- The paper presents a novel RaC framework that explicitly pairs recovery and correction segments during human interventions to overcome data distribution challenges in robotic tasks.
- It achieves up to a 10× reduction in data requirements and higher success rates on long-horizon, contact-rich tasks compared to traditional imitation learning methods.
- The approach leverages a 300M parameter multimodal diffusion transformer with systematic episode termination to prevent error compounding and enable linear test-time scaling.
RaC: Robot Learning for Long-Horizon Tasks by Scaling Recovery and Correction
Introduction and Motivation
The RaC framework addresses a fundamental limitation in robot imitation learning for long-horizon, contact-rich, and deformable-object manipulation tasks. Conventional approaches, which scale up expert demonstration data, exhibit a pronounced performance plateau even with thousands of demonstrations. This plateau is attributed to the data distribution: expert demonstrations are biased toward clean, successful trajectories and lack coverage of out-of-distribution (OOD) and failure states, resulting in compounding errors and poor robustness. RaC introduces a new phase of human-in-the-loop data collection and policy fine-tuning, explicitly targeting recovery and correction behaviors to overcome these limitations.
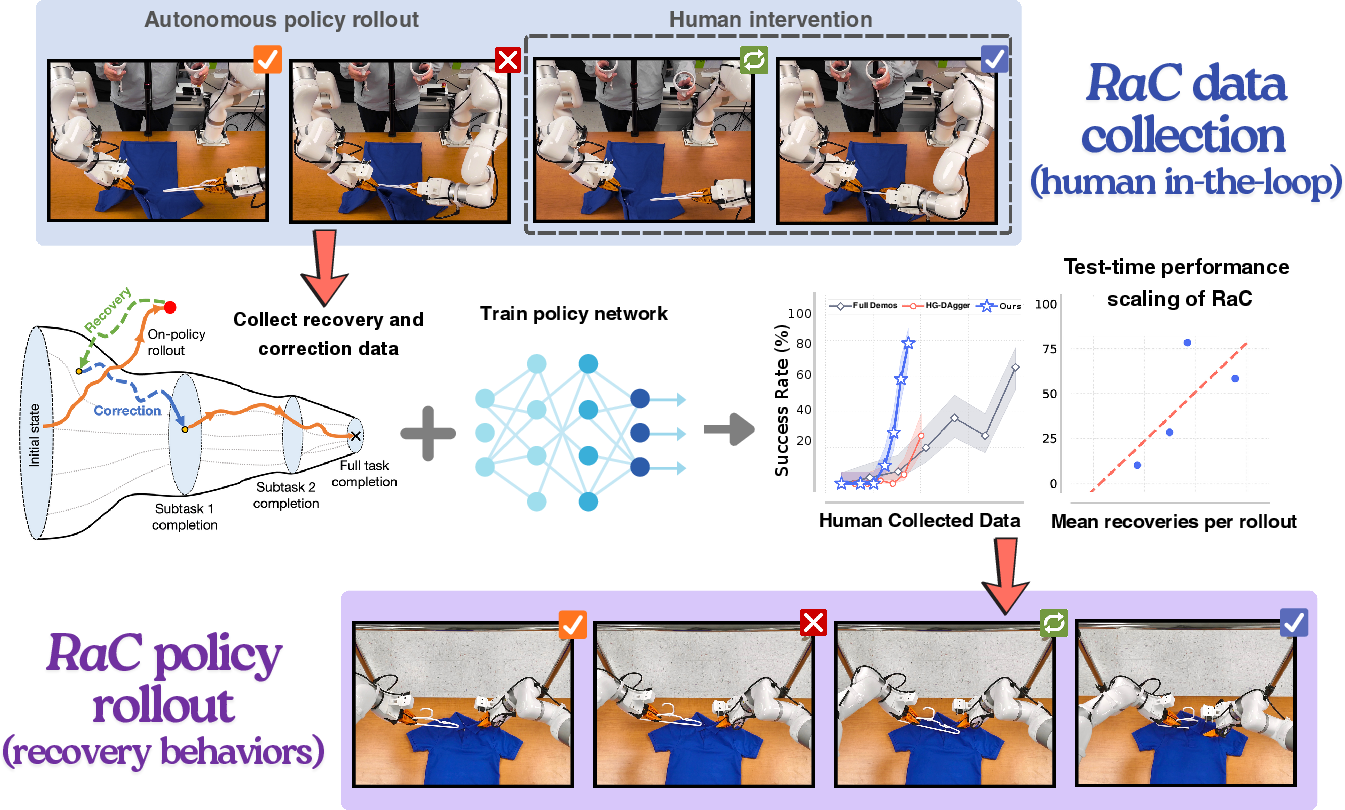
Figure 1: RaC enables policies to robustly execute long-horizon tasks by learning explicit recovery and correction skills, improving data efficiency and performance scaling via increased recovery maneuvers.
