Dexterous World Models
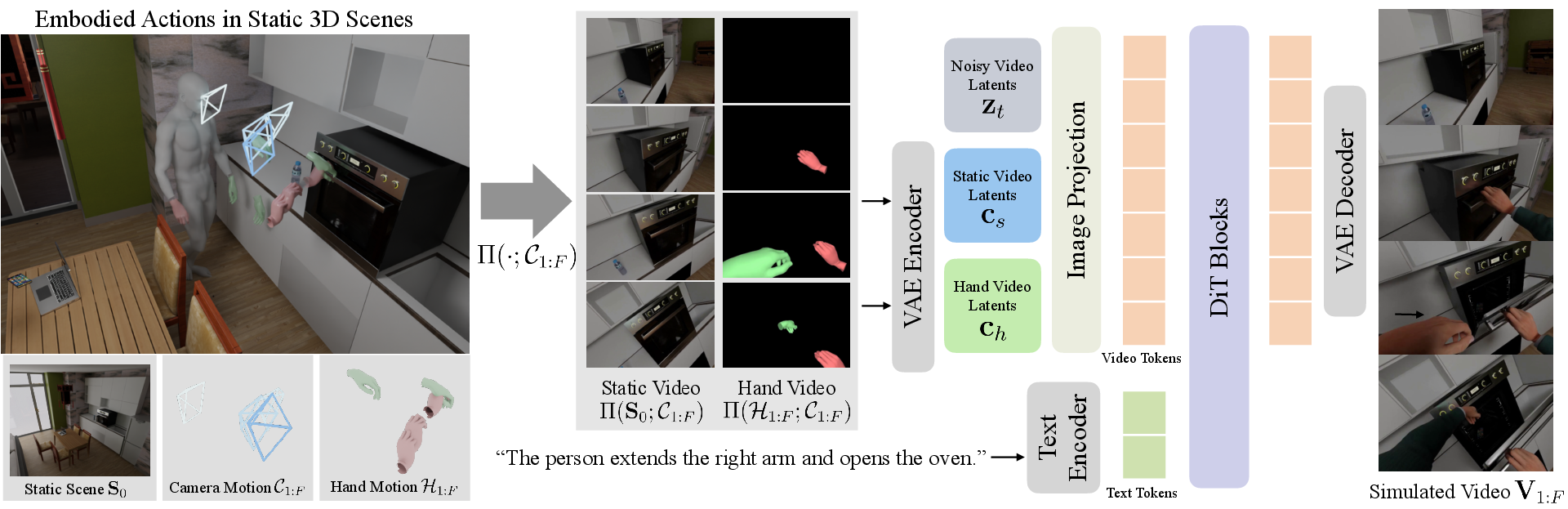
Abstract: Recent progress in 3D reconstruction has made it easy to create realistic digital twins from everyday environments. However, current digital twins remain largely static and are limited to navigation and view synthesis without embodied interactivity. To bridge this gap, we introduce Dexterous World Model (DWM), a scene-action-conditioned video diffusion framework that models how dexterous human actions induce dynamic changes in static 3D scenes. Given a static 3D scene rendering and an egocentric hand motion sequence, DWM generates temporally coherent videos depicting plausible human-scene interactions. Our approach conditions video generation on (1) static scene renderings following a specified camera trajectory to ensure spatial consistency, and (2) egocentric hand mesh renderings that encode both geometry and motion cues to model action-conditioned dynamics directly. To train DWM, we construct a hybrid interaction video dataset. Synthetic egocentric interactions provide fully aligned supervision for joint locomotion and manipulation learning, while fixed-camera real-world videos contribute diverse and realistic object dynamics. Experiments demonstrate that DWM enables realistic and physically plausible interactions, such as grasping, opening, and moving objects, while maintaining camera and scene consistency. This framework represents a first step toward video diffusion-based interactive digital twins and enables embodied simulation from egocentric actions.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Dexterous World Models — Simple Explanation
Brief Overview
This paper introduces a system called Dexterous World Models (DWM). Its goal is to make “digital twins” (virtual copies of real places) feel interactive and alive. Instead of just showing different camera views of a room, DWM predicts what happens when a person actually uses their hands to touch, move, or open things. Given a static 3D scene and a first‑person (egocentric) hand motion, it generates a realistic video of the scene changing because of the person’s actions.
