- The paper shows that in-context learning, using next-token prediction without weight updates, fits within the PAC learning framework.
- The study employs extensive experiments with varied prompting strategies, revealing that increasing exemplar count significantly boosts accuracy.
- ICL demonstrates robustness to training shifts but remains vulnerable to out-of-distribution inputs, challenging its generalizability.
Is In-Context Learning Learning? An Empirical and Theoretical Analysis
Introduction
The paper "Is In-Context Learning Learning?" (2509.10414) presents a rigorous investigation into the nature of in-context learning (ICL) in autoregressive LLMs. The central question addressed is whether ICL, as performed by LLMs via next-token prediction, constitutes genuine learning in the formal sense, or merely reflects deduction and memorization of prior knowledge. The authors combine theoretical framing with extensive empirical analysis, ablating factors such as memorization, pretraining, distributional shifts, and prompt phrasing, to characterize the learning dynamics and limitations of ICL.
Theoretical Framework
The study grounds its analysis in the PAC (Probably Approximately Correct) learning framework, reframing it to focus on the learner's robustness to distributional shifts. In this context, learning is defined as the ability to generalize from a training distribution P to a test distribution Q=P, with bounded error. The authors formalize ICL as a process where the LLM, conditioned on a prompt and exemplars, predicts labels for new inputs. Importantly, ICL does not update model weights; instead, it leverages the prompt and exemplars to perform ad hoc inference.
The paper argues that, mathematically, ICL fits within the PAC learning paradigm, as the model's predictions are conditioned on observed exemplars and prompt context. However, the mechanism by which ICL encodes and utilizes information is fundamentally different from traditional learning algorithms, raising questions about its robustness and generalizability.
Experimental Design
The empirical study is extensive, involving four LLMs (GPT-4 Turbo, GPT-4o, Mixtral 8x7B, Phi-3.5 MoE), nine tasks spanning regular and context-free languages, and multiple prompting strategies:
