- The paper introduces Adaptive Parallel Reasoning (APR) that dynamically balances serial and parallel computations using reinforcement learning.
- It demonstrates superior scalability and efficiency on the Countdown task by optimizing context window usage and reducing latency.
- The APR framework leverages hybrid search trajectories and dynamic resource allocation to enhance language model reasoning performance.
Overview of Learning Adaptive Parallel Reasoning with LLMs
This essay analyzes the paper "Learning Adaptive Parallel Reasoning with LLMs" (2504.15466), which introduces Adaptive Parallel Reasoning (APR), a framework designed to circumvent the limitations of traditional serial and parallel reasoning approaches in LLMs. APR strategically distributes inference-time computations across both serial and parallel threads, utilizing reinforcement learning to optimize these processes. Through comprehensive experiments on the Countdown task, the paper demonstrates APR’s superior effectiveness and scalability.
Motivation and Challenges in Reasoning
The motivation behind APR stems from the inherent inefficiencies in serialized reasoning methods and existing parallel approaches such as self-consistency. Serialized methods exhaust context windows and increase latency due to their lengthiness, while standard parallel approaches suffer from redundant computation and lack of coordination. Such issues are further compounded by the rigid reasoning structures required by many inference-time search methods, limiting their adaptability and scalability.
APR addresses these challenges by introducing a novel threading mechanism that allows LLMs to autonomously manage serialized and parallel computations, effectively optimizing resource allocation. The framework employs reinforcement learning to dynamically optimize the branching and merging processes, thus enhancing task success rates without the need for predefined reasoning structures.
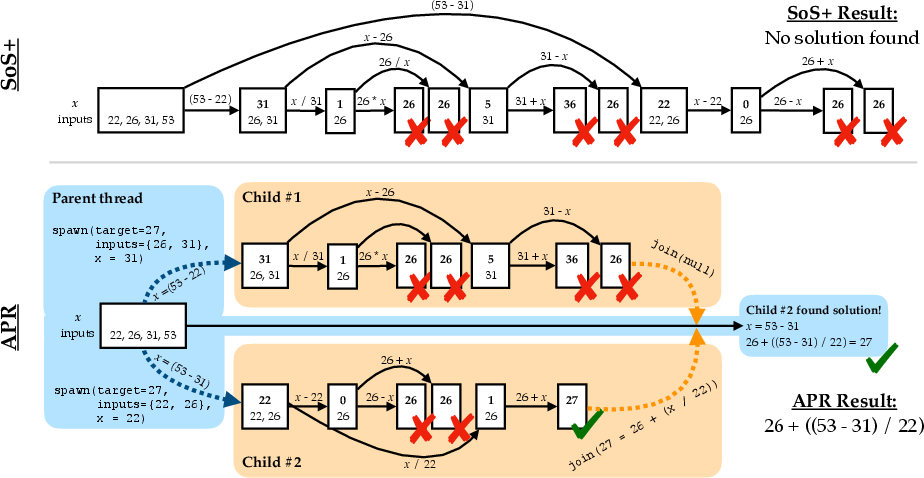
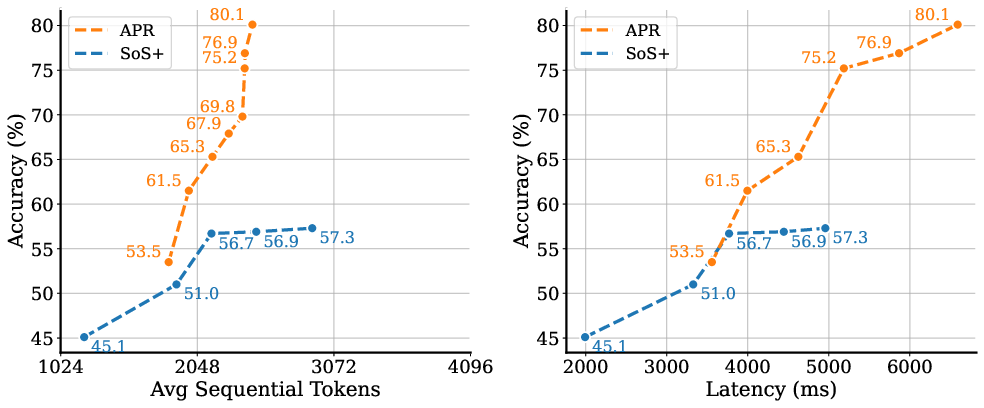
Figure 1: Serialized search vs. Adaptive Parallel Reasoning illustrated on Countdown task; APR prevents context window exhaustion and reduces latency.