RaC Data Collection Protocol
RaC augments standard imitation learning with a structured human intervention protocol. During policy rollouts, human operators intervene when failure is imminent, first executing a recovery segment to return the robot to a familiar, in-distribution state, followed by a correction segment to complete the current sub-task. This protocol is governed by two rules:
- Rule 1: Pair each recovery segment with a correction segment.
- Rule 2: Terminate the episode after intervention, preventing contamination of later sub-tasks with mixed human-policy state distributions.
This approach densifies coverage over familiar states and teaches the robot to recover to a broader region of initial states, exploiting the verification-generation gap: recovery is easier and more sample-efficient to learn than sub-task completion.
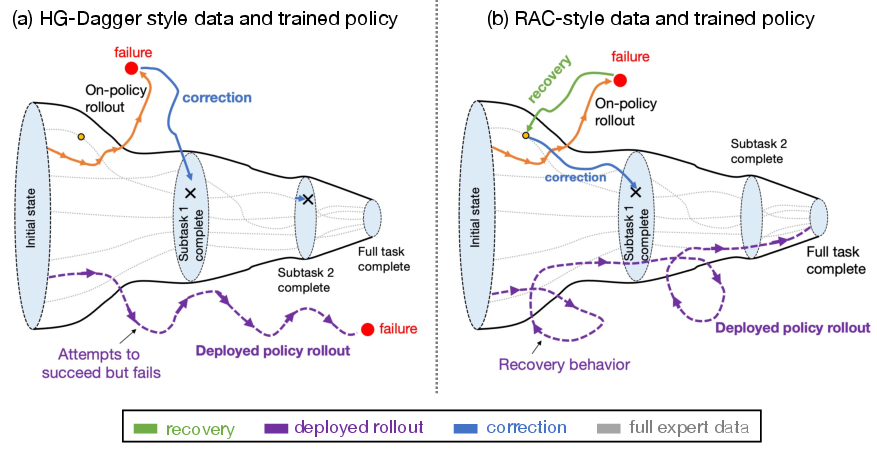
Figure 2: RaC collects recovery segments before correction, densifying coverage over familiar states and enabling retry behaviors, in contrast to correction-only approaches.
