- The paper introduces a reward-guided tree search framework that enhances reasoning in LLMs for mathematical tasks.
- It integrates policy models, reward feedback, and Monte Carlo Tree Search to optimize exploration of reasoning paths.
- Experimental evaluations on multiple benchmarks show significant improvements in reasoning accuracy over baseline methods.
Enhancing LLM Reasoning with Reward-guided Tree Search
The paper discusses a framework that improves reasoning in LLMs using a reward-guided tree search mechanism. This approach offers a structured method to expand the reasoning capabilities of LLMs by leveraging search algorithms, a carefully designed reward model, and a policy model. The study concentrates on mathematical reasoning tasks, evaluating the framework on multiple challenging datasets.
Introduction
Advancements in LLMs have significantly improved their capabilities across various domains. However, they still face challenges in complex reasoning tasks prevalent in STEM fields. The paper introduces a framework integrating a policy model, a reward model, and a search algorithm centered around tree search to enhance reasoning. This approach allows LLMs to explore reasoning spaces more comprehensively by guiding the policy model through reward feedback within a tree structure.
Methodology
The framework consists of three parts:
- Policy Model: The LLM adapts to tree-structured reasoning formats through supervised instruction tuning. Data synthesized from a high-capacity LLM refines the reasoning process of the policy model under a reward-guided mechanism.
- Reward Model: The reward model evaluates reasoning paths to guide the policy model. It employs outcome-supervised, generative, and scoring-based methodologies to provide feedback critical for enhancing reasoning trajectories.
- Search Algorithm: Employing Monte Carlo Tree Search (MCTS), the model navigates dynamically through reasoning spaces, balancing exploration and exploitation. Enhancement strategies, such as pre-expansion and self-consistency checks, optimize search performance.
Experimental Evaluation
The framework was tested on four benchmarks: MATH-OAI, GSM-Hard, Olympiad Bench, and College Math. Results demonstrate notable improvements over baseline methods, particularly in reasoning accuracy. The iterative refinement of both the policy and reward models through selection strategies resulted in mutual enhancement, confirming the effectiveness of the framework.
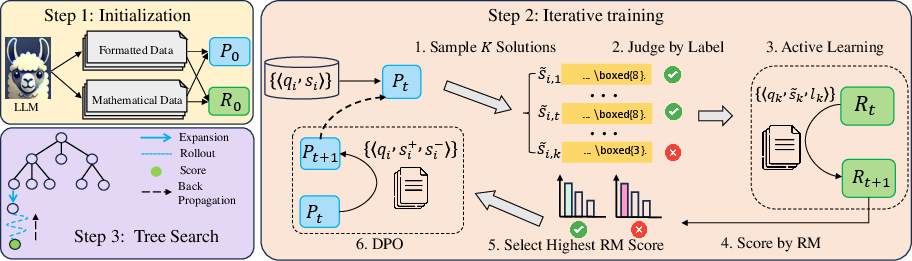
Figure 1: An overview of the implemented reasoning framework in this work.
Detailed Analysis
Policy Model Analysis
Data synthesis from high-capacity LLMs significantly improved model adaptation to the reasoning format. The adequacy and quality of synthetic data from domain-specific and general-purpose models were critical. Policy model training with optimized preference data further enhanced reasoning accuracy, verified through diverse reasoning paths generated during test phases.
Reward Model Design
Implementing an outcome-supervised, generative model proved effective in both outcome-level and step-level supervision. Active learning strategies allowed the model to discern significant positive and negative samples, crucial for training efficacy. Various design considerations, such as discriminative versus generative approaches and ranking-based versus scoring-based models, were explored to optimize feedback quality.
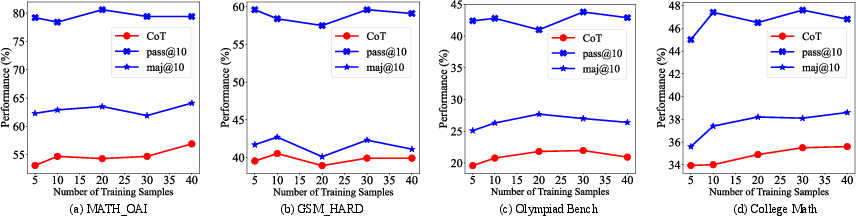
Figure 2: Performance of policy model on four benchmarks by using different amounts of training data for reasoning format adaptation. ``CoT'' means the CoT generation with greedy search.
Search Algorithm Optimization
The choice of search algorithm significantly impacted reasoning performance. MCTS and its variant MCTSG were particularly effective due to their exploration capabilities. The integration of self-consistency mechanisms and domain-specific tools, such as calculators for error checks, helped in maintaining logical consistency in the reasoning paths.
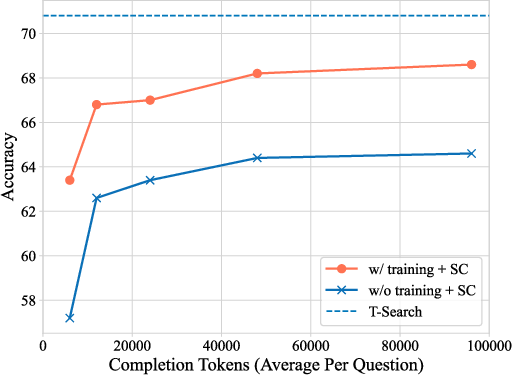
Figure 3: Self-consistency results with and without optimization using our training method.
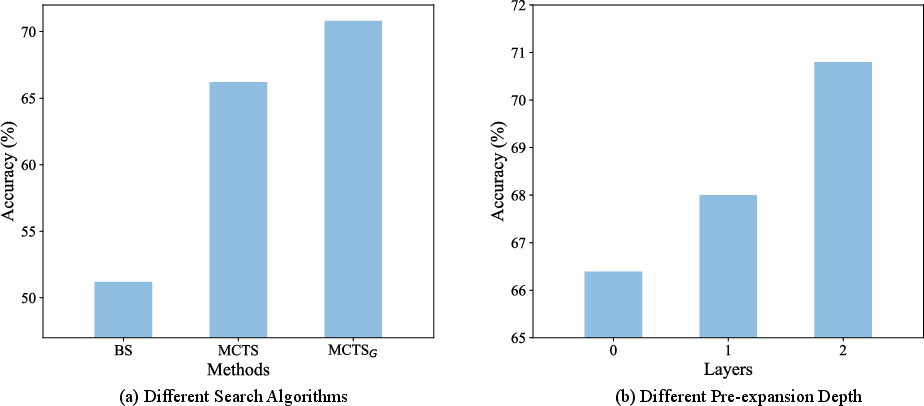
Figure 4: Effect of search algorithms and pre-expansion depth on model performance.
Conclusion
The reward-guided tree search framework offers a structured way to enhance reasoning in LLMs. By integrating advanced training, analysis, and search capabilities, this framework successfully addresses complex reasoning challenges in mathematical domains. Future work should focus on refining this framework to extend its applicability and efficiency in real-world reasoning tasks while further exploring scalable strategies for LLM refinement.