Adaptive Parallel Reasoning Framework
Threading Mechanism
APR introduces two main innovations: a parent-child threading mechanism for inference and end-to-end reinforcement learning training protocols. LLMs operate as parent inference threads capable of spawning child threads for parallel exploration. Each child thread executes independently, providing outcomes back to the parent via join operations, resulting in more efficient traversal of reasoned paths.
APR leverages SGLang for simultaneous child thread execution, drastically reducing real-time latency. The reinforcement learning strategy further refines this process, optimizing task outcomes by training models to adaptively parallelize computations and manage their token usage efficiently.
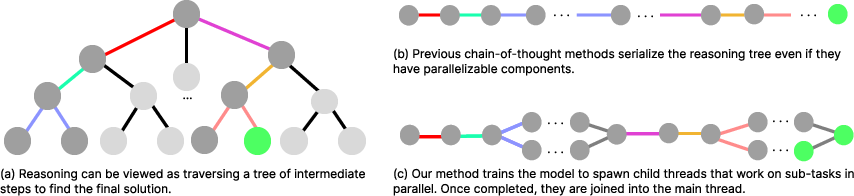
Figure 2: Overview of Adaptive Parallel Reasoning showing parent and parallel child threads alternating for efficient reasoning tree traversal.
Training Methodologies
APR models undergo an initial supervised learning phase utilizing automatically generated demonstrations from symbolic solvers, followed by fine-tuning through reinforcement learning. This dual-phase training facilitates generalization over various reasoning tasks, allowing APR to dynamically structure search strategies based on task requirements.
The symbolic solver algorithms generate hybrid search trajectories—integrating breadth-first and depth-first search paths—to enrich the training dataset with diverse reasoning strategies. Subsequently, reinforcement learning optimizes real-time performance by exploring strategy space adaptations that balance computational efficiency against context limitations.
Experimental Findings
APR exhibits unequivocal advantages over serialized search methodologies and cons-based parallel inference techniques. On the Countdown task, APR achieves remarkable enhancements in context window performance, scalability with increased computation, and accuracy relative to latency.
Reinforcement learning further enhances APR, increasing accuracy by adaptive resource allocation methods. The experiments reveal that RL significantly boosts APR’s effectiveness by expanding search dimensions and efficiently utilizing compute resources.
Implications and Future Directions
APR represents a pivotal step forward in autonomous reasoning for LLMs. It exemplifies how dynamic structuring of inference-time computations can lead to improved efficiency, scalability, and performance. The approach holds potential applicability in tasks beyond prototypes like Countdown, including real-world language processing applications.
Future research might explore adapting APR to pretrained LLMs for generalized tasks, reducing reliance on supervised training, and innovating orchestration protocols for better communication among threads. These advances could amplify the practical applications of APR, enabling its integration into broader AI systems with enhanced reasoning capabilities.
Conclusion
APR signifies a substantial advancement in LLM reasoning techniques, showcasing how adaptive parallelization can address longstanding inefficiencies in serialized and fixed-structure inference methods. By integrating reinforcement learning with a novel threading mechanism, APR optimizes computational resources effectively, paving the way for more autonomous and efficient reasoning processes in AI systems.