Nemori: Self-Organizing Agent Memory Inspired by Cognitive Science
Abstract: LLMs demonstrate remarkable capabilities, yet their inability to maintain persistent memory in long contexts limits their effectiveness as autonomous agents in long-term interactions. While existing memory systems have made progress, their reliance on arbitrary granularity for defining the basic memory unit and passive, rule-based mechanisms for knowledge extraction limits their capacity for genuine learning and evolution. To address these foundational limitations, we present Nemori, a novel self-organizing memory architecture inspired by human cognitive principles. Nemori's core innovation is twofold: First, its Two-Step Alignment Principle, inspired by Event Segmentation Theory, provides a principled, top-down method for autonomously organizing the raw conversational stream into semantically coherent episodes, solving the critical issue of memory granularity. Second, its Predict-Calibrate Principle, inspired by the Free-energy Principle, enables the agent to proactively learn from prediction gaps, moving beyond pre-defined heuristics to achieve adaptive knowledge evolution. This offers a viable path toward handling the long-term, dynamic workflows of autonomous agents. Extensive experiments on the LoCoMo and LongMemEval benchmarks demonstrate that Nemori significantly outperforms prior state-of-the-art systems, with its advantage being particularly pronounced in longer contexts.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper tackles a big problem in today’s chat AIs: they’re great at responding in the moment, but they forget across long or repeated conversations. The authors introduce Nemori, a new “memory system” that helps an AI remember, organize, and learn from past chats—more like a person would.
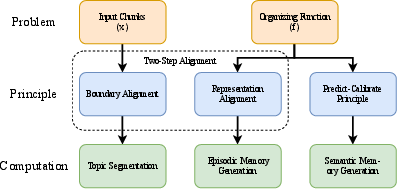
Nemori is built on two simple, brain-inspired ideas:
- Two-Step Alignment: split a long chat into meaningful “episodes” (like scenes in a movie), then turn each episode into a clear, short story.
- Predict-Calibrate: have the AI guess what an episode should contain based on what it already knows, then compare that guess to the real conversation to learn new facts it missed.
Together, these let the AI keep useful memories, forget clutter, and get smarter over time.
What questions are the researchers asking?
They focus on four easy-to-understand questions:
- Can Nemori help an AI remember and use important information in long chats better than other systems?
- Which parts of Nemori matter most for good performance?
- How many past memories does the AI actually need to retrieve to answer well?
- Does Nemori still work when conversations become extremely long and realistic?
How does Nemori work?
Think of Nemori as a neat combination of a diary and a fact notebook, plus a smart study routine.
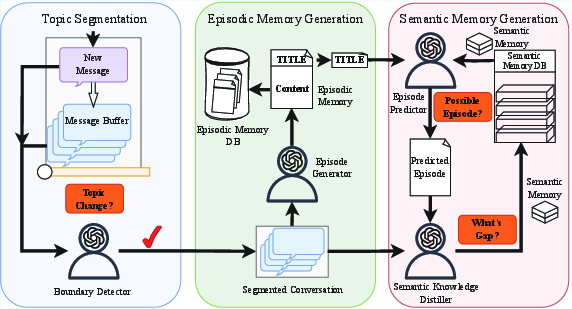
Step 1: Split the chat into episodes (like movie scenes)
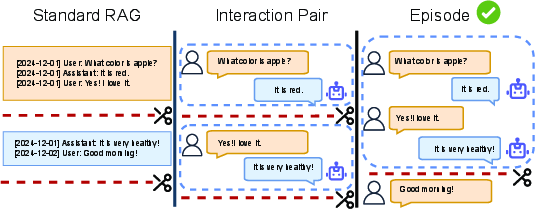
Long chats jump between topics. Nemori uses an AI “boundary detector” to spot when the conversation changes subject or purpose. When it sees a clear shift (or when a temporary buffer gets full), it cuts the chat there. Each chunk is an episode that stays semantically coherent—like keeping an entire “apple discussion” together instead of breaking it in the middle.
Why this helps: If you slice conversations at random places, you lose context. Grouping by meaning keeps the storyline intact.
Step 2: Turn each episode into a short, readable story
For each episode, Nemori creates:
- a short title (what this episode is about), and
- a third-person narrative summary (what happened and why it matters).
