- The paper introduces SSA, which separates answer generation from analysis to leverage parallel sampling for enhanced LLM performance.
- It employs reinforcement learning with GRPO and supervised fine-tuning to optimize answer aggregation, outperforming majority voting benchmarks.
- Experimental results show that even a compact SSA model can match larger models, yielding improved accuracy in mathematical reasoning tasks.
Learning to Reason Across Parallel Samples for LLM Reasoning
Introduction
The research paper "Learning to Reason Across Parallel Samples for LLM Reasoning" (2506.09014) introduces a method for leveraging multiple sampling strategies to improve LLM performance in reasoning tasks. It highlights the development of a novel test-time scaling approach, Sample Set Aggregator (SSA), which combines aspects of parallel and sequential scaling while optimizing output through reinforcement learning (RL). This approach promises efficiency and efficacy improvements over existing methods such as majority voting, particularly in mathematical reasoning domains.
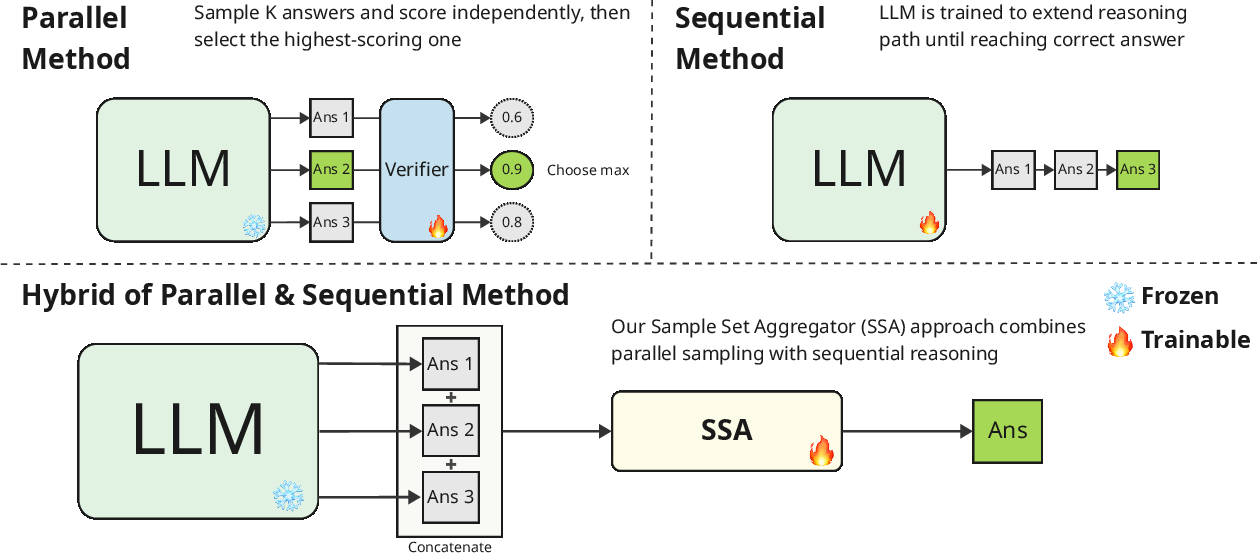
Figure 1: Illustration of our approach, showing the Sample Set Aggregator at the bottom compared to traditional parallel and sequential methods.
Methodology
The SSA Framework
The SSA framework is designed to operate alongside a black-box LLM that generates candidate answers without undergoing RL. The key idea is to separate the generation phase from the analysis and aggregation phase. SSA is trained using RL to accurately produce a final answer from concatenated samples. This method views multiple generations as a representation of an LLM's output distribution, allowing direct optimization based on the landscape of this distribution.
Training Strategies
The paper explores two main training strategies for SSA:
Experimental Results
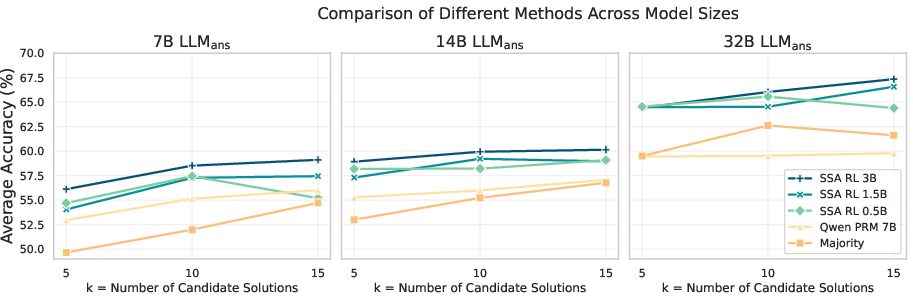
The experiments conducted demonstrate SSA's effectiveness across multiple benchmarks, showcasing its ability to outperform existing methods such as majority voting and process reward models (PRM). Specifically, the SSA model significantly narrows the performance gap relative to the oracle-best accuracy (pass@5). Notably, even a compact SSA model can match larger models trained under traditional methods, emphasizing efficiency and scalability.
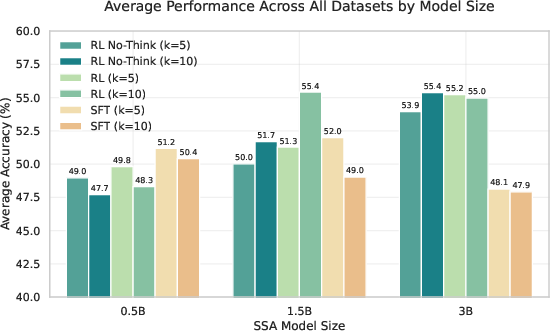
Figure 3: Performance comparison of different training methods (SFT, No-Think, RL) across model sizes.
Theoretical and Practical Implications
The SSA approach has theoretical importance in advancing understanding of representation learning over sampled outputs. Instead of dedicating compute resources to re-training large models, the SSA capitalizes on existing sampling methods by reusing outputs efficiently. Hence, it provides a promising direction for using smaller, optimized models to manage and improve large LLM outputs, thus fostering adaptable reasoning systems.
Practically, SSA offers benefits in mathematical domains, where answer accuracy is paramount. Moreover, it indicates potential generalization capabilities, suggesting SSA's application in varied tasks beyond those initially tested.
Challenges and Future Directions
Some limitations include its dependency on the quality of the sampled outputs—particularly the occurrence of correct answers within the sample set, a challenge illustrated during error analysis. Future work could expand SSA's capacity to synthesize answers rather than merely select among them, enabling further applications in diverse domains, including non-mathematical reasoning.
Additionally, optimizing SSA to handle larger sample sizes in light of potential context-length limitations and exploring its integration with multiple LLM outputs are promising avenues for development.
Conclusion
The paper advances the study of LLM reasoning capabilities by introducing SSA—a hybrid scaling strategy that efficiently refines outputs through reinforcement learning. By separating answer generation from analysis, SSA emerges as a practical approach to augment existing LLM inference processes, heralding versatility and efficiency for future AI development endeavors. Such innovations may serve as crucial components in the ongoing augmentation of LLM intelligence and scalability.