Key Objectives and Questions
Here are the main things the researchers wanted to achieve:
- Can we predict how a scene changes when someone manipulates objects with their hands, while keeping the rest of the scene stable?
- Can we keep the camera motion consistent (as if from a person’s viewpoint) and avoid “re‑inventing” the static background every time?
- Can the model learn from both synthetic (computer‑generated) and real videos to handle diverse, realistic interactions?
- Can this model be used to “try out” different actions and pick the one that best matches a goal (like opening a door or placing an item)?
Methods and Approach (Explained Simply)
Think of DWM like a smart, first‑person movie director:
- It takes two inputs: 1) A video of what a static scene would look like from a moving camera path (for example, you walking through a room without touching anything). 2) A video-like rendering of your hands in 3D (their shape and motion) from the same camera path.
- Then it produces a new video showing what would realistically happen when those hands interact with the environment.
Key ideas, with everyday analogies:
- Egocentric view: This is the first‑person view—like wearing a camera on your head—so the model sees what you would see.
- Diffusion model: Imagine starting with noisy, unclear video frames and repeatedly “cleaning them up,” guided by the inputs. This process is good at generating realistic motion and textures.
- Residual dynamics: Rather than re‑creating the whole video from scratch, DWM tries to change only the parts caused by the hand actions (like the handle turning or the object moving), leaving the rest untouched. Think of it like editing only the “action parts” of a clip while keeping the background identical.
- Inpainting prior: They start from a model trained to “fill in” missing video parts. When everything is “visible,” this model learns to act almost like an identity function—copying the input video faithfully. DWM builds on this so the static scene remains steady, and only the action‑induced changes are synthesized.
- Training data:
- Synthetic paired data: From a simulation (TRUMANS), they can perfectly align the static scene video, the hand video, and the interaction video under the same camera path. This provides clean, exact supervision.
- Real fixed‑camera videos: Real interactions (TASTE‑Rob) add rich, realistic physics—like soft materials, liquids, or subtle motion—even though the camera doesn’t move.
- Special real‑world evaluation: They used AR glasses to capture moving first‑person videos and built paired static/interaction sequences to test the model in realistic scenarios.
- Action evaluation: DWM can simulate different candidate actions and score which one best matches a given goal (a text instruction or a target image). It picks the action whose predicted video lines up best with that goal.
Main Findings and Why They Matter
The researchers tested DWM against strong baselines (methods that edit videos or inpaint regions with text guidance). They found:
- DWM produces more realistic, physically plausible interactions—like grasping, opening, sliding, and moving objects—while keeping the camera motion and scene appearance stable.
- It separates “moving the camera” (navigation) from “using hands to change things” (manipulation). Without hand input, it just shows navigation; with hand input, it adds correct object changes.
- It generalizes to new, real‑world settings—even those not seen during training—such as opening windows and operating articulated objects.
- It consistently beats baselines on both perceptual similarity (how “close” the video looks to the real one) and pixel‑level quality metrics, across synthetic and real data.
- Including real‑world training data (even with fixed cameras) helps the model handle complex, realistic dynamics during testing with moving cameras.
These results matter because they show a path to truly interactive digital twins: the model can predict specific, fine‑grained changes caused by human hands, not just re‑create static views.
Implications and Potential Impact
- Interactive digital twins: DWM moves beyond static virtual environments to ones where your actions cause believable changes—useful for training, design, and simulation.
- Robotics and planning: By simulating outcomes for different hand actions and scoring them, DWM can help choose the best action to reach a goal, reducing trial‑and‑error on real robots.
- AR/VR experiences: First‑person, action‑aware simulations can make virtual environments more immersive and useful for learning physical tasks.
- Research foundation: The approach of conditioning on a static scene plus hand motion, and focusing on residual changes, offers a clean, causal way to model how human actions change the world.
In short, Dexterous World Models provide a new, practical way to simulate what happens when we use our hands in a known environment—bringing us closer to interactive, realistic digital worlds that respond to our actions.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper. Each point is phrased to be concrete and actionable for future research.
- Object-level state modeling is absent: the model predicts pixels but not explicit object identities, articulation states, or contact events. Incorporate object-centric representations (e.g., instance segmentation, part articulation graphs, contact maps) and evaluate state-tracking accuracy alongside video realism.
