- The paper introduces RLDG as a method to fine-tune generalist robotic policies using high-quality, RL-generated data.
- RLDG demonstrates superior sample efficiency and faster cycle times compared to models trained with human demonstrations.
- Optimized RL action distributions improve policy generalization and performance in complex robotic manipulation tasks.
Robotic Generalist Policy Distillation via Reinforcement Learning
This paper introduces Reinforcement Learning Distilled Generalists (RLDG), a novel method for enhancing the performance of robotic generalist policies by leveraging reinforcement learning (RL) to generate high-quality training data. The core idea is to train task-specific RL policies and then distill their knowledge into generalist policies, such as OpenVLA and Octo, by fine-tuning them on RL-generated data. The paper demonstrates that this approach outperforms traditional methods that rely on human demonstrations, particularly in tasks requiring precise manipulation. This improvement is attributed to optimized action distributions and improved state coverage achieved through RL.
Methodology: Reinforcement Learning Distilled Generalist
The RLDG framework involves training RL policies for individual tasks, then using these policies to generate training data for fine-tuning a generalist robotic manipulation policy. This distillation approach is agnostic to both the choice of RL algorithm and generalist policy architecture, offering flexibility in model selection.
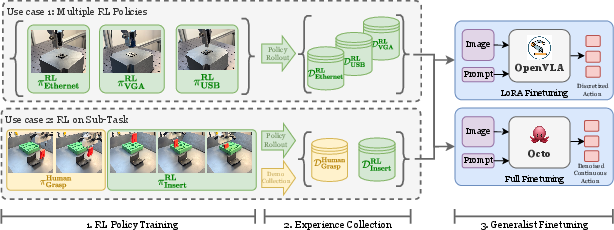
Figure 1: RLDG enhances generalist robot policies by using specialist RL policies to generate fine-tuning datasets, enabling knowledge distillation and improving performance in critical sub-tasks.
The method offers the flexibility to train and collect data using separate RL policies trained on narrowly scoped tasks. It can also train RL on bottleneck segments of a long-horizon task that require the most precision and benefit the most from RL-generated data, while leaving the less critical parts for humans to demonstrate.
The paper formulates each robotic task as a Markov Decision Process (MDP), where the policy objective is to maximize the expected discounted return (Equation 1). While RLDG is algorithm-agnostic, the paper implements RLDG using HIL-SERL, motivated by its sample efficiency and high performance for learning precise real-world manipulation skills from pixel input. After training RL experts for each of the tasks provided to RLDG, the paper collects a high-quality fine-tuning dataset by rolling out the converged policies. The collected data is then used to fine-tune pre-trained generalist models using a supervised learning objective (Equation 2). The efficacy of the method is showcased by fine-tuning two pre-trained robot generalist models, OpenVLA and Octo, using different action parametrization.
Experimental Validation
The experimental evaluation focuses on tasks requiring precise and delicate manipulation. The key questions addressed are: (1) Is training generalists using data from RL more effective than training on demonstration data? (2) Is the generalist policy resulting from RLDG training more effective at generalizing than the RL policies used to generate the training data?
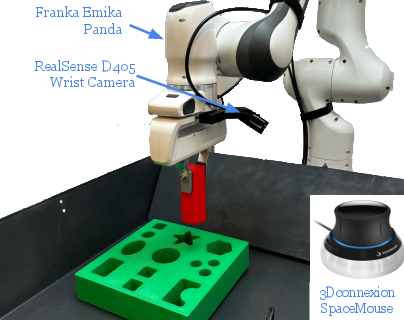
Figure 2: The experimental setup includes a Franka Emika Panda arm with a parallel jaw gripper teleoperated by a 3Dconnexion SpaceMouse device, and a RealSense D405 camera for image observations.
The robot setup for all experiments involves a Franka Emika Panda arm, and the evaluation is conducted on four real-world manipulation tasks: Connector Insertion, Pick and Place, FMB Insertion, and FMB Single Object Assembly.

Figure 3: The tasks used to evaluate RLDG include precise connector insertion, pick and place, FMB insertion, and FMB assembly, each designed to test different aspects of policy performance and generalization.
The results indicate that generalist policies fine-tuned with RL-generated data consistently achieve higher success rates than their counterparts trained with human demonstrations across all tasks (Figure 4).