Shared Autonomy Interface
Effective human intervention requires responsive teleoperation. RaC utilizes off-the-shelf VR controllers with a clutch mechanism for seamless handover between policy and human control. A local-frame registration scheme eliminates the need for global posture alignment, reducing operator effort. Additionally, a heatmap visualization tool guides operators to recover to in-distribution regions, leveraging visitation frequency from initial demonstration data.
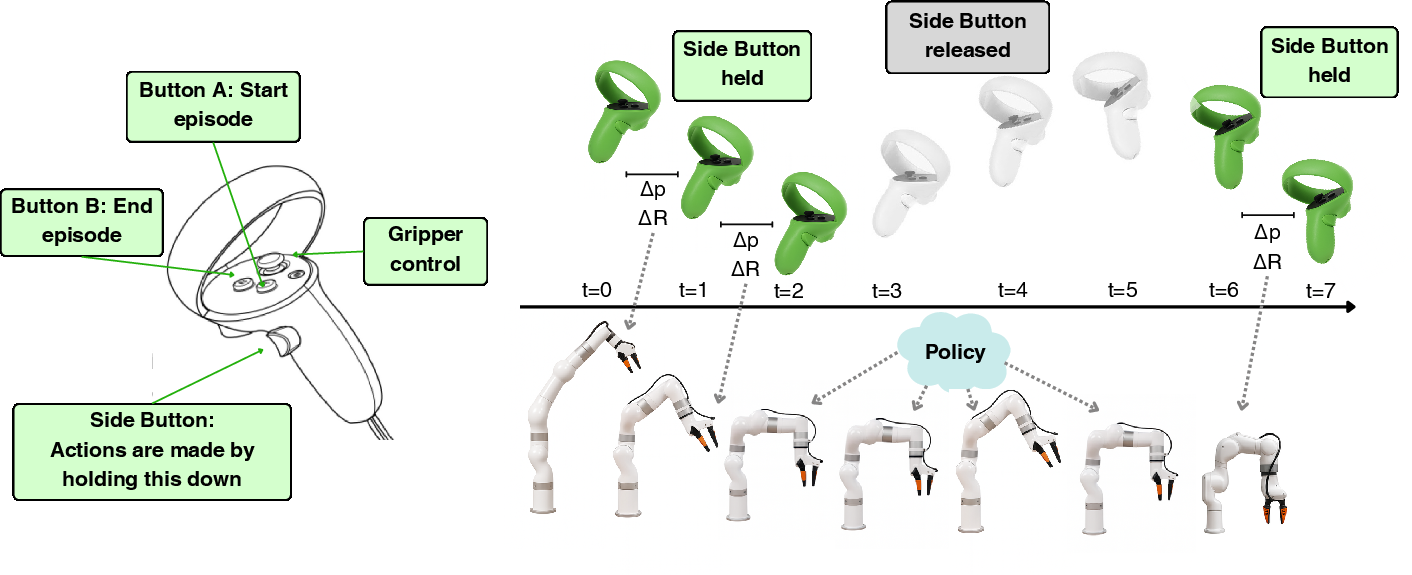
Figure 3: VR handset interface with clutch design enables smooth handover for human interventions in RaC.
Policy Architecture and Training
RaC policies are trained using a 300M parameter multimodal diffusion transformer (MM-DiT) with flow matching. The policy predicts action chunks conditioned on multi-view RGB images and proprioceptive state, optimizing a conditional flow matching loss. Training data comprises