This is called Representation Alignment. It preserves the important details and context in a human-friendly way—like writing a journal entry you can quickly scan later.
Why this helps: Clear titles and summaries make retrieval faster and reduce confusion.
Step 3: Learn facts by “guessing, then checking” (Predict-Calibrate)
This is Nemori’s “study routine,” inspired by how people learn better by trying first, then comparing with the answer key.
- Prediction: Given a new episode’s title and what the AI already knows, Nemori predicts what the content will be. It first pulls related memories (using meaning-based search), then tries to “fill in” the episode.
- Calibration: It compares the prediction to the actual conversation for that episode and looks for differences—these are “gaps,” or new things the AI didn’t know.
- Integration: It turns those new bits into clean, reusable facts and adds them to the semantic memory (the fact notebook).
Over time, this loop builds a high-quality knowledge base from lived conversations—without just copying everything.
Finding the right memories quickly
Nemori uses meaning-based search (vector retrieval) to find relevant episodes and facts. Instead of exact keyword matches, it looks for information that “means the same thing,” even if the words differ.
Why this helps: When answering a new question, the AI can pull just the most relevant pieces, staying accurate without wading through thousands of tokens.
What did they find?
The team tested Nemori on two challenging benchmarks:
- LoCoMo: long chats with various question types.
- LongMemEvalₛ: much longer, more realistic conversations (around 105,000 tokens on average).
Here’s what stood out:
- Higher accuracy than other systems: Nemori beat popular baselines (like standard RAG and other memory systems) and, in some cases, even outperformed giving the model the entire conversation history. It was especially strong at time-related questions (temporal reasoning), because its episodes keep events in order and its facts turn relative times (like “yesterday”) into exact dates.
- Much more efficient: On LoCoMo, Nemori used about 88% fewer tokens than feeding the full chat, while still answering better. On the very long LongMemEvalₛ, it used about 95–96% less context and still improved average accuracy.
- Both memory types matter: Removing episodic memories (stories) or semantic memories (facts) made the system worse. They’re complementary—stories preserve context and flow; facts make reasoning quicker.
- “Guess-and-check” learning works: The Predict-Calibrate approach produced better knowledge than simply extracting facts directly from the chat. Learning from prediction gaps makes the AI’s knowledge cleaner and more useful.
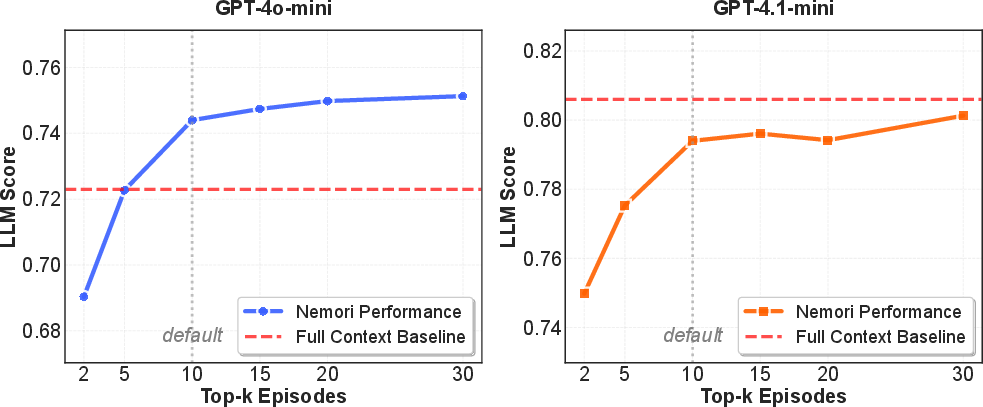
- You don’t need to retrieve everything: Performance improved quickly as the system retrieved more episodes, then flattened after about 10. That means you can keep retrieval small and still do great.
Why does this matter?
Nemori shows a practical path to AI that:
- remembers meaningful things about you and past interactions,
- learns over time from real conversations,
- stays efficient, so it’s cheaper and faster to run,
- and handles very long, dynamic workflows without drowning in text.
This could make virtual assistants more personal and reliable, research copilots more consistent across sessions, and autonomous agents more capable of long-term planning and adaptation. In short, Nemori moves AI memory from “just storing stuff” to “actively understanding and evolving”—a key step toward AI that can truly grow with its users.
Collections
Sign up for free to add this paper to one or more collections.