Tasks include PARITY, Pattern Matching, Reversal, Stack manipulation, Hamiltonian path verification, Maze solving, and Vending Machine arithmetic. Synthetic datasets are generated to control for contamination and ensure precise distributional shifts (δ), with both in-distribution (ID) and out-of-distribution (OOD) test sets.
Main Results
Accuracy Trends and Prompting Effects
Across all tasks and models, increasing the number of exemplars ("shots") consistently improved accuracy, with best performance typically achieved at 50-100 shots—substantially higher than the few-shot regime often cited in prior literature. The gap in accuracy between models and prompting strategies narrowed as the number of shots increased, indicating that, in the limit, ICL's effectiveness is less dependent on model architecture or prompt style and more on the autoregressive mechanism.
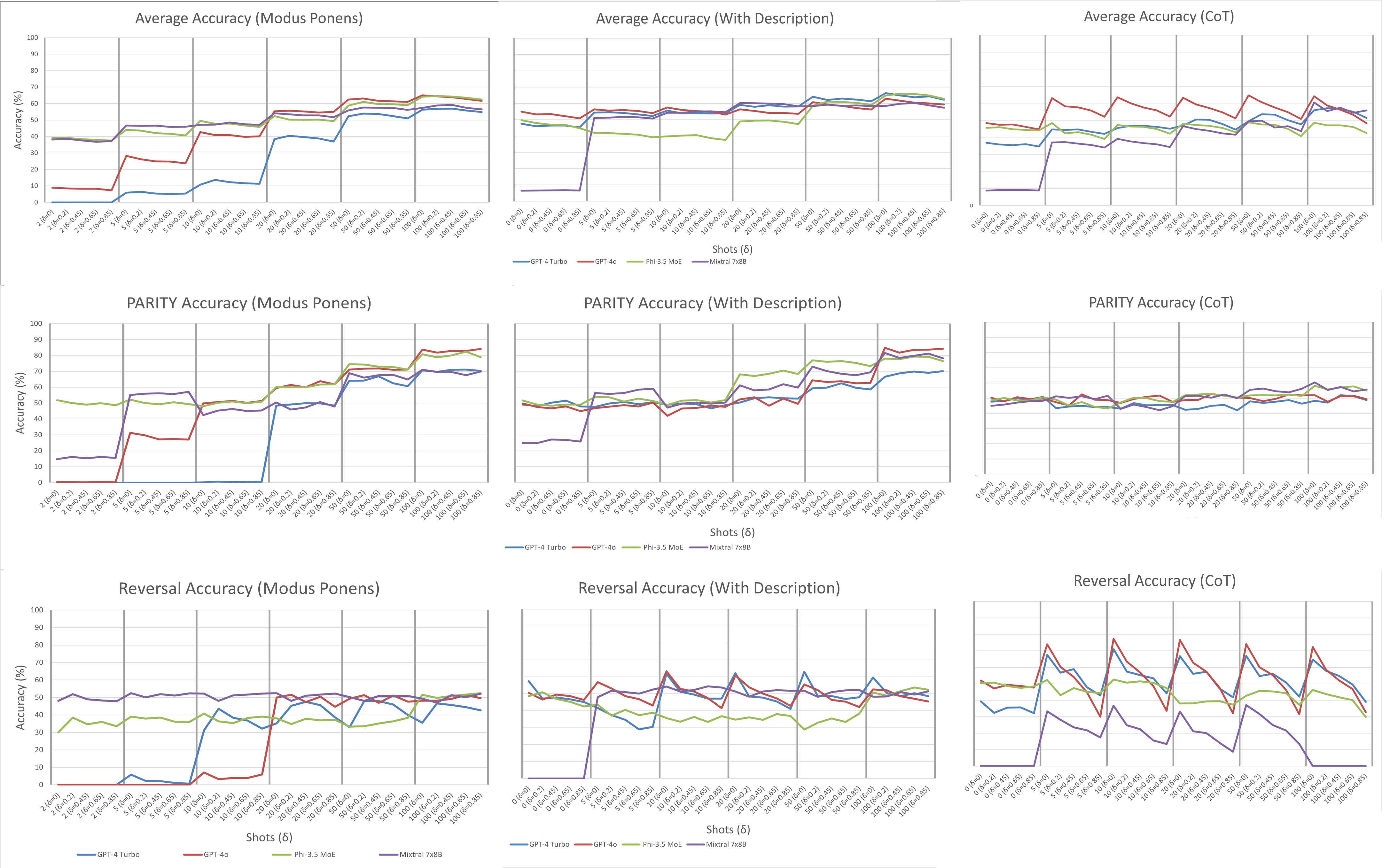
Figure 1: Average accuracy results for all-task, PARITY, and Reversal across prompting strategies and shot counts, highlighting the narrowing gap and performance trends.
