In-Context Learning with Representations: Contextual Generalization of Trained Transformers
Published 19 Aug 2024 in cs.LG, cs.CL, cs.IT, math.IT, math.OC, and stat.ML | (2408.10147v2)
Abstract: In-context learning (ICL) refers to a remarkable capability of pretrained LLMs, which can learn a new task given a few examples during inference. However, theoretical understanding of ICL is largely under-explored, particularly whether transformers can be trained to generalize to unseen examples in a prompt, which will require the model to acquire contextual knowledge of the prompt for generalization. This paper investigates the training dynamics of transformers by gradient descent through the lens of non-linear regression tasks. The contextual generalization here can be attained via learning the template function for each task in-context, where all template functions lie in a linear space with $m$ basis functions. We analyze the training dynamics of one-layer multi-head transformers to in-contextly predict unlabeled inputs given partially labeled prompts, where the labels contain Gaussian noise and the number of examples in each prompt are not sufficient to determine the template. Under mild assumptions, we show that the training loss for a one-layer multi-head transformer converges linearly to a global minimum. Moreover, the transformer effectively learns to perform ridge regression over the basis functions. To our knowledge, this study is the first provable demonstration that transformers can learn contextual (i.e., template) information to generalize to both unseen examples and tasks when prompts contain only a small number of query-answer pairs.
The paper demonstrates that one-layer multi-head transformers trained on non-linear regression tasks achieve linear convergence and effective in-context learning using ridge regression.
The study leverages multi-head softmax attention to generalize from noisy, few-shot prompts under mild assumptions, bypassing restrictive constraints of previous works.
Empirical validations show that both shallow and deeper transformer architectures closely approximate ridge regression solutions, enhancing applicability in underdetermined settings.
In-Context Learning with Representations: Contextual Generalization of Trained Transformers
Introduction and Motivation
This paper addresses the theoretical underpinnings of in-context learning (ICL) in transformers, focusing on the ability of trained models to generalize contextually from prompts containing only a few (potentially noisy) query-answer pairs. Unlike prior works that require large prompt lengths or restrictive assumptions (e.g., orthogonality of tokens, special initialization, or mean-field limits), this study analyzes a one-layer multi-head softmax attention transformer trained via gradient descent on non-linear regression tasks, where the underlying function (the "template") is a linear combination of m arbitrary basis functions. The central question is how such a transformer can learn to generalize to unseen examples and tasks when the prompt is underdetermined.
Problem Setup and Model Architecture
The ICL task is formalized as follows: each task is defined by a template function f(⋅)=∑i=1mλifi(⋅), where fi are basis functions and λ is a task-specific coefficient vector. For each prompt, only N (noisy) labeled examples are provided, with N<m in the underdetermined regime. The transformer must predict labels for all K tokens in a dictionary V.
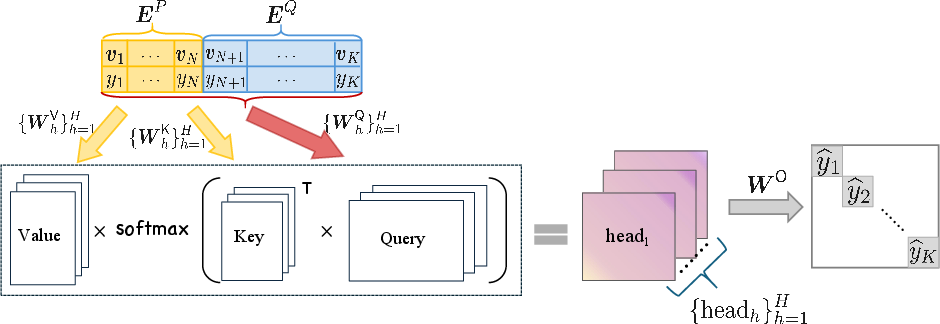
The model is a one-layer transformer with H attention heads and softmax attention, as depicted in (Figure 1).
Figure 1: The structure of a one-layer transformer with multi-head softmax attention.
