- The paper introduces PACS, which reformulates RLVR as a supervised learning problem to enable implicit actor-critic coupling.
- It integrates reward proxy computation, group advantage estimation, and cross-entropy loss to achieve stable gradient updates and efficient credit assignment.
- Empirical results on mathematical reasoning benchmarks reveal that PACS significantly outperforms methods like PPO and GRPO with notable improvements in pass@256 rates.
Implicit Actor Critic Coupling via a Supervised Learning Framework for RLVR
Introduction
This paper introduces PACS, a novel framework for Reinforcement Learning with Verifiable Rewards (RLVR) that reformulates policy optimization for LLMs as a supervised learning problem. RLVR has become central to post-training LLMs for complex reasoning tasks, particularly in mathematics and programming, where outcome rewards are sparse and only available after generating complete responses. Existing RLVR methods, such as PPO and GRPO, either rely on explicit value modeling or Monte Carlo estimation, both suffering from instability and inefficiency due to the sparse reward structure. PACS addresses these limitations by treating outcome rewards as predictable labels and optimizing a score function parameterized by the policy model using cross-entropy loss, thereby achieving implicit actor-critic coupling.
The core innovation of PACS is the recasting of RLVR as a supervised learning task. Instead of optimizing the policy via RL from sparse outcome rewards, PACS interprets the reward as a supervision signal and trains a score function to predict this reward using cross-entropy loss. This approach enables direct credit assignment and stable gradient propagation, circumventing the high variance and instability of RL-based methods.
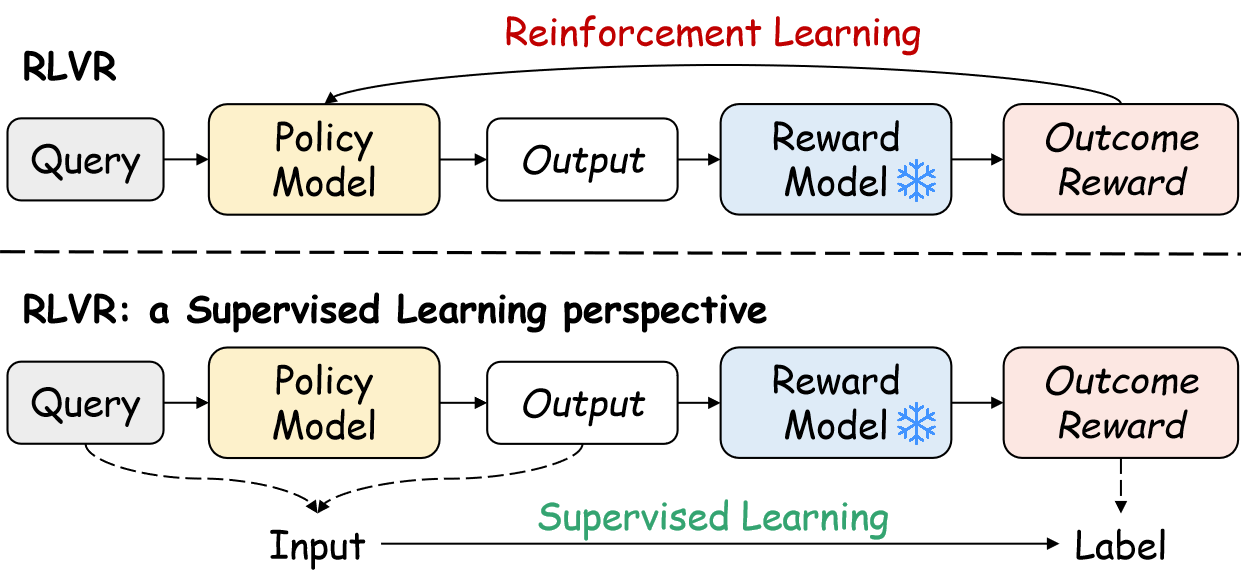
Figure 1: Comparison between RLVR and the supervised learning reformulation, where the query and output are input, and the outcome reward is treated as a predictable label.
The PACS framework consists of three main components:
- Reward Proxy Computation: Calculates a reward proxy r^ based on log-probability ratios between the policy and a reference policy.
- Group Computation: Computes RLOO-based advantage scores ψ from the reward proxies, enabling relative quality assessment within a batch.
- Cross-Entropy Loss: Converts the RLVR problem into a supervised learning task, optimizing the scoring function with cross-entropy loss.