Description-based and CoT prompts yielded the highest peak accuracies, but CoT and APO were notably brittle to OOD inputs, with sharp declines as δ increased. Word Salad prompts, which randomized lexical content, converged to baseline performance with sufficient shots, suggesting that semantic content in prompts is less critical than the statistical regularities present in the exemplars.
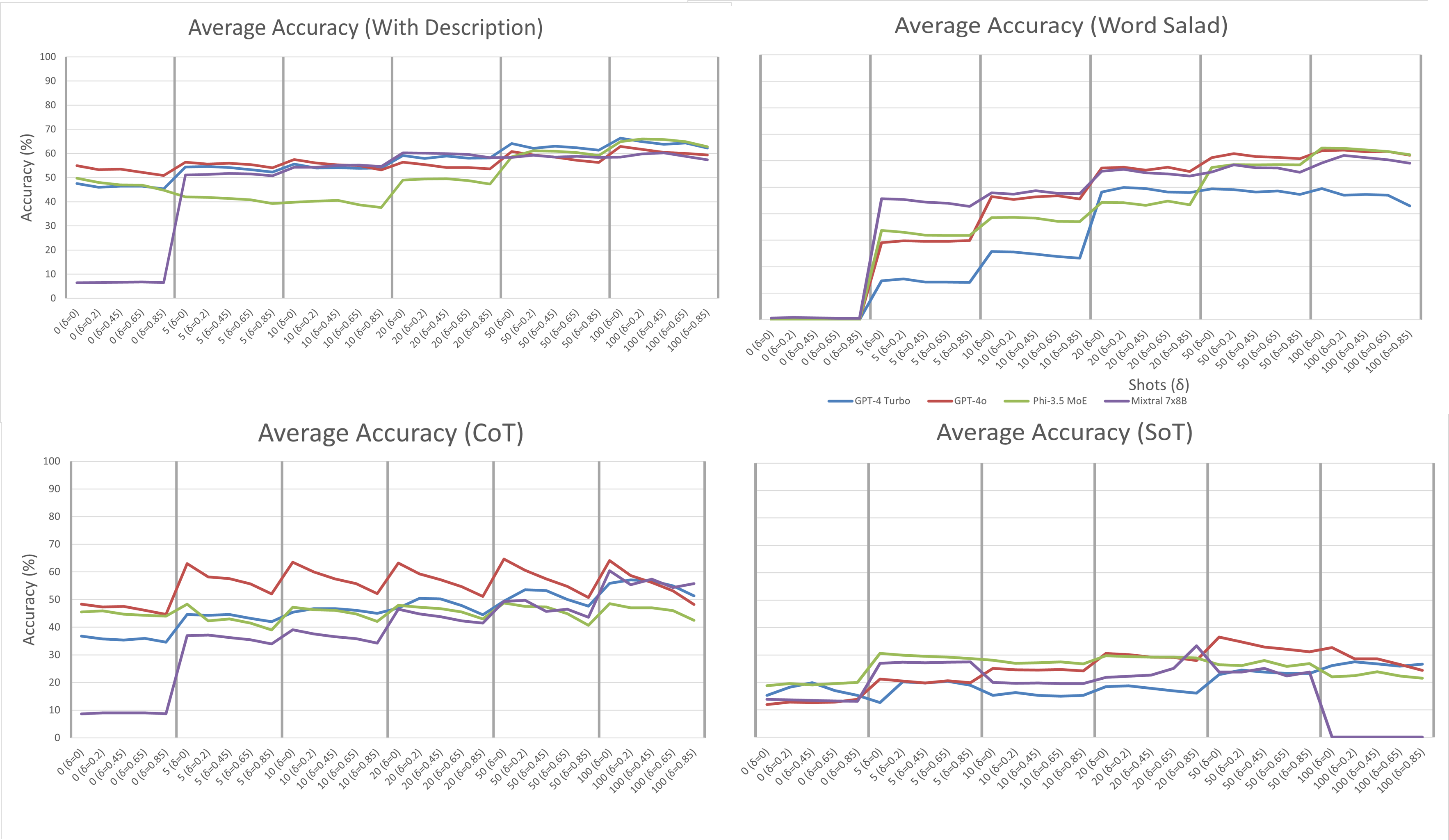
Figure 2: Comparison of baseline and word-salad prompts, showing convergence in accuracy with increasing shots.
Distributional Robustness and OOD Sensitivity
ICL demonstrated robustness to changes in the training (exemplar) distribution, such as label imbalance and positionality, but was highly sensitive to shifts in the test distribution. The largest negative slopes in accuracy under OOD conditions were observed for CoT and APO prompts, indicating that adaptive or reasoning-based prompting strategies exacerbate brittleness to distributional shifts.
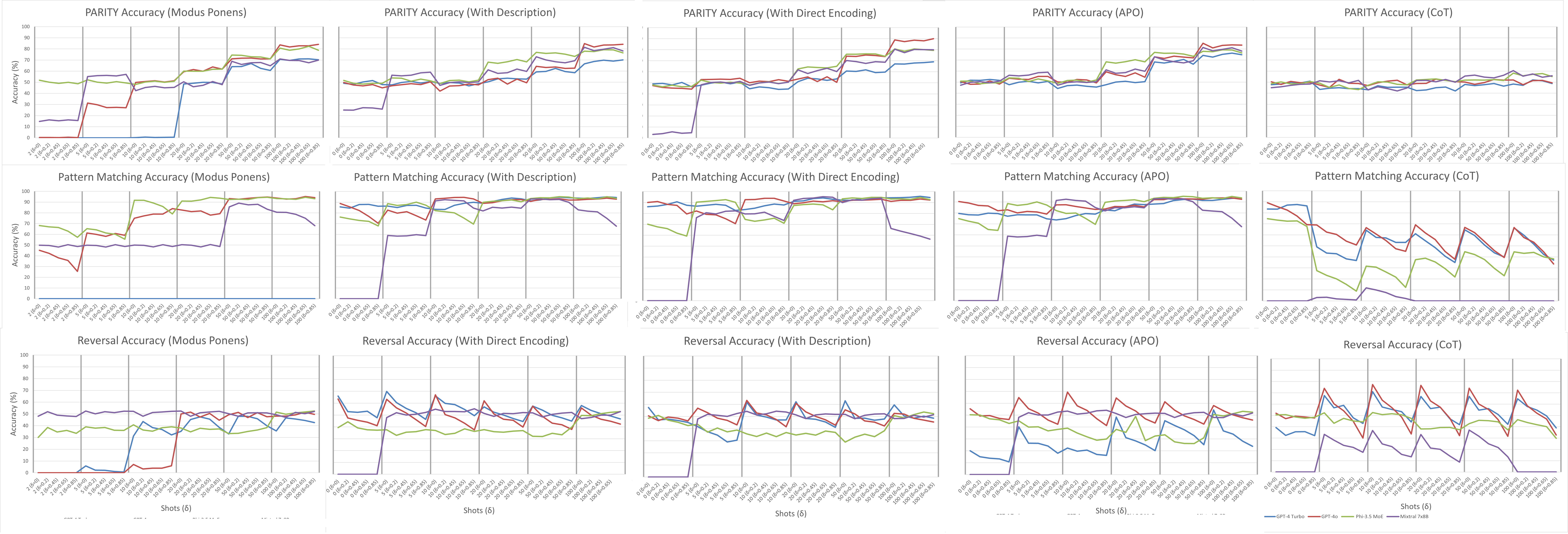
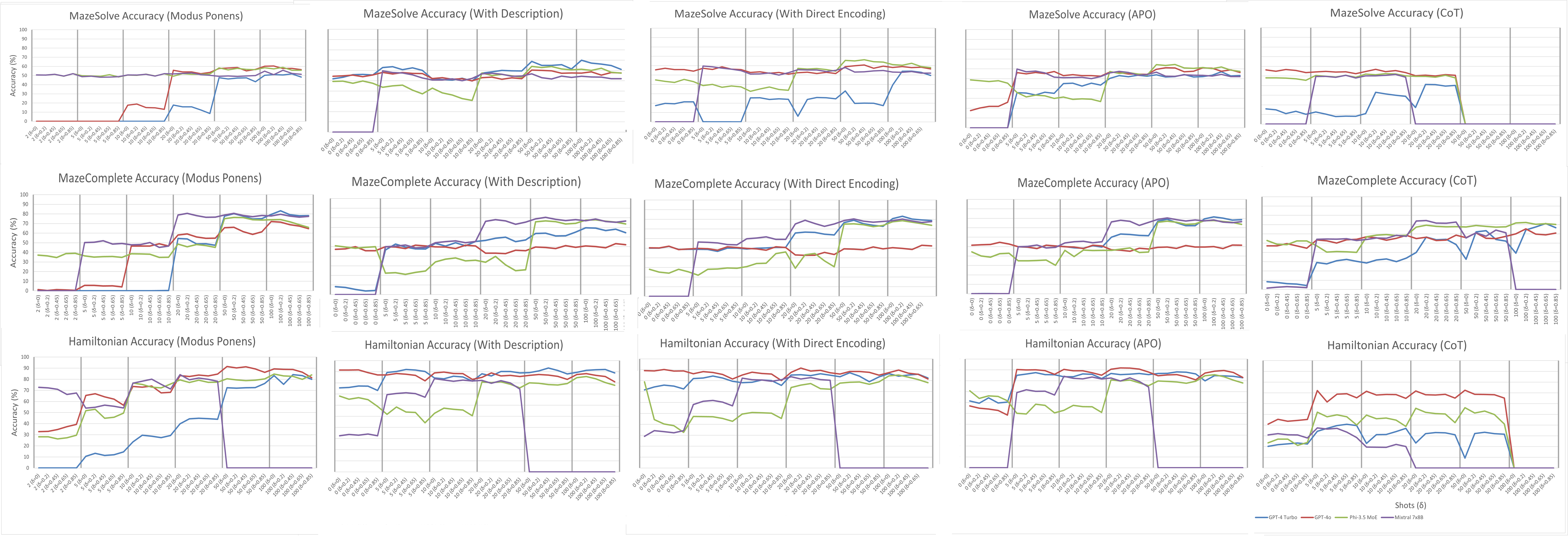
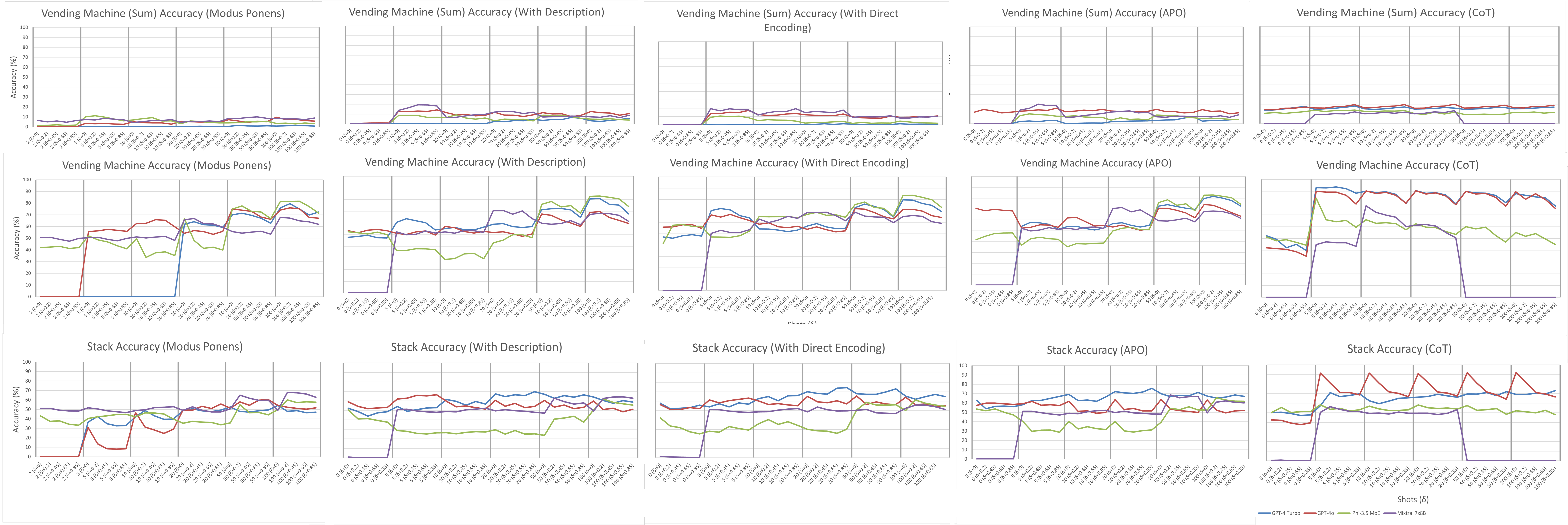
Figure 3: Complete set of performances per problem, illustrating consistent behaviors and the lack of robustness of CoT to OOD.
Task Complexity and Generalization
Performance varied markedly across tasks, even among those with similar formal properties. For example, Pattern Matching (FSA) was solved with high accuracy, while Reversal (PDA) and Maze Solve (FSA) exhibited much lower performance. Traditional baselines (decision trees, kNN, MLP) outperformed ICL in several tasks, particularly under OOD conditions, challenging claims of LLM superiority in generalization.
Ablation Studies
Lexical Features
Randomizing prompt lexical content (Word Salad, SoT) had minimal impact on final accuracy in the limit, provided exemplars remained fixed. This indicates that LLMs rely more on statistical patterns in the data than on semantic understanding of the prompt.
Exemplar Positionality
Shuffling or randomizing exemplar order had negligible effect on accuracy, contradicting prior claims of LLM sensitivity to exemplar ordering.
Alternate Distributions
Imbalanced or randomly labeled exemplars did not degrade performance, but fully randomizing exemplars reduced accuracy, consistent with bias-variance tradeoff phenomena.
Compliance vs. Learning
Separating parsing errors from mislabeling revealed that compliance with output format can mask true learning performance, especially in prompts with high error rates.