full demonstrations, successful policy rollouts, and human intervention segments (recovery and correction). During inference, actions are generated via Euler integration over the learned vector field, replanning every 0.5 seconds.
Experimental Evaluation
RaC was evaluated on three real-world bimanual manipulation tasks (shirt hanging, airtight container lid sealing, takeout box packing) and a simulated assembly task. RaC outperformed batched full demonstration and HG-DAgger-style human-in-the-loop baselines, achieving higher success rates and steeper scaling trends with up to 10× less data.
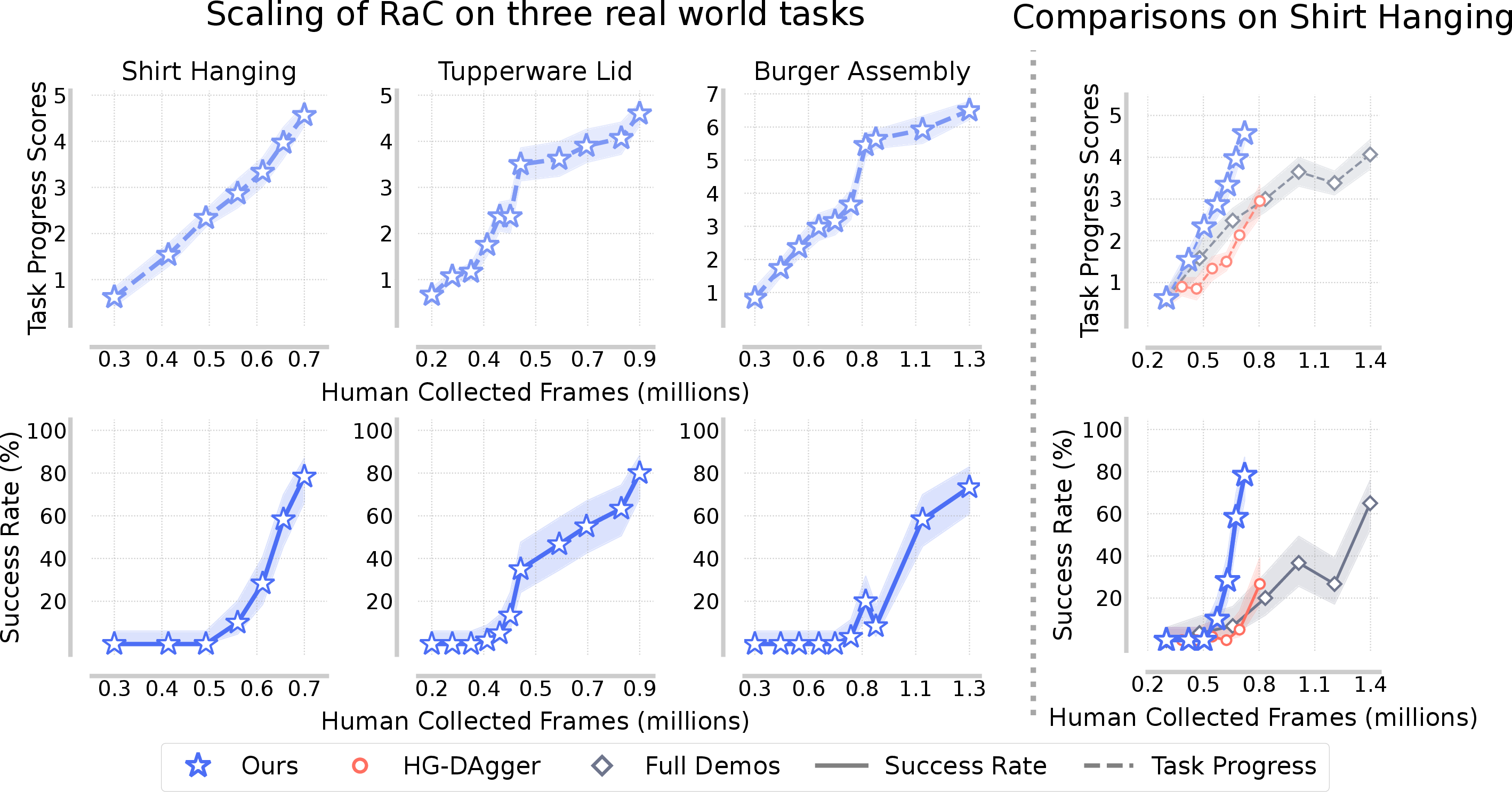
Figure 4: RaC achieves superior performance scaling as a function of human-collected frames across real-world tasks.
For example, RaC achieved 78.3% success on shirt-hanging with only 5 hours of data, compared to 75% for ALOHA Unleashed with 89 hours and 63.6% for Seed GR-3 with 116 hours. This demonstrates a strong claim: RaC delivers an order-of-magnitude improvement in data efficiency over prior state-of-the-art methods.