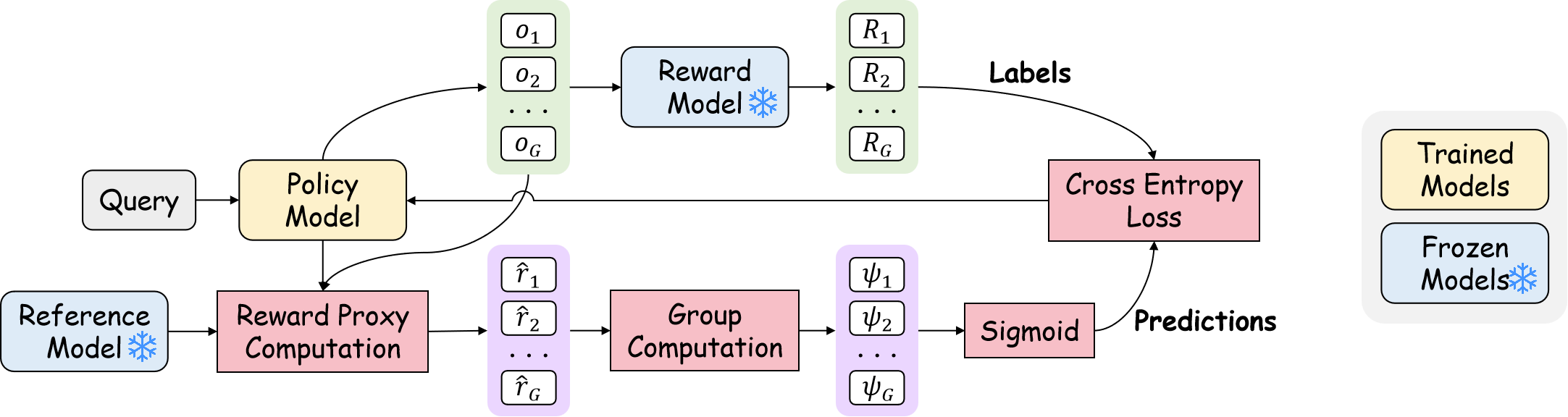
Figure 2: An illustration of the PACS framework, showing reward proxy computation, group advantage calculation, and supervised cross-entropy optimization.
Gradient Analysis and Implicit Actor-Critic Coupling
A detailed gradient analysis reveals that the supervised learning objective inherently recovers the classical policy gradient update and unifies actor (policy improvement) and critic (reward estimation) roles within a single update. The gradient of the loss decomposes into two terms:
- Actor: Weighted policy gradient update, modulated by the per-sample cross-entropy loss.
- Critic: Supervised reward estimation correction, aligning the score function's prediction with the ground-truth reward.
This implicit coupling eliminates the need for separate networks or alternating update schedules, facilitating efficient and stable training. The score function ψ(q,o;πθ) is instantiated using the RLOO estimator, which provides robust credit assignment by comparing each sample against the cohort average.
Experimental Results
Extensive experiments are conducted on four mathematical reasoning benchmarks (MATH 500, AMC23, AIME 2024, AIME 2025) using Qwen2.5-3B and Qwen2.5-7B models. PACS consistently outperforms PPO and GRPO across all datasets and model scales. On AIME 2025, PACS achieves a pass@256 rate of 59.78%, representing improvements of 13.32 and 14.36 points over PPO and GRPO, respectively. The results demonstrate PACS's superior generalization, stability, and efficiency, especially in high-difficulty, sparse-reward settings.
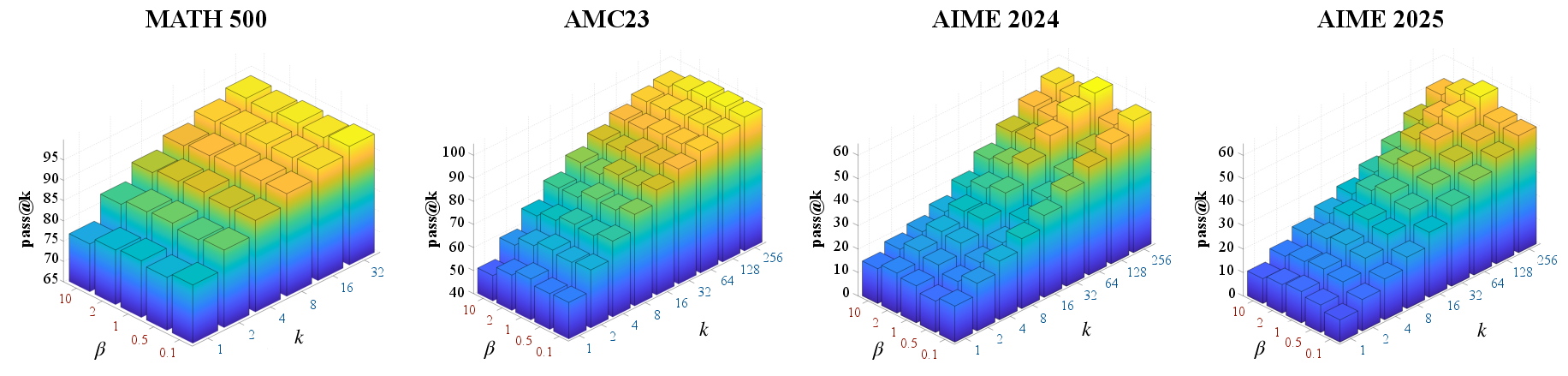
Figure 3: Performance analysis of PACS with varying β. The 3D heatmaps show pass@k scores for different combinations of β values and k values on four datasets.
