- The paper presents a Mixture-of-Experts architecture with 355B parameters and loss-free balance routing that enhances reasoning and coding performance.
- It employs dynamic reinforcement learning with curriculum strategies and a single-stage approach to boost long-context and agentic task performance.
- The study validates GLM-4.5’s efficiency and robustness across ARC benchmarks, outperforming competitors in agentic, code, and language tasks.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Model Architecture and Training Paradigm
GLM-4.5 introduces a Mixture-of-Experts (MoE) architecture with 355B total parameters and 32B activated parameters, accompanied by a compact variant, GLM-4.5-Air (106B/12B). The design emphasizes parameter efficiency, leveraging loss-free balance routing and sigmoid gating for MoE layers, and a deep, narrow configuration to enhance reasoning capacity. Notably, the model employs Grouped-Query Attention with partial RoPE, QK-Norm for attention stability, and a Multi-Token Prediction (MTP) layer to facilitate speculative decoding. The architecture is optimized for both computational efficiency and performance on long-context tasks, supporting sequence lengths up to 128K tokens.
Pre-training utilizes a 23T-token corpus, with rigorous data curation and up-sampling strategies for high-quality web, multilingual, code, and math/science documents. The mid-training phase extends context length and incorporates domain-specific datasets, including repo-level code, synthetic reasoning, and agentic trajectories. The Muon optimizer is adopted for scalable training, with a cosine decay learning rate schedule and batch size warmup to 64M tokens.
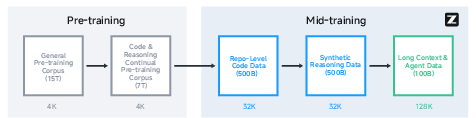
Figure 1: Multi-stage training pipeline for GLM-4.5, illustrating the extension of sequence length from 4K to 128K.
Post-Training: Expert Iteration and Reinforcement Learning
Post-training is structured into two stages: expert model specialization (Reasoning, Agent, General chat) and unified self-distillation. Supervised Fine-Tuning (SFT) is used for cold-start initialization and capability distillation, with a hybrid reasoning approach enabling both deliberative and direct response modes. The function call template is redesigned to minimize character escaping, improving agentic tool-use robustness.
Reinforcement Learning (RL) is central to capability enhancement. The GRPO framework is employed, with curriculum learning based on problem difficulty to maintain reward variance and training efficiency. Empirical results demonstrate that a single-stage RL at the target 64K context length outperforms multi-stage approaches, avoiding irreversible degradation in long-context capabilities.
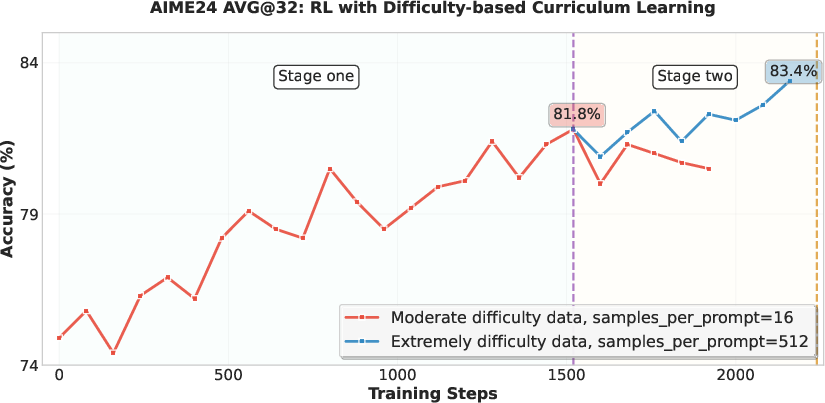
Figure 2: Two-stage curriculum RL on AIME'24, showing continued improvement when switching to extremely difficult problems.