Robustness and Test-Time Scaling
RaC policies exhibit robustness by rapidly reducing the fraction of rollouts that make little progress and shifting probability mass toward later sub-task completions and full success. Unlike batched data collection, RaC systematically eliminates the long tail of early failures.
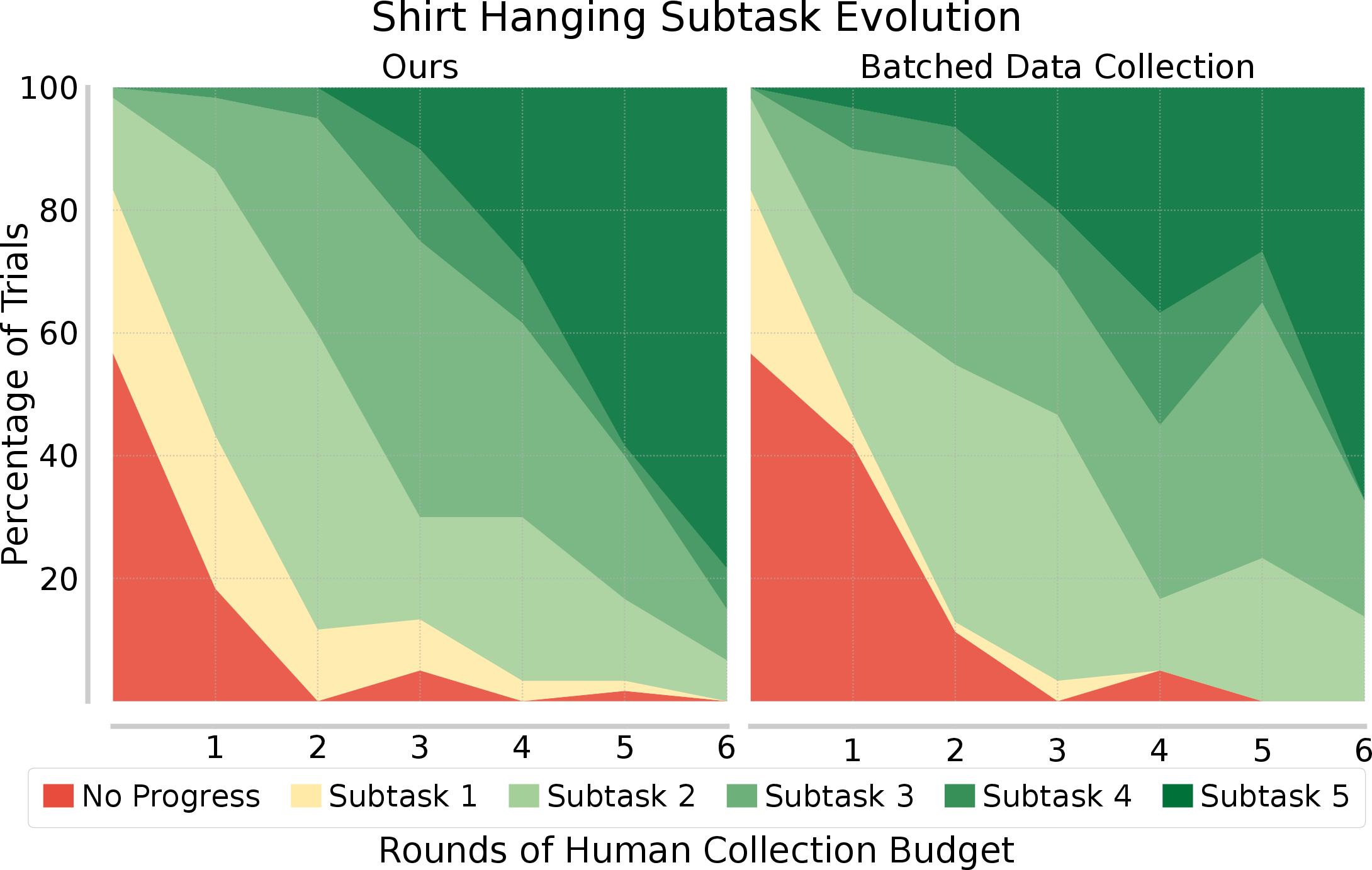

Figure 5: RaC rapidly shifts rollout distributions toward later sub-task completions and full success, outperforming batched data collection.
A key property is test-time scaling: the success rate of RaC policies increases linearly with the number of recovery maneuvers executed during deployment. This is analogous to chain-of-thought scaling in LLMs, where longer reasoning sequences improve performance.
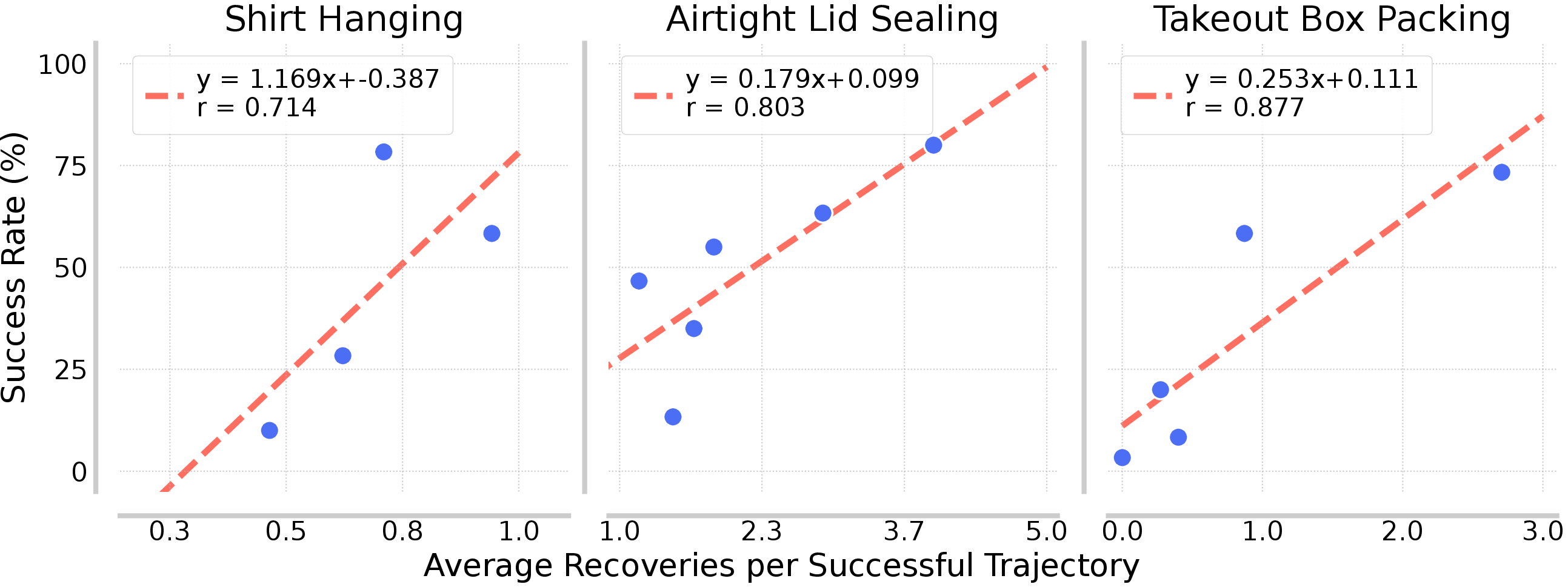
Figure 6: Success rate scales linearly with the number of recovery segments at test time, demonstrating "o1-style" test-time scaling.
