- The paper presents innovative hybrid reasoning models that balance structured multi-step reasoning with broad instruction-following using a large synthetic dataset.
- The paper integrates a graph-based synthetic data pipeline with rigorous evaluations, achieving competitive scores on benchmarks like MATH-500 and LiveCodeBench.
- The paper promotes transparency by releasing all model weights, data, and evaluation artifacts to support reproducible research and community-driven advancement.
Hermes 4: Open-Weight Hybrid Reasoning Models for Structured and Instructional Competence
Introduction and Motivation
The Hermes 4 Technical Report presents a family of hybrid reasoning models designed to integrate structured, multi-step reasoning with broad instruction-following capabilities. The work addresses the challenge of training open-weight models that can match the reasoning and alignment performance of proprietary systems, while remaining transparent and reproducible. Hermes 4 is positioned as a generalist model, neutrally aligned and capable of both deep reasoning and flexible instruction adherence, with all model weights and evaluation artifacts released for open research.
Data Synthesis and Curation
A central contribution is the large-scale hybrid dataset, comprising approximately 5 million samples and 19 billion tokens. The dataset is constructed to balance reasoning-focused and general-purpose instruction data, with 3.5 million reasoning samples and 1.6 million non-reasoning samples. Reasoning samples are intentionally token-heavy, supporting thinking traces up to 16,000 tokens, and are synthesized using a graph-based generator, DataForge.
DataForge enables declarative construction of agent graphs via a directed acyclic graph (DAG) where nodes implement PDDL-style action interfaces with preconditions and postconditions. This facilitates complex, multi-stage synthetic data generation, including passage transformation, instruction generation, and answer synthesis, with rigorous LLM-based judging and iterative refinement.
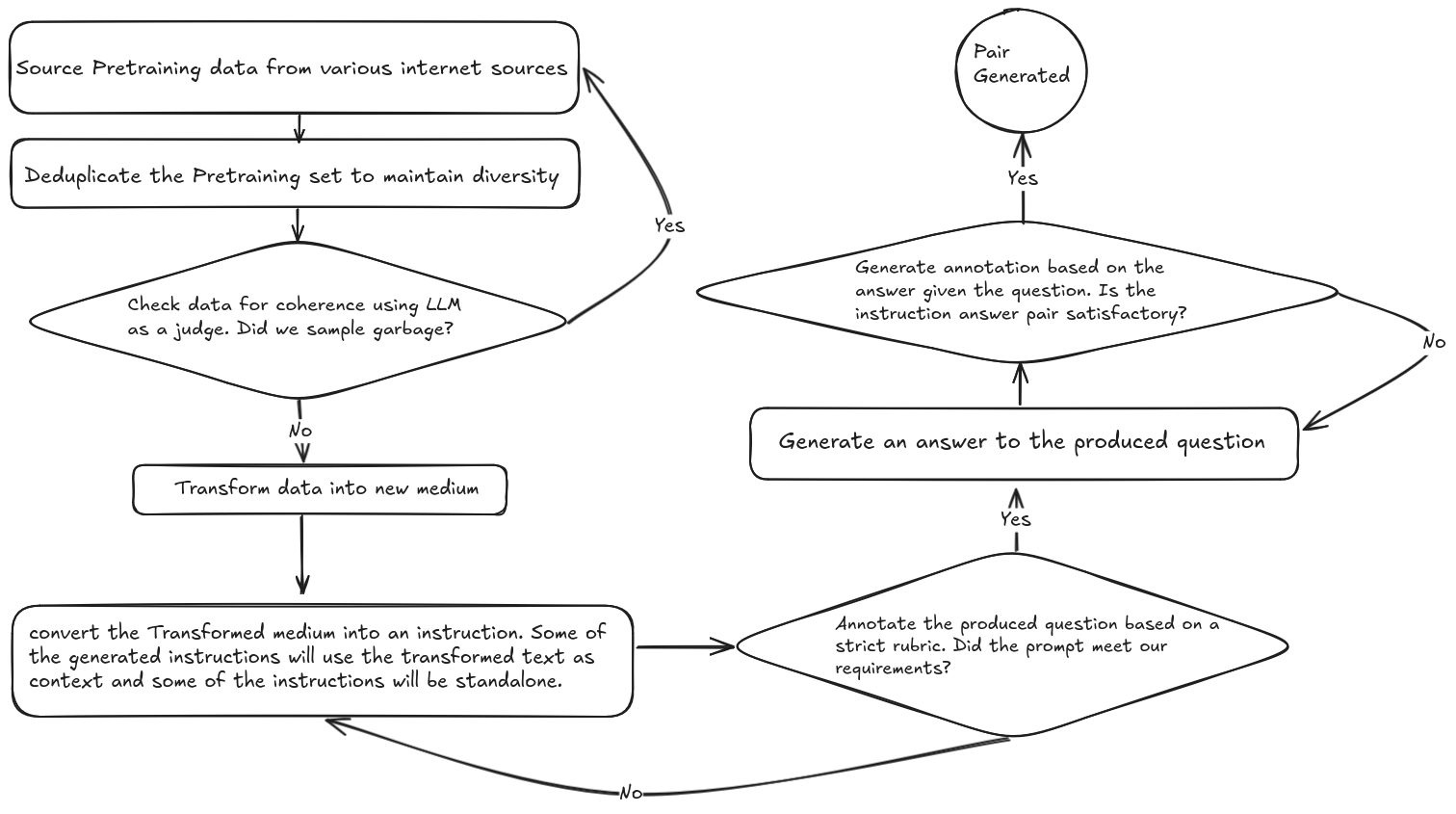
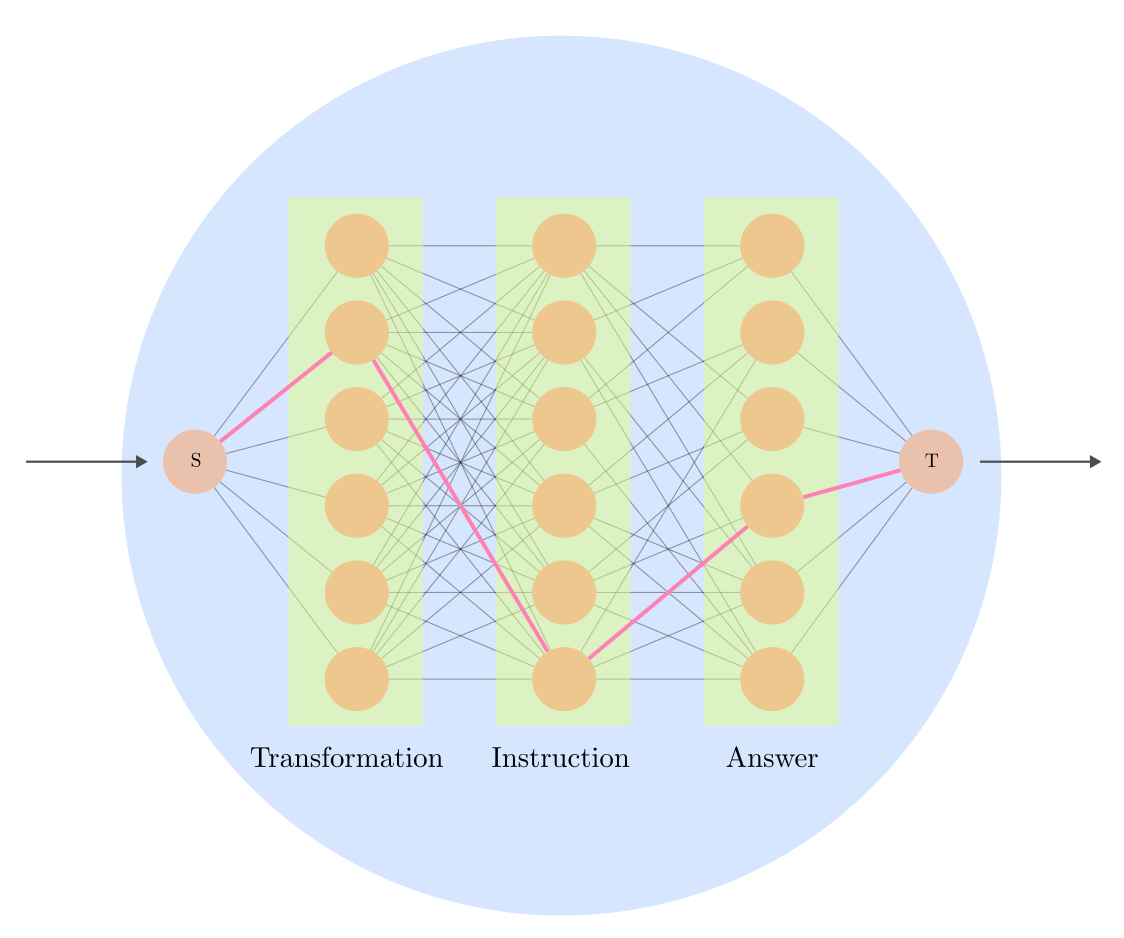
Figure 1: Example DataForge workflow illustrating multi-stage synthetic data generation via graph traversal and node composition.
The data pipeline includes semantic deduplication using ModernBert embeddings, LLM-based filtering for quality, and rejection sampling against a thousand task-specific verifiers using the Atropos RL environment manager. Multiple environments are used to generate verified reasoning trajectories, including answer format enforcement, instruction following, schema adherence, and agentic tool use with interleaved reasoning and tool calls.