Figure 4: Generalists trained with RLDG consistently outperform those trained with expert human demonstrations in both training and unseen scenarios.
Furthermore, scaling analysis reveals that fine-tuning generalist policies using RLDG is more sample-efficient and leads to higher performance than using human demonstrations (Figure 5).
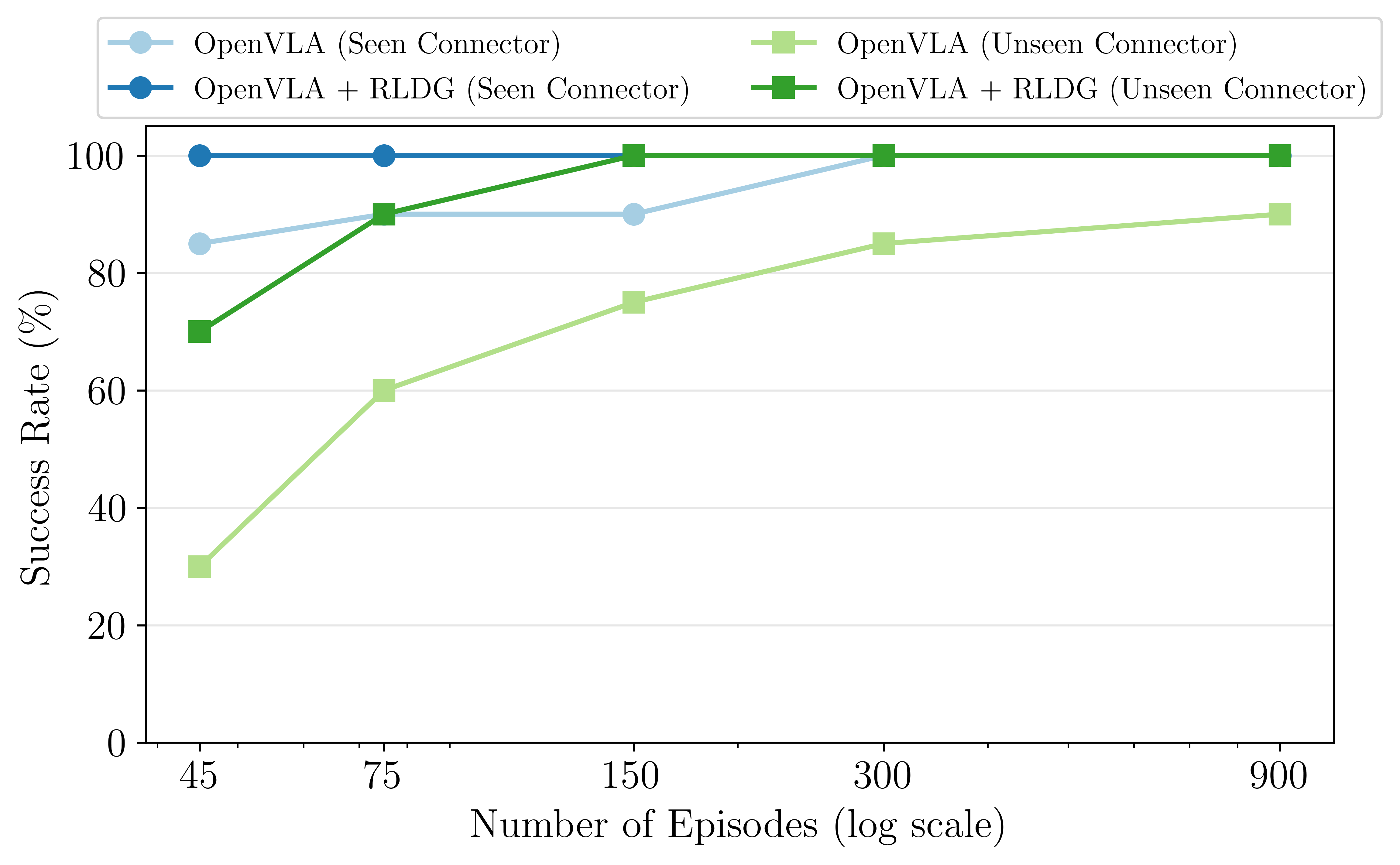
Figure 5: RLDG demonstrates superior sample efficiency, requiring significantly fewer demonstrations to achieve a perfect success rate on connector insertion tasks, while conventional methods plateau.