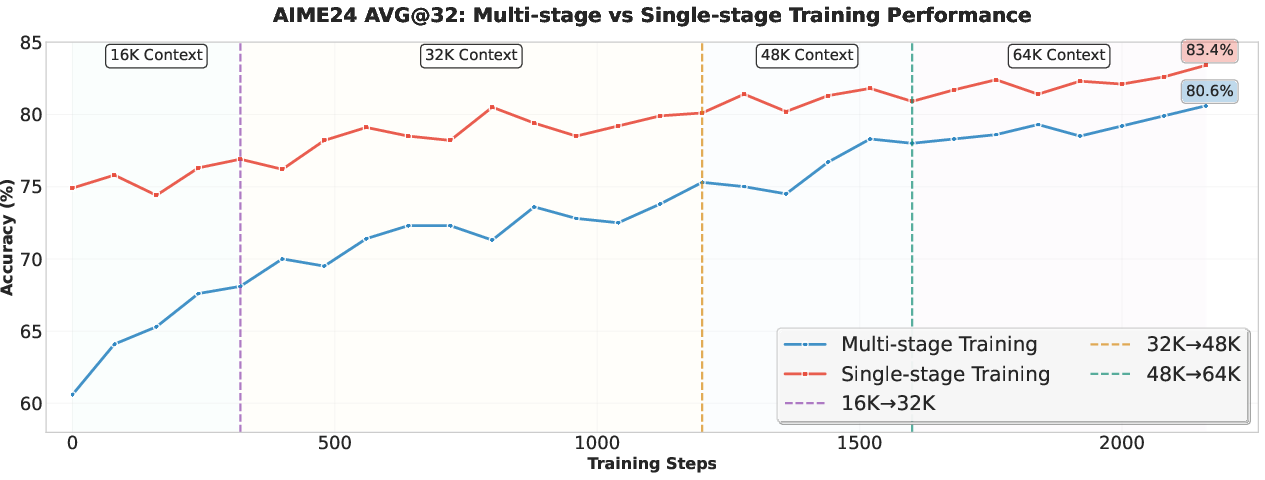
Figure 3: Single-stage RL at 64K context length yields superior performance compared to multi-stage RL.
Dynamic sampling temperature is used to balance exploration and accuracy, with periodic validation to prevent performance drops. For code RL, token-weighted mean loss accelerates convergence and mitigates length bias, while science RL benefits from exclusive use of expert-verified data.
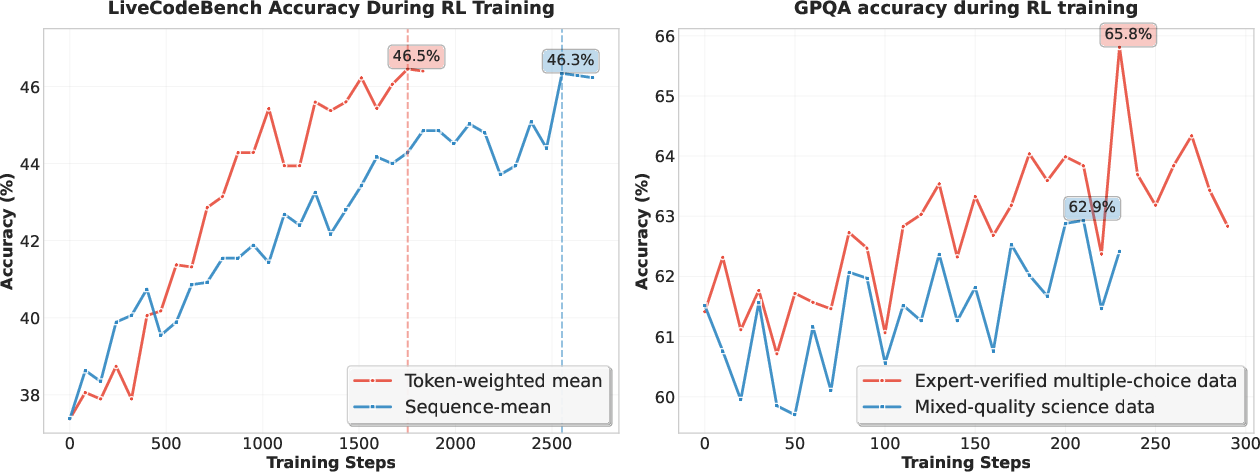
Figure 4: Token-weighted mean loss accelerates code RL convergence; expert-verified data boosts science RL performance.