Coverage of target domains is achieved via taxonomic enumeration for data-scarce areas and synthetic persona generation for user-centric domains, leveraging approaches from PersonaHub and FinePersonas.
Training Methodology
Hermes 4 is trained using a modified TorchTitan stack, starting from Llama 3.1 checkpoints for 405B and 70B models, and Qwen3 14B for the smallest variant. The training dataset exhibits high heterogeneity in sample lengths, addressed by First-Fit Decreasing packing and Flex Attention to restrict attention within samples. Only assistant-role tokens contribute to the cross-entropy loss.
Training is performed on 192 NVIDIA B200 GPUs, employing a mix of DDP, TP, and FSDP depending on model size. A cosine learning rate schedule with 300 warmup steps and 9000 total steps is used, with a global batch size of 384 and context length of 16,384 tokens.
Reasoning length control is implemented via a second-stage SFT, teaching the model to terminate reasoning at a fixed token budget (e.g., 30,000 tokens) by inserting a </think> token. This is achieved by loss-masking all but the termination token, avoiding model collapse and distribution narrowing associated with recursive synthetic data training. The approach trades a modest reduction in benchmark accuracy for a substantial decrease in overlong reasoning rates.
Evaluation Protocols
Hermes 4 is evaluated across a comprehensive suite of benchmarks: mathematical reasoning (MATH-500, AIME'24/25, GPQA Diamond), code generation (LiveCodeBench, BBH), knowledge (MMLU, MMLU-Pro, SimpleQA), alignment (IFEval, Arena-Hard, RefusalBench, RewardBench), reading comprehension (DROP, MuSR, OBQA), and creativity (EQBench3, CreativeWriting3).
Evaluation harnesses are standardized via an OpenAI-compatible chat completions endpoint, ensuring reproducibility and avoiding inference engine fragmentation. Lighteval is used for most MCQ and math tasks, EQBench for subjective evaluations, and Atropos for RL-style and custom benchmarks. LiveCodeBench evaluation is compute-optimized via Modal containers and overlapped inference-verification, maintaining inference-compute-bound throughput.
RefusalBench is introduced to measure model refusal rates across 32 prompt categories, with conditional reward inversion for safety-critical prompts. Hermes 4 demonstrates a higher refusal rate for non-safety prompts compared to proprietary and open baselines, indicating a more permissive alignment policy.
Quantitative Results
Hermes 4 405B achieves competitive or superior scores on most reasoning and code benchmarks compared to Cogito 405B, Deepseek R1/V3 671B, and Qwen3 235B. Notably, Hermes 4 405B attains:
- MATH-500: 96.3 (reasoning mode)
- AIME'24: 81.9
- GPQA Diamond: 70.5
- LiveCodeBench: 61.3
- Arena-Hard v1: 94.4
- RefusalBench: 57.1
The 70B and 14B variants also outperform comparable open-weight models in reasoning and code tasks, with the 14B model showing strong performance after length-control fine-tuning.
Qualitative Behavioral Analysis
Hermes 4 exhibits distinctive behavioral plasticity under structured qualitative probes. Standard prompting reveals reduced policy rigidity and greater contextual fidelity compared to proprietary models, with in-character responses and nuanced reasoning traces. Stylistic transfer tasks demonstrate flexible genre emulation, and system prompt customization effectively reduces sycophancy, with explicit anti-deference reasoning.
Chat template modifications (e.g., changing assistant role tokens) induce marked shifts in persona embodiment and response style, indicating high sensitivity to structural prompt cues. These latent capabilities extend beyond standard benchmarks and highlight the importance of qualitative probing in model assessment.
Implications and Future Directions
Hermes 4 demonstrates that open-weight models can achieve frontier-level reasoning and alignment performance through rigorous data synthesis, scalable training, and comprehensive evaluation. The integration of structured reasoning, instruction-following, and behavioral plasticity positions Hermes 4 as a versatile foundation for agentic and tool-augmented applications.
The release of all model weights, data, and evaluation artifacts supports reproducibility and community-driven improvement. The approach to length control and selective supervision offers a template for mitigating model collapse in synthetic data regimes. The behavioral sensitivity to prompt structure suggests avenues for controllable persona adoption and alignment tuning.
Future work may explore more granular reasoning efficiency metrics, dynamic context management, and further integration of agentic tool use. The open evaluation framework and modular data synthesis pipeline are extensible to new domains and tasks, facilitating rapid iteration and benchmarking.
Conclusion
Hermes 4 advances the state of open-weight hybrid reasoning models by combining large-scale synthetic data generation, efficient training, and rigorous evaluation. Its strong quantitative and qualitative results, coupled with transparent release practices, establish a robust foundation for research in structured reasoning, alignment, and agentic behavior in LLMs.