RaC rollouts are generally longer and more successful, reflecting the presence of recovery behaviors that keep the task on track.
Ablation Studies
Ablations confirm the importance of both rules in RaC. Data collected via RaC maintains a balanced ratio of recovery to correction frames, while HG-DAgger skews heavily toward correction. Terminating episodes after intervention (Rule 2) yields better performance scaling than continuing rollouts, as it prevents contamination of later sub-tasks with mixed state distributions.
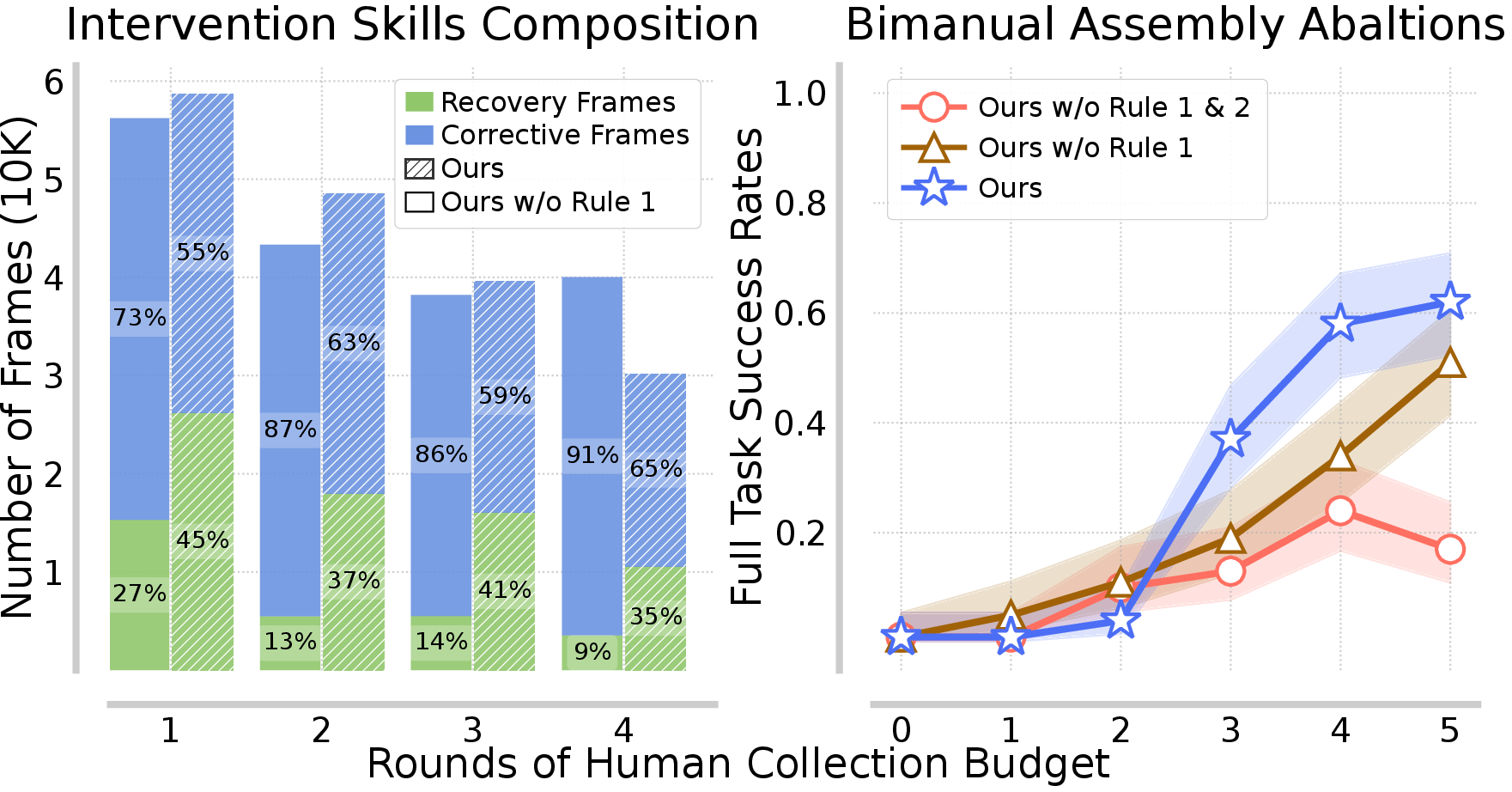
Figure 7: RaC maintains a high proportion of recovery segments; terminating after intervention improves data scaling compared to continuing rollouts.