Agentic RL leverages verifiable environments (web search, SWE) for dense reward signals, with iterative self-distillation to efficiently push performance limits. Test-time compute scaling via interaction turns is shown to yield smooth accuracy improvements in agentic tasks.
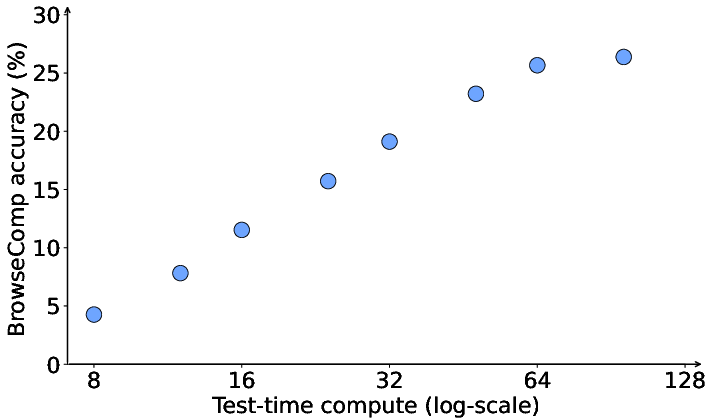
Figure 5: Accuracy in BrowseComp scales with the number of interaction turns, demonstrating effective use of test-time compute.
General RL integrates rule-based, human, and model feedback for holistic improvement, with targeted pathology RL to penalize rare but critical errors. Instruction Following RL employs a fine-grained taxonomy and hybrid feedback system, achieving steady improvements without reward hacking.
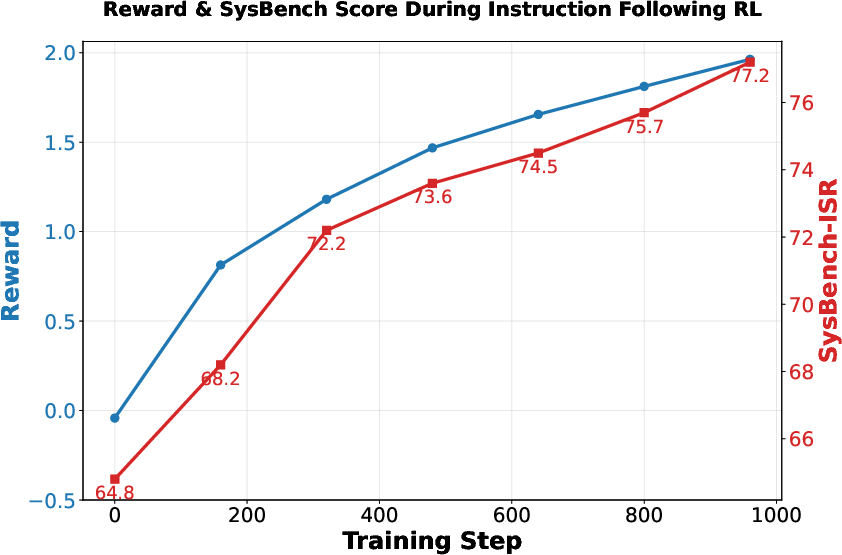
Figure 6: Instruction Following RL training curve, showing continuous improvement and absence of reward hacking.
RL Infrastructure and Scalability
The Slime RL infrastructure is engineered for flexibility and throughput, supporting synchronous and asynchronous training paradigms. Mixed-precision inference (FP8) accelerates rollouts, while a Docker-based runtime and decoupled training loop enable efficient handling of long-horizon agentic tasks. A unified HTTP endpoint and centralized data pool facilitate integration of heterogeneous agent frameworks, supporting scalable multi-task RL.