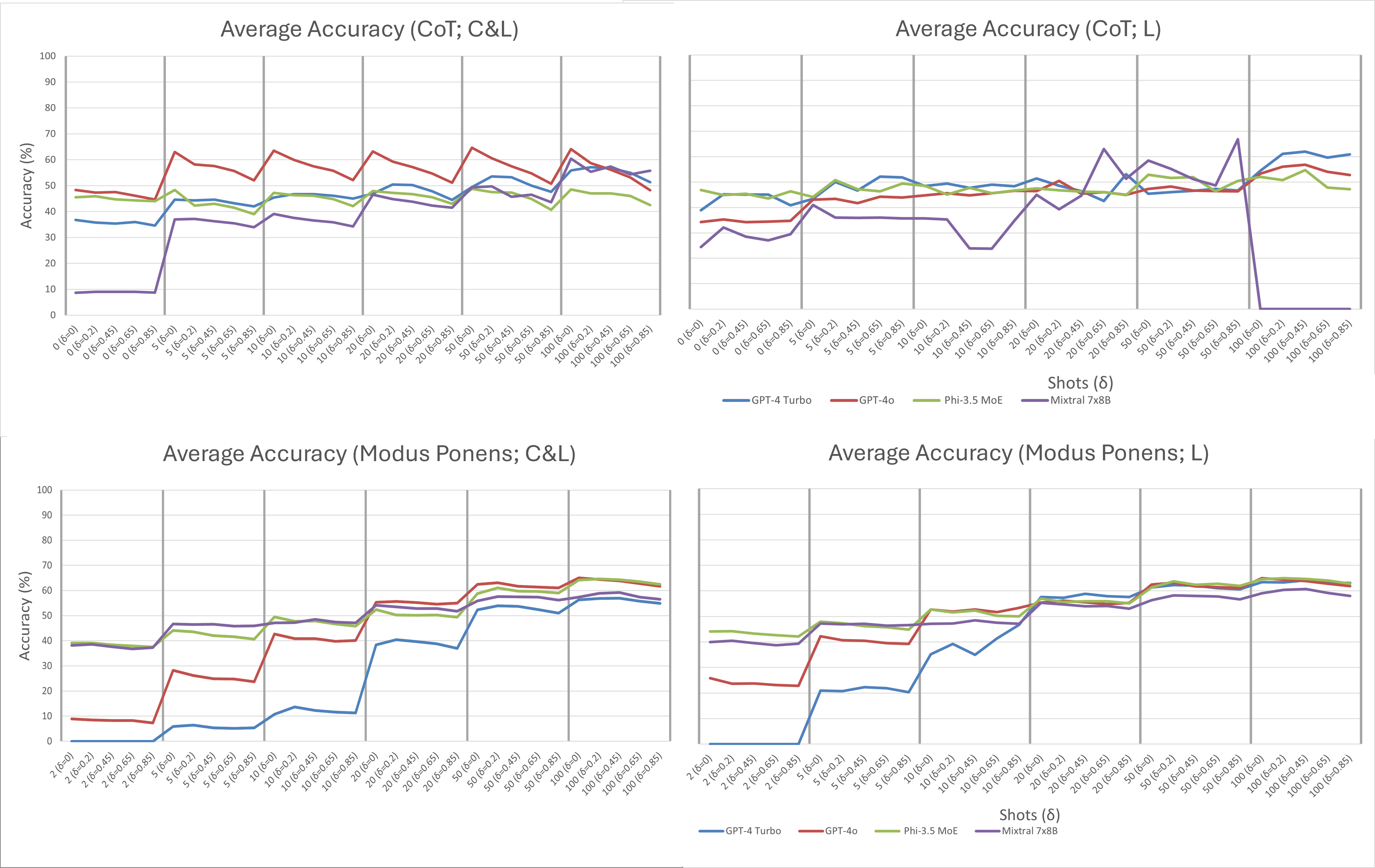
Figure 4: Comparison of compliance and learning metrics, showing the impact of parsing errors on perceived performance.
Discussion
The findings support the claim that ICL constitutes a form of learning, as defined by PAC theory, but with significant caveats. ICL's learning is tightly coupled to the autoregressive paradigm and the representativeness of the observed data. The ad hoc encoding mechanism—reliance on prompt and exemplars—limits cross-task generalizability and robustness to OOD inputs. Adaptive prompting strategies (CoT, APO) enhance performance in-distribution but increase brittleness to distributional shifts.
The observed pathologies, such as overfitting to spurious features and inconsistent performance across formally similar tasks, mirror well-known issues in classical machine learning. The results also highlight the importance of comprehensive evaluation across multiple prompts, shots, and distributions to avoid spurious conclusions about LLM capabilities.
Implications and Future Directions
Practically, the study suggests that deploying LLMs for unseen tasks via ICL requires careful consideration of exemplar quantity, prompt design, and distributional representativeness. Theoretically, it challenges the notion of emergent generalization in LLMs, emphasizing the limitations of autoregressive inference for robust learning.
Future research should explore reasoning models with baked-in CoT, their performance on context-sensitive languages, and further characterize the boundaries of ICL as a learning paradigm. The brittleness to OOD and inconsistency across tasks underscore the need for more principled approaches to prompt engineering and evaluation.
Conclusion
This work provides a comprehensive empirical and theoretical characterization of ICL in LLMs, demonstrating that while ICL is a valid learning mechanism, its generalization and robustness are fundamentally constrained by the autoregressive paradigm and the statistical properties of the prompt and exemplars. The nuanced accuracy trends, sensitivity to OOD, and prompt dependence have significant implications for both the deployment and evaluation of LLMs in real-world and research settings.