Example Rollouts
RaC policies demonstrate explicit recovery and correction behaviors in complex, long-horizon tasks, such as shirt-hanging, airtight-container-lid-sealing, and takeout-box-packing.
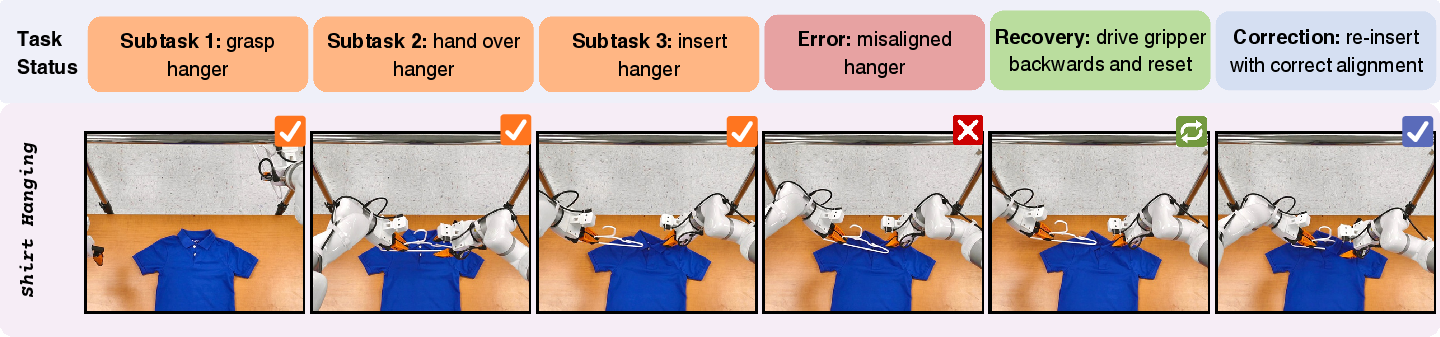
Figure 8: RaC rollout on shirt-hanging: recovery by driving gripper and hanger backwards, correction by reinserting hanger.

Figure 9: RaC rollout on airtight-container-lid-sealing: recovery by repositioning, correction by reinserting lid.

Figure 10: RaC rollout on takeout-box-packing: recovery by regrasping spatula, correction by scooping burger again.
Implications and Future Directions
RaC demonstrates that scaling the composition of data—explicitly pairing recovery and correction behaviors—can dramatically improve robustness and data efficiency in imitation learning for long-horizon robotic tasks. The framework challenges the conventional wisdom that only expert interventions are useful, showing that recovery segments, though suboptimal for immediate task completion, are critical for mitigating compounding errors.
Practically, RaC policies are well-suited as initializations for online RL fine-tuning, as recovery behaviors provide structured exploration and natural stitching points for value-based training. The approach is compatible with generalist vision-language-action models, and future work should investigate whether systematic recovery behaviors emerge in such settings and how test-time scaling curves manifest.
Conclusion
RaC introduces a principled framework for scaling imitation learning in robotics by leveraging recovery and correction behaviors through structured human interventions. The method achieves robust, high-performing policies on challenging long-horizon tasks with an order-of-magnitude reduction in data requirements. RaC's test-time scaling properties and data efficiency have significant implications for the design of future robot learning systems, particularly in settings where compounding errors and OOD states are prevalent.