GLM-4.5 is evaluated on 12 ARC benchmarks, encompassing agentic, reasoning, and coding tasks. The model ranks 3rd overall and 2nd on agentic tasks, outperforming open-source competitors and approaching proprietary model performance.
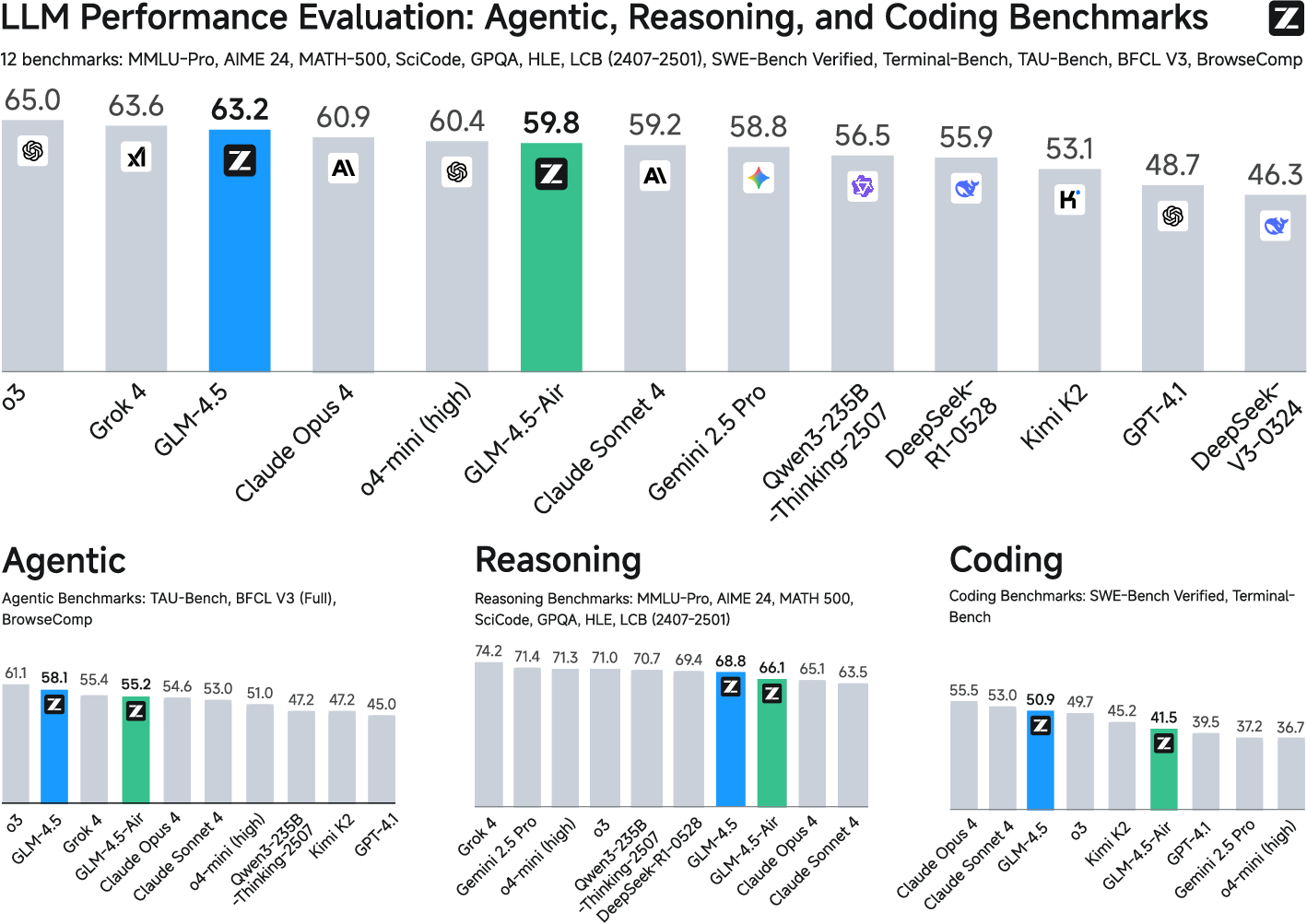
Figure 7: GLM-4.5 ranks 3rd overall and 2nd on agentic tasks across ARC benchmarks.
