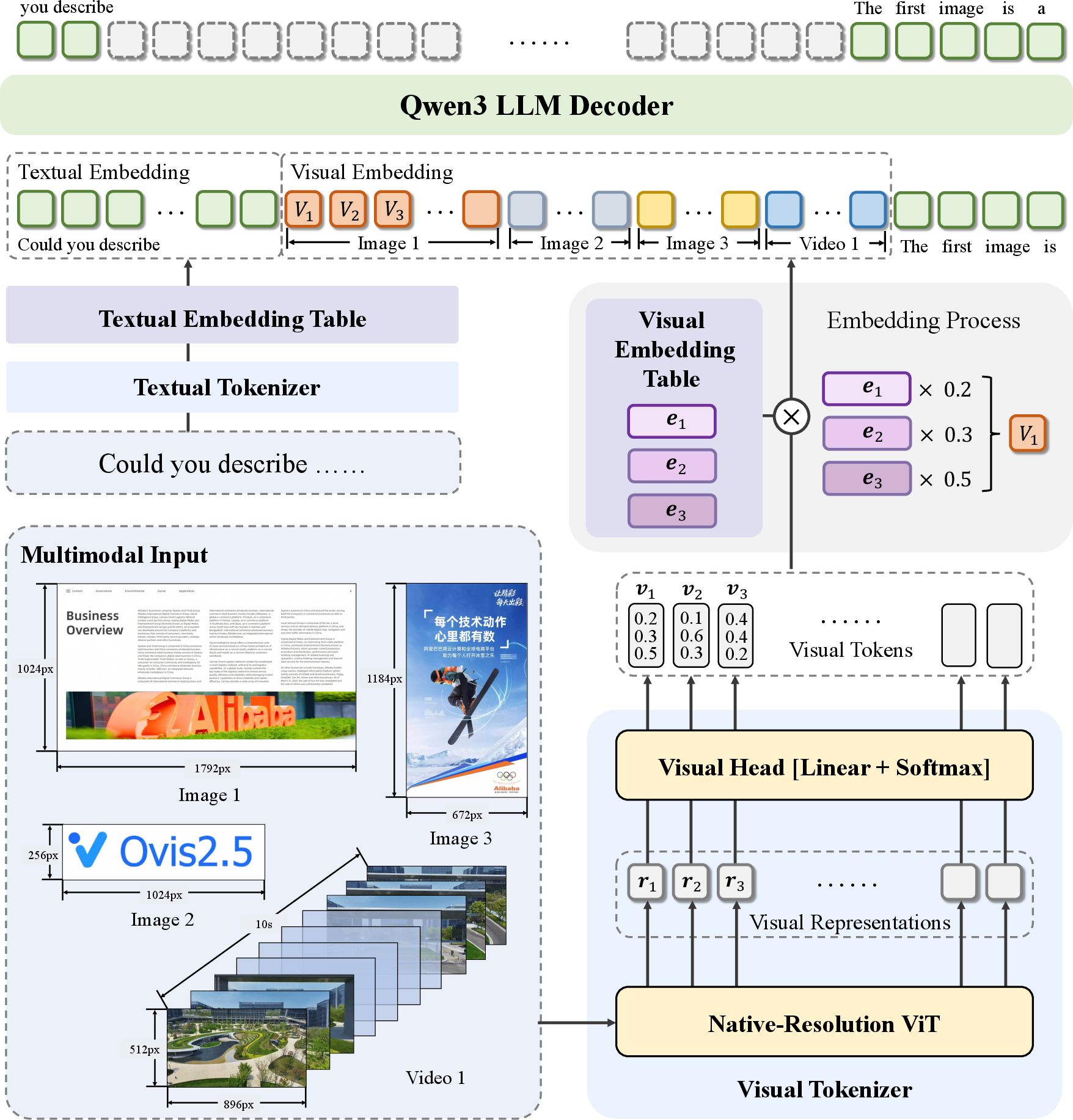
- The paper introduces a native-resolution vision transformer (NaViT) that preserves fine-grained details and global layout in images.
- The paper implements a curriculum combining linear chain-of-thought and reflective reasoning to enhance performance on complex multimodal tasks.
- The paper demonstrates state-of-the-art results, with Ovis2.5-9B scoring 78.3 on benchmarks and excelling in OCR, chart analysis, and visual grounding.
Ovis2.5: Native-Resolution Multimodal Perception and Deep Reasoning
Introduction and Motivation
Ovis2.5 advances the Ovis series of Multimodal LLMs (MLLMs) by addressing two critical limitations in prior architectures: (1) the loss of global and fine-grained visual information due to fixed-resolution image tiling, and (2) the lack of reflective, self-corrective reasoning in training objectives. The model introduces a native-resolution vision transformer (NaViT) and a curriculum that explicitly supervises both linear chain-of-thought (CoT) and reflective reasoning, culminating in an optional "thinking mode" at inference for enhanced accuracy on complex tasks.
Architectural Innovations
Ovis2.5 retains the core Ovis design: a Visual Tokenizer (VT), a Visual Embedding Table (VET), and a pretrained LLM backbone. The VT extracts patch-level features and projects them onto a discrete visual vocabulary, producing probabilistic visual tokens. The VET stores embeddings for each visual word, and the final visual embedding is the expectation over this vocabulary, weighted by VT probabilities. This design structurally aligns visual and textual embeddings, mitigating modality mismatch.
Key architectural upgrades include:
Training Pipeline and Data Strategy
Ovis2.5 employs a five-phase curriculum:
- Visual Pretraining: VET is trained on image-caption pairs, with most ViT parameters frozen. Dynamic position embedding interpolation is used for variable resolutions.
- Multimodal Pretraining: All modules are trained on OCR, captioning, and grounding data, with expanded resolution support and RoPE enabled for spatial awareness.
- Instruction Tuning: The model is exposed to diverse multimodal instructions, including text-only, multi-image, and video inputs, spanning general QA, STEM, medical, and chart analysis. "Thinking-style" samples with explicit reflection tags are incorporated.
- Direct Preference Optimization (DPO): Full-parameter training on multimodal preference data, using both vanilla CoT and reflective reasoning formats.
- Group Relative Policy Optimization (GRPO): Reinforcement learning on reasoning-centric tasks, updating only LLM parameters to preserve general multimodal capabilities.
Efficient scaling is achieved via multimodal data packing (minimizing padding and load imbalance) and a hybrid parallelism framework (combining DP, TP, and CP), yielding a 3–4× speedup in end-to-end training.
Benchmark Results and Quantitative Analysis
Ovis2.5-9B achieves an average score of 78.3 on the OpenCompass multimodal leaderboard, outperforming all open-source models in the sub-40B parameter range. Ovis2.5-2B scores 73.9, establishing SOTA for its size. The models demonstrate robust performance across general and specialized benchmarks, including STEM, chart analysis, grounding, and video understanding.
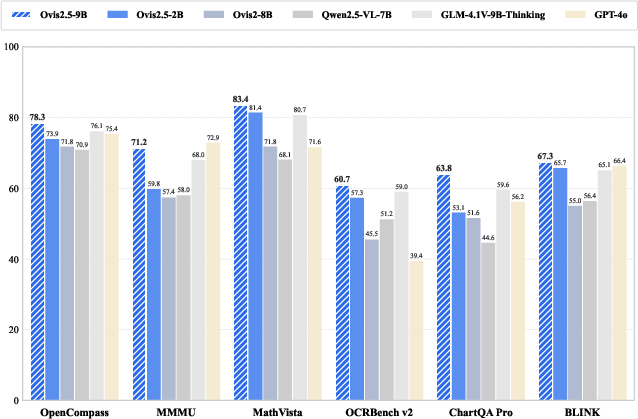
Figure 2: Benchmark performance of Ovis2.5 and its counterparts.
Multimodal Reasoning
Ovis2.5-9B ranks first or second on all major math and logic benchmarks (MathVista, WeMath, MathVerse, LogicVista, DynaMath), with 83.4 on MathVista and 71.2 on MMMU. The 2B variant also leads its class, demonstrating the efficacy of the "small model, big performance" philosophy.
OCR and Chart Analysis
On OCRBench v2, Ovis2.5-9B surpasses all open-source and proprietary competitors, including GPT-4o. It also sets new SOTA on ChartQA Pro and other chart/document benchmarks, demonstrating precise text recognition and high-level semantic reasoning.
Figure 3: An example illustrating the model's OCR capability.
Figure 4: An example illustrating the model's ability to perform a conditional search on a chart.
Visual Grounding
Ovis2.5 achieves an average score of 90.1 on RefCOCO/RefCOCO+/RefCOCOg, consistently outperforming comparable models, especially on complex referring expression tasks.