The architecture is parameterized such that the output for each token is a weighted sum over the prompt, with the weights determined by multi-head attention. The model is trained end-to-end using mean-squared error loss over the entire dictionary.
Theoretical Results
Training Dynamics and Convergence
The main theoretical result establishes that, under mild assumptions (i.i.d. Gaussian noise, minimal requirements on token distinctness, and H≥N), the training loss of the transformer converges linearly to a global minimum. The proof leverages a reformulation of the loss, showing that the necessary and sufficient condition for convergence is that the model's attention-weighted outputs approximate a specific matrix derived from the template basis and the prompt.
Key technical contributions include:
Initialization: With H≥N and random Gaussian initialization, the attention matrices have full row rank with probability 1, ensuring convergence.
Learning Rates: The analysis provides explicit conditions on the learning rates for query/key and value parameters to guarantee linear convergence.
Smoothness and PL Condition: The loss is shown to be smooth and satisfies the Polyak-Łojasiewicz condition, enabling the linear rate.
Inference-Time Behavior and Generalization
After training, the transformer implements ridge regression over the basis functions to infer the template coefficients from the prompt. Specifically, given a new prompt, the model's predictions for unseen tokens correspond to the solution of a regularized least-squares problem:
λ=argλmin{2N1i=1∑N(yi−λ⊤f(xi))2+2Nmτ∥λ∥22}
The model's output for all tokens is then f(xk)⊤λ. The analysis quantifies the iteration complexity required to achieve ε-accuracy in mean-squared error, and shows that the model generalizes both to unseen examples (contextual generalization) and to unseen tasks (arbitrary λ at inference).
Comparison to Prior Work
Unlike previous theoretical analyses, this work does not require:
Large prompt lengths (sequence length N can be much smaller than m)
Orthogonality or independence assumptions on tokens
Special initialization or mean-field limits
Single-head attention (multi-head is essential for expressivity in the underdetermined regime)
The analysis also clarifies that prior "copy-paste" mechanisms (where the model simply retrieves the answer for a seen query) are insufficient in the underdetermined, noisy, or non-linear setting.
Empirical Validation
Experiments on synthetic data validate the theoretical findings:
Both 1-layer and 4-layer transformers trained on non-linear regression tasks exhibit linear convergence of training loss and inference loss.
The model's predictions for unseen tokens closely match the ridge regression solution, confirming the theoretical characterization.
The performance gap between the transformer's predictions and the best possible (oracle) predictions is minimized when the number of prompt examples N is close to the number of basis functions m.
The number of attention heads H is critical: H≥N is necessary for convergence, but excessively large H can slow convergence or destabilize training. For deeper transformers, smaller H suffices due to increased expressivity.
Interpretation and Implications
Mechanism of Contextual Generalization
The transformer acquires ICL ability by learning to extract and memorize the structure of the basis functions fi during training. At inference, it infers the template coefficients from the prompt via ridge regression, enabling generalization to both unseen examples and tasks. This mechanism is fundamentally different from copy-paste retrieval and is robust to underdetermination and noise.
Necessity of Multi-Head Attention
Multi-head attention is shown to be essential: with only a single head, the model cannot approximate the required attention distributions in the underdetermined regime, as the softmax output is sign-constrained. The analysis quantifies the trade-off between H (expressivity) and convergence rate.
Practical and Theoretical Implications
Practical: The results suggest that even shallow transformers can be trained to perform non-trivial contextual generalization in few-shot settings, provided sufficient attention heads and appropriate training.
Theoretical: The work provides the first provable demonstration that transformers can learn to perform contextual inference (template learning) in the underdetermined, noisy, non-linear regime, without restrictive assumptions.
This paper rigorously characterizes the training and inference dynamics of one-layer multi-head transformers in in-context learning of non-linear regression tasks with unknown representations. The analysis demonstrates linear convergence of training loss, necessity of multi-head attention, and contextual generalization via ridge regression, all under realistic assumptions. These results advance the theoretical understanding of ICL and provide guidance for practical model design in few-shot and underdetermined settings.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.