On SWE-bench Verified, GLM-4.5 achieves 64.2%, outperforming GPT-4.1 and Gemini-2.5-Pro, and lies on the Pareto frontier for parameter efficiency.
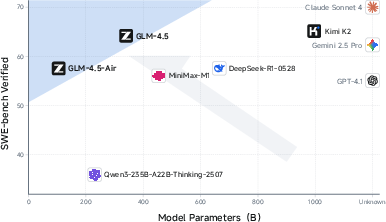
Figure 8: GLM-4.5 and GLM-4.5-Air achieve strong SWE-bench scores with fewer parameters.
Manual evaluation on diverse, real-world prompts demonstrates GLM-4.5's superior performance in English, Chinese, and other languages, particularly in mathematics, text generation, and code instructions. In agentic coding tasks (CC-Bench), GLM-4.5 exhibits high tool calling reliability (90.6%) and competitive win rates against Claude Sonnet 4 and Kimi K2.
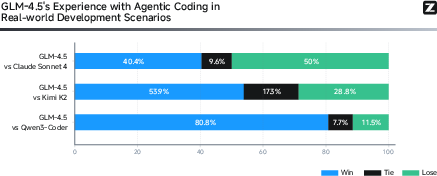
Figure 9: Head-to-head win rates for GLM-4.5 vs. Claude Sonnet 4, Kimi K2, and Qwen3-Coder on CC-Bench.
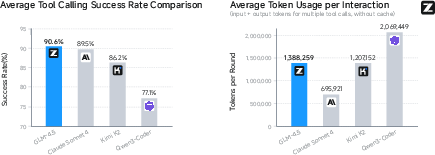
Figure 10: GLM-4.5 achieves the highest tool calling success rate and efficient token usage on CC-Bench.
Logical reasoning evaluation on novel problems shows GLM-4.5 performing on par with leading models. In translation, GLM-4.5 significantly outperforms specialized models on challenging, context-dependent cases, underscoring the importance of knowledge and reasoning in modern translation tasks.
Safety and Alignment
GLM-4.5 demonstrates robust safety alignment on SafetyBench, with an overall score of 89.9, competitive with GPT-4.1 and Kimi K2. The model excels in Ethics, Mental Health, and Physical Health categories, though further improvement is needed in Unfairness and Bias.
Implications and Future Directions
GLM-4.5 advances the state of open-source LLMs by unifying agentic, reasoning, and coding capabilities in a parameter-efficient MoE framework. The hybrid reasoning paradigm, curriculum RL, and scalable infrastructure collectively enable strong performance across diverse tasks and long-context scenarios. The release of model weights and evaluation toolkits facilitates reproducibility and further research.
Practically, GLM-4.5's architecture and training strategies provide a blueprint for efficient scaling and specialization in LLMs, with implications for agentic AI systems, code generation, and multi-lingual applications. The demonstrated gains in tool-use reliability and translation suggest broader applicability in real-world automation and knowledge-intensive domains.
Theoretically, the results highlight the importance of curriculum design, dynamic RL strategies, and data quality in scaling LLM capabilities. The observed trade-offs between depth and width, and the impact of long-context conditioning, inform future model design. Further research may explore more granular expert specialization, adaptive RL schedules, and enhanced safety alignment.
Conclusion
GLM-4.5 and GLM-4.5-Air represent a significant step in open-source LLM development, achieving competitive performance in agentic, reasoning, and coding tasks with efficient resource utilization. The model's architecture, training pipeline, and evaluation results provide valuable insights for both practical deployment and future research in generalist AI systems.