The policies trained with RL data also exhibit faster cycle times compared to those trained with human demonstrations (Figure 6).
Figure 6: Policies trained with RL data generally achieve faster execution times, demonstrating the efficiency benefits of using RL-generated data for policy training.
The generalization performance of generalists trained using RLDG is also superior to that of the original RL policies.
Analysis: Advantages of RL Data
The paper investigates the reasons for the superior performance of RL data by analyzing the benefits of RL actions and state distribution in isolation. By creating a mixed dataset with human data relabeled using RL actions, the authors find that action quality contributes most to the performance improvement. The action distribution of RL policies assigns more density to the correct direction, leading to better sample efficiency for fine-tuning (Figure 7).
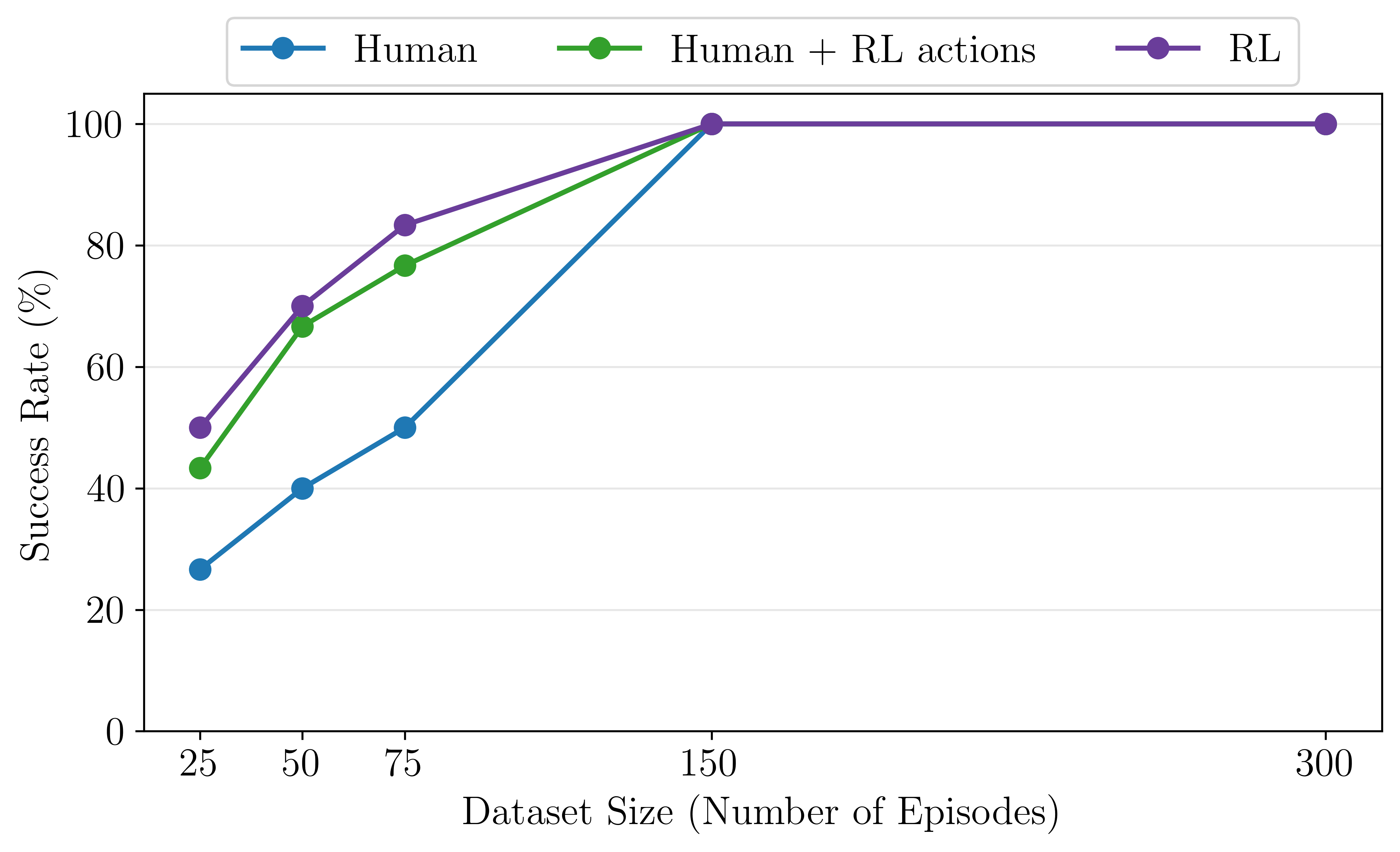
Figure 8: RL data consistently provides better fine-tuning performance than human data on the FMB insertion task, with improved action quality being a significant factor.