Figure 5: An example illustrating the model's ability to ground small object. The boxes are not part of the original image; they were added to visualize the coordinates generated by the model.
Multi-Image and Video Understanding
Ovis2.5-9B demonstrates strong cross-image and video reasoning, with top scores on BLINK, MMT-Bench, VideoMME, MVBench, and MLVU. The model excels in both spatial and temporal dynamics, supporting advanced sequence-level multimodal understanding.

Figure 6: An example illustrating the model's ability on video perception and reasoning.

Figure 7: An example illustrating the model's ability to generate a detailed description for a given video.
Qualitative Capabilities
The model's qualitative examples highlight its ability to:
- Identify plant species and geographic locations (Figures 3, 4)
- Solve combinatorial, geometric, and scientific reasoning problems (Figures 5, 6, 7, 8)
- Perform fine-grained OCR and text localization (Figures 9, 10, 11)
- Execute multi-step chart analysis and comparative reasoning (Figures 13, 14)
- Ground objects and captions with bounding boxes and points (Figures 15–18)
- Recognize art styles and solve jigsaw challenges (Figures 19, 20)
Implementation Considerations
- Resource Requirements: The 9B variant is suitable for server deployment, while the 2B variant is optimized for on-device scenarios.
- Inference Trade-offs: The "thinking mode" enables users to trade latency for accuracy, particularly beneficial for complex reasoning tasks.
- Scaling: The hybrid parallelism and data packing strategies are essential for efficient training and inference at scale.
- Limitations: Current perception is limited to sub-4K resolutions; long-input video and tool-augmented reasoning remain open challenges.
Implications and Future Directions
Ovis2.5 demonstrates that native-resolution perception and explicit reflective reasoning supervision are critical for advancing multimodal understanding. The model narrows the gap to proprietary systems and sets new standards for open-source MLLMs in both accuracy and efficiency. Future work should focus on scaling to higher resolutions, richer temporal reasoning, and tighter integration of external tools for action-augmented reasoning.
Conclusion
Ovis2.5 represents a significant step in multimodal model design, integrating native-resolution vision processing and deep reflective reasoning. Its state-of-the-art performance across a wide spectrum of benchmarks validates the architectural and training innovations. The release of both 9B and 2B variants enables broad deployment, from cloud to edge. Continued research should address scaling, long-context video, and tool use, further pushing the boundaries of open-source multimodal intelligence.