- The paper presents a novel method transforming passive video diffusion models into causal, action-conditioned world models that excel in interactive simulations.
- It integrates causal generation and frame-level action conditioning to overcome data inefficiencies and enhance prediction fidelity.
- Experimental results show state-of-the-art performance on robotics and CS:GO tasks using advanced metrics like FVD and LPIPS.
Vid2World: Crafting Video Diffusion Models to Interactive World Models
Introduction
The paper "Vid2World: Crafting Video Diffusion Models to Interactive World Models" (2505.14357) presents a novel approach to transform video diffusion models into interactive world models. The primary objective is to leverage pre-trained video diffusion models to improve data efficiency and fidelity in complex environment simulations, which pose challenges for existing world models in terms of domain-specific training and prediction quality.
World models are critical in sequential decision-making scenarios, capable of predicting future states based on history and actions. Despite success in various applications like robotics and autonomous driving, these models often suffer from excessive data demands and limited prediction fidelity. Video diffusion models, conversely, excel in generating high-fidelity visual sequences using vast datasets. Integrating these capabilities into world models can potentially address the shortcomings noted in traditional approaches, thereby enhancing the utility of interactive simulations.
Methodology
Vid2World aims to bridge the gap between passive video diffusion models and active world models. This transformation involves two key technical challenges: causal generation and action conditioning.
- Causal Generation: Traditional video diffusion models generate sequences using bidirectional context across time, which is unsuitable for scenarios requiring predictions based solely on past information. Vid2World reconciles this by employing causal masks and reparameterizing temporal attention mechanisms, ensuring autoregressive generation akin to temporal Markov processes (Figure 1).
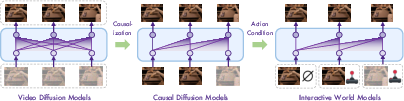
Figure 1: Transforming video diffusion models into interactive world models involves two key challenges: (1) Causal generation: converting full-sequence diffusion models into causal diffusion models; (2) Action conditioning: adapting causal diffusion models into an interactive world model.
- Action Conditioning: To accommodate interactive modeling, Vid2World implements frame-level action conditioning. It adopts causal action guidance through architectural modifications that inject frame-specific actions, supporting counterfactual reasoning and enhancing response sensitivity to actions rather than static conditions (Figure 2).
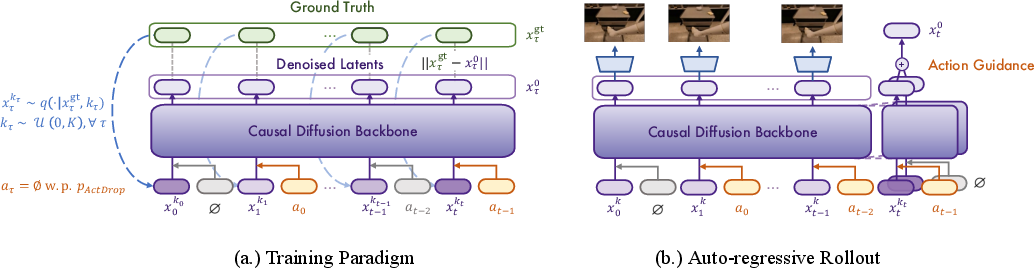
Figure 2: Training and Sampling of Vid2World. (a.) During training, we add independently sampled noise levels to each frame, as well as randomly droping out each action with a fixed probability. (b.) For auto-regressive rollout, we denoise the latest frame while setting history clean. Action guidance is added for the current action. See Appendix \ref{app:model_detail for details.
Experimental Results
Extensive experiments were conducted, demonstrating Vid2World's effectiveness in domains such as robotics and game simulation. Particularly impressive are the improvements in fidelity and prediction accuracy over existing methods in both settings. In robot manipulation tasks using the RT-1 dataset, Vid2World exceeds other transformation techniques in metrics like Fréchet Video Distance (FVD) and Learned Perceptual Image Patch Similarity (LPIPS).
Vid2World also excels in the highly dynamic CS:GO environment, achieving state-of-the-art results compared to DIAMOND, a leading autoregressive world model. These experiments highlight Vid2World's capabilities in delivering high-quality, action-conditioned video predictions essential for simulations requiring robust, real-time interactivity (Figure 3, Figure 4).

Figure 3: Video Prediction Results of Vid2World on RT-1 and CS:GO. Zoom in for details. Extended examples can be found in Appendix \ref{app:c.

Figure 4: Comparison between Ground truth and Generated videos by Vid2World
Implications and Future Work
Vid2World offers significant practical and theoretical implications. Practically, it enhances the fidelity of interactive simulations crucial for robotics and AI, allowing for more realistic training environments without extensive data gathering. Theoretically, it addresses critical challenges in adapting generative models for causal and interactive tasks, pushing forward the boundaries of current sequential decision-making methods.
Future research could explore scaling this approach to larger models and datasets, improving efficiency, and further refining the action conditioning mechanisms for even finer control and prediction accuracy in diverse application domains.
Conclusion
The paper establishes Vid2World as a robust method for transforming video diffusion models into effective interactive world models. It opens pathways for leveraging high-fidelity video data to enhance interactive simulations, setting a new benchmark in the field of sequential decision-making and interactive modeling. Through well-crafted architectural and procedural modifications, Vid2World exhibits substantial potential to influence and improve how simulations and training systems are built and utilized.
