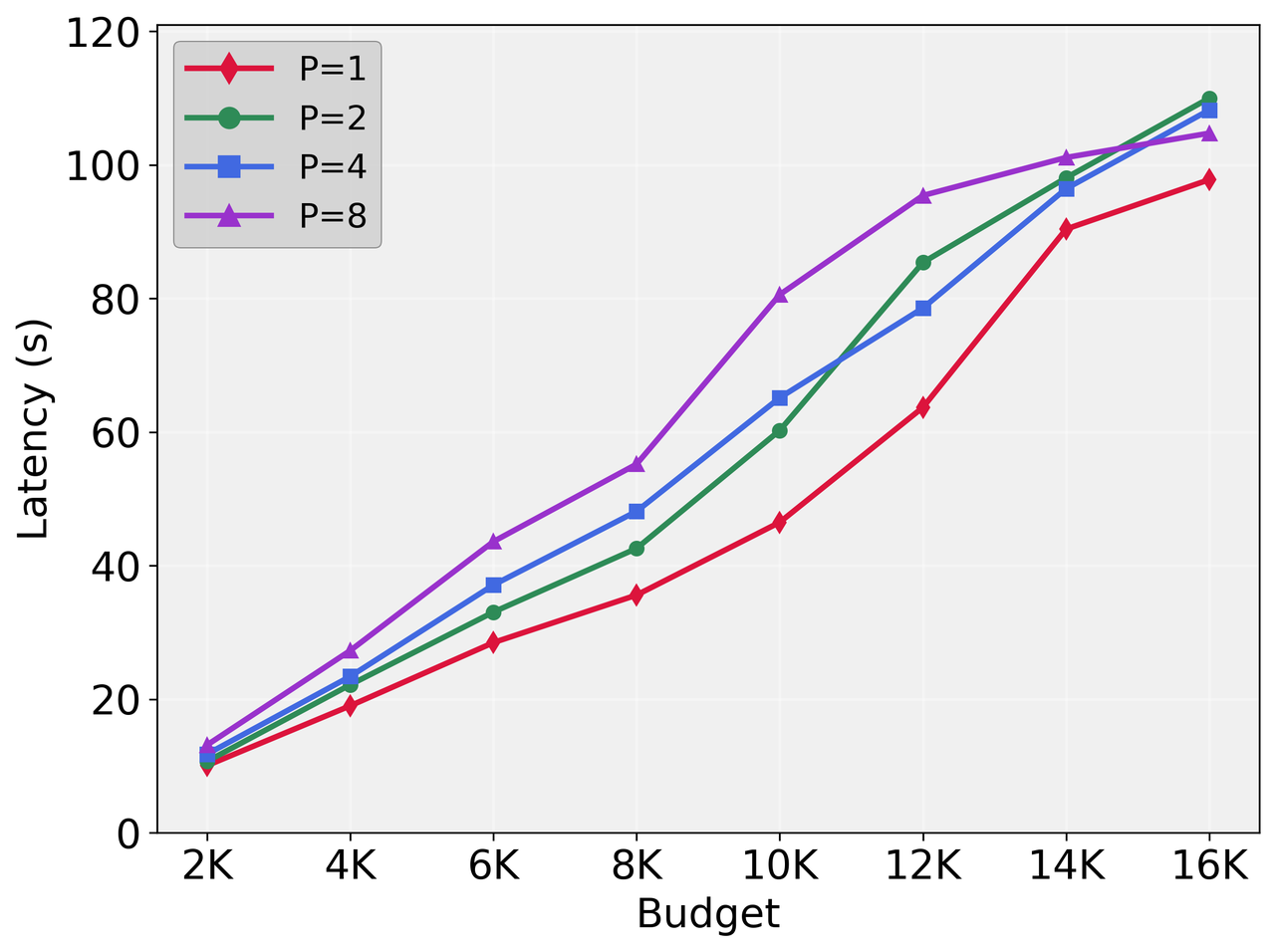
Figure 3: Total latency of ParaThinker-1.5B with different numbers of parallel paths.
Conclusion
ParaThinker establishes a compelling case for embracing native parallel reasoning as an effective paradigm to scale LLM test-time compute. By addressing the limitations of sequential processing and enabling the integration of diverse reasoning paths, ParaThinker sets a precedent for future developments in efficient and scalable LLM architectures. This paradigm shift towards parallelism highlights the potential for LLMs to achieve superior reasoning capabilities without proportionally increasing computational resources. Future work may explore advanced aggregation strategies and reinforcement learning techniques to further expand the applicability and effectiveness of native parallel thinking in AI systems.