Ablation studies confirm the critical importance of the weighting mechanism and the choice of advantage estimator. PACS with RLOO advantage estimation exhibits the strongest performance, particularly on the most challenging benchmarks. The β hyperparameter is shown to be crucial for optimal performance on complex tasks, with β=1 yielding the best results.
Training Dynamics
Training dynamics analysis reveals that PACS maintains higher policy entropy and gradient norms compared to PPO and GRPO, indicating a healthier exploration-exploitation balance and more aggressive parameter updates. PACS generates longer, more detailed responses, further evidencing its superior optimization characteristics.
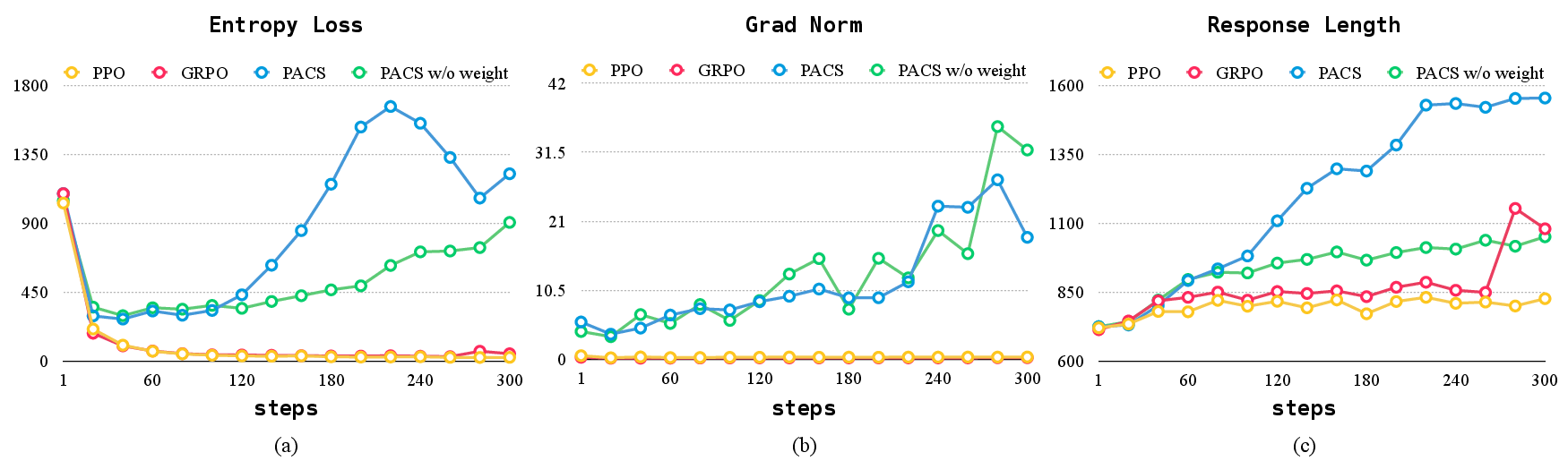
Figure 4: Training dynamics of Qwen2.5-7B on DeepScaleR across different optimization methods, showing entropy loss, gradient norm, and mean response length.
Implementation Considerations
PACS is implemented using verl for training and vllm for inference, leveraging efficient batch sampling and high-throughput serving. The framework is compatible with large-scale LLMs and can be scaled across multiple GPUs. Key hyperparameters include batch size, learning rate, rollout number, and β for reward proxy scaling. Periodic hard-resetting of the reference policy is employed to stabilize training. The supervised learning formulation enables straightforward integration with existing LLM training pipelines and facilitates rapid experimentation.
Theoretical and Practical Implications
The implicit actor-critic coupling via supervised learning represents a significant shift in RLVR optimization, offering a principled solution to the sparse reward and instability issues inherent in RL-based approaches. The unified gradient update and shared parameterization streamline training and improve sample efficiency. The robust performance of PACS across diverse benchmarks suggests broad applicability to other domains with verifiable rewards, such as code generation and scientific reasoning.
Future Directions
Potential future developments include extending PACS to multi-modal reasoning tasks, integrating more sophisticated reward proxies, and exploring adaptive weighting mechanisms for further stability. The framework's compatibility with large-scale distributed training and its open-source implementation facilitate adoption and further research.
Conclusion
PACS introduces a supervised learning-based approach to RLVR, achieving implicit actor-critic coupling and addressing the fundamental challenges of sparse rewards and training instability. Empirical results demonstrate substantial improvements over state-of-the-art RLVR methods, with strong generalization and efficiency across mathematical reasoning tasks. The theoretical insights and practical implementation of PACS provide a promising direction for advancing LLM post-training with verifiable rewards.

