- The paper presents Qwen3's innovative approach by blending dense and Mixture-of-Experts architectures with dynamic thinking and non-thinking modes.
- It details a rigorous three-stage pre-training on 36 trillion tokens across 119 languages, enhancing context length and reasoning capability.
- The evaluation demonstrates state-of-the-art performance across benchmarks, balancing activated parameters with computational efficiency.
Qwen3 Technical Report
The "Qwen3 Technical Report" provides a comprehensive overview of the Qwen3 series of LLMs, highlighting advancements in model architecture, training methodologies, and evaluation outcomes. Qwen3 presents a versatile approach by incorporating both dense and Mixture-of-Experts (MoE) architectures and spans a broad parameter scale, promoting performance efficiency and multilingual capabilities.
Model Architecture and Innovations
Qwen3 introduces an architecture blending dense and MoE models, ranging from 0.6 billion to 235 billion parameters. A key innovation is the integration of "thinking" and "non-thinking" modes, allowing dynamic switching based on task complexity without requiring multiple models. This unified approach facilitates versatility in addressing complex reasoning versus rapid response tasks.
The flagship model, Qwen3-235B-A22B, is designed to manage multiple tasks efficiently by activating 22 billion out of 235 billion parameters per token. The architecture supports enhancements such as Grouped Query Attention (GQA), SwiGLU, and Rotary Positional Embeddings with QK-Norm for training stability, removing the need for previous QKV-bias implementations.
Pre-training Paradigms
The Qwen3 models undergo a rigorous pre-training process involving approximately 36 trillion tokens across 119 languages with a three-stage strategy: general knowledge acquisition, reasoning skills enhancement, and long-context adaptability. This setup significantly boosts the model's understanding and generation capabilities, dealing with longer context inputs efficiently by extending the sequence length from 4,096 to 32,768 tokens.
The data mixture is optimized through multilingual annotations, improving domain diversity and linguistic coverage, ensuring robust cross-lingual performances.
Post-training and Dynamic Adaptability
Qwen3's post-training pipeline is illustrated in Figure 1, underscoring the adaptation mechanisms for both thinking and non-thinking modes.
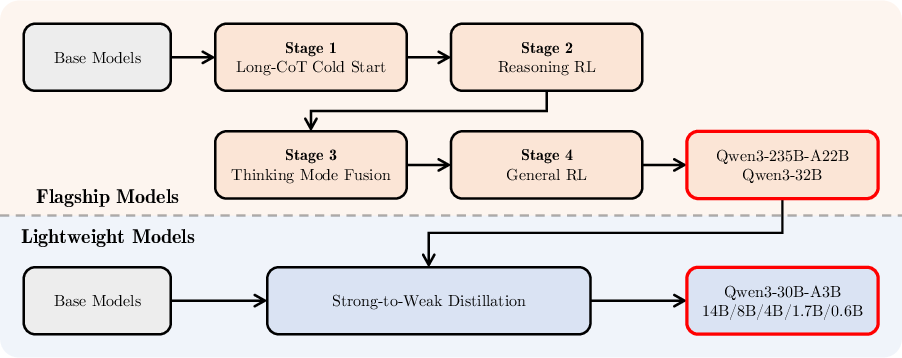
Figure 1: Post-training pipeline of the Qwen3 series models.
Through a four-stage process, the model gains refined reasoning capabilities first via "cold-start" finetuning and followed by reinforcement learning (RL). A critical highlight is the introduction of thinking budget control, whereby computational resources can be allocated based on the complexity of the task, optimizing latency and performance outcomes.
The methodology also involves strong-to-weak distillation, effectively transferring capabilities from large-scale models to lighter models, thereby ensuring training and inference efficiency with minimized computational resources. On-policy distillation diminishes training demands while sustaining high performance, as evidenced by the quantitative outcomes in varied tasks.
Empirical evaluations of Qwen3 show it achieving state-of-the-art results across a wide range of benchmarks, from mathematical reasoning to multilingual tasks. Figure 2 demonstrates the performance scalability of Qwen3-235B-A22B with variable computational investments in reasoning tasks.
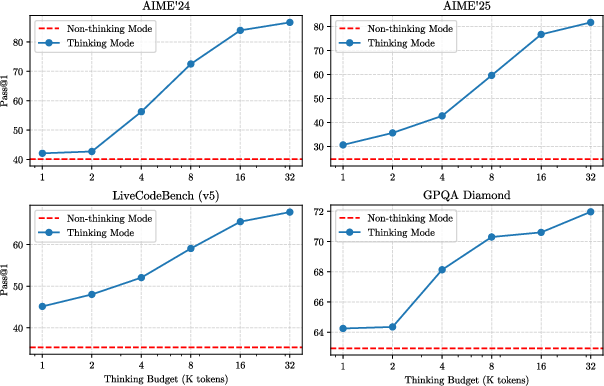
Figure 2: Performance of Qwen3-235B-A22B with respect to the thinking budget.
The model exhibits competitive outcomes in coding (e.g., CodeForces ratings), surpassing previous open-source models in inference efficiency versus activated parameter cost. This scalability confirms Qwen3's strength in balancing computational cost against the quality of outputs in real-world applications.
Conclusion
In conclusion, Qwen3 represents a robust generational leap in LLM design, marked by its innovation in mode integration and thinking budget strategies, as well as comprehensive language support and competitive benchmark performance. The research priorities moving forward encompass expanding pretraining datasets, refining architectures, and bolstering RL capabilities, with an eye toward developing even more sophisticated agent-based systems capable of handling increasingly complex and diverse cognitive tasks.