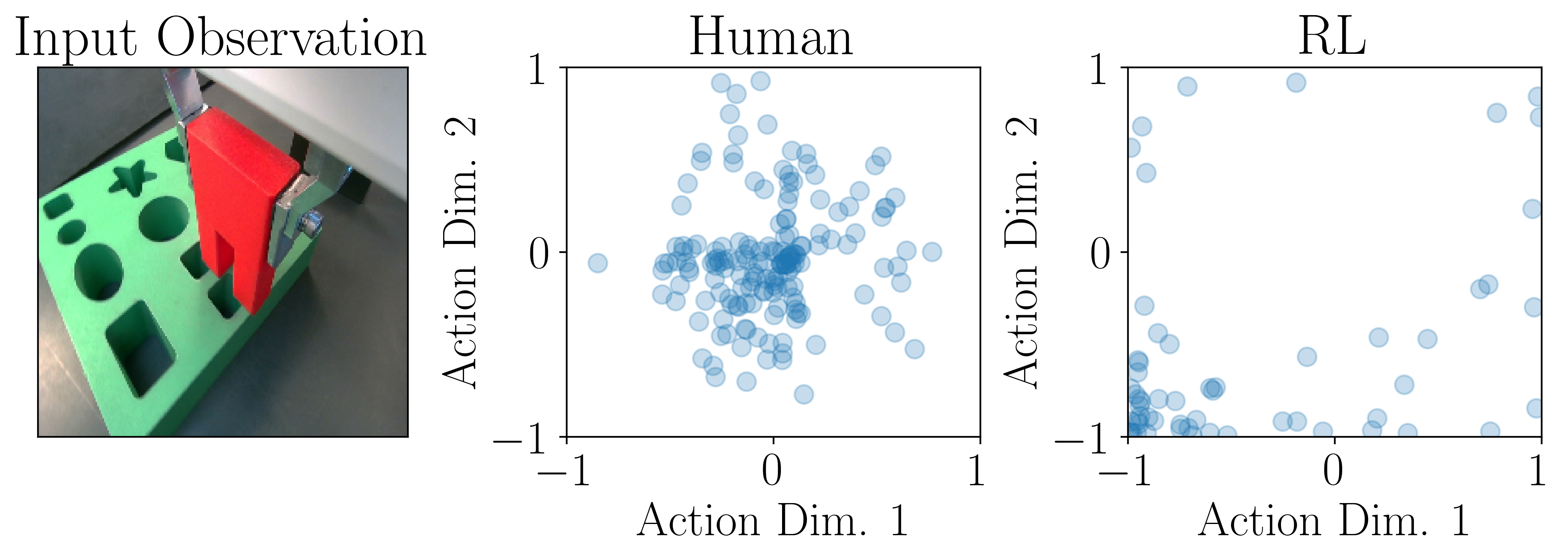
Figure 7: RL actions are more optimized and concentrated near the correct corner of the action space, while human actions are clustered around the center, indicating better action quality from RL data.
A qualitative analysis of failure modes reveals that policies trained with RL-generated data overcome alignment issues in precise tasks and reduce premature gripper closure during grasping.
Conclusion
The paper presents RLDG as a method for fine-tuning generalist policies on high-quality data generated by RL policies. The results demonstrate that RLDG achieves higher performance and better generalization compared to conventional fine-tuning methods using human demonstrations. The method assumes access to reward functions for fine-tuning tasks which may present difficulties when the task rewards are hard to specify. The paper suggests that RL policies can be an effective generator of training data for robotic foundation models, inspiring further research in this domain.