- Physical correctness is not guaranteed: dynamics are purely learned from data without explicit physics constraints. Integrate differentiable physics or constraint-based priors (e.g., rigid-body, joint limits, friction) and design metrics for physical plausibility and violation rates.
- No force/tactile conditioning: hand-mesh conditioning encodes pose/geometry but not forces, torques, or compliance. Add force/torque profiles, grasp pressure, or haptic signals and study their impact on controllability and realism of contact-rich interactions.
- Residual-learning bias may suppress large scene changes: initializing from an inpainting identity prior could under-edit when interactions require substantial state changes (e.g., large object motion, deformation, fluids). Ablate this prior, quantify edit magnitude bias, and develop mechanisms that adaptively switch from identity preservation to larger edits.
- Fixed assumption of a “known static scene” is fragile: the approach presumes an accurate, immutable digital twin; real scenes often differ (missing objects, moved items, lighting changes). Measure sensitivity to twin-scene mismatches and develop online twin updates or robustness strategies (e.g., uncertainty-aware conditioning).
- Egocentric camera dependency is strong and untested under noise: results assume precise camera trajectories (e.g., Aria SLAM). Conduct sensitivity analyses to trajectory noise, drift, latency, and calibration errors; explore self-correction or camera-robust conditioning.
- Action space is limited to human hands: locomotion is only reflected via camera motion and full-body actions are not modeled; robot grippers are unsupported. Extend conditioning to full-body kinematics and robotic end-effectors, and evaluate cross-embodiment transfer.
- Lack of 3D consistency evaluation: the model produces 2D videos, but world modeling requires 3D coherence. Add multi-view consistency tests, 3D re-rendering checks, or geometry predictions (depth/point maps) and quantify 3D integrity across views.
- No uncertainty quantification: diffusion samples imply stochastic outcomes, yet uncertainty is neither estimated nor calibrated. Provide per-pixel/temporal uncertainty maps, prediction intervals for dynamics, and use uncertainty in planning and safety checks.
- Limited long-horizon and multi-step tasks: sequence length, compounding errors, and task decomposition aren’t analyzed. Test extended interactions (e.g., multi-stage assembly, multi-room tasks), track error accumulation, and introduce hierarchical planning.
- Evaluation lacks physical/task success metrics: PSNR/SSIM/LPIPS/DreamSim don’t reflect physical feasibility or goal completion. Add task success/goal completion rates, contact accuracy, articulation trajectory error, and physics-violation metrics.
- Baseline coverage may be incomplete: comparisons omit recent interaction/world-model baselines that model human/robot actions under dynamic views. Include stronger baselines (e.g., PEVA, PlayerOne, humanoid world models) and normalize conditioning inputs for fairness.
- Real-world training data is restricted to fixed cameras: no paired egocentric dynamic training data; domain gap persists. Scale up paired dynamic egocentric datasets (e.g., synchronized static-twin and interaction captures) and quantify gains versus fixed-camera-only training.
- Hand reconstruction errors are not analyzed: HaMeR-based hand meshes for real data can be noisy, causing misaligned conditioning. Measure failure modes from hand pose errors and improve with multi-view hand capture, temporal smoothing, or uncertainty-aware conditioning.
- Deformables, fluids, and transparent/reflective materials are underrepresented: results for liquids, cloth, gels, and complex optics are anecdotal. Curate targeted datasets and benchmarks, and incorporate specialized priors (e.g., fluid simulators or material-aware modules).
- Occlusion and self-occlusion handling is unclear: when hands or targets are occluded, dynamics may degrade. Evaluate occlusion robustness and introduce occlusion-aware conditioning (e.g., volumetric hand priors, visibility masks).
- Target selection and multi-object interaction control are not formalized: “accurate targeting” is illustrated but not measured or controllable at scale. Add metrics for target selection fidelity and controllability; introduce object-indexed action conditioning.
- No analysis of the role and reliability of text prompts: semantics may conflict or be redundant with hand conditioning. Quantify the contribution of text guidance, test conflicting or underspecified prompts, and explore grounding text to object states.
- Planning remains open-loop and limited to ranking visuals: action evaluation uses VideoCLIP/LPIPS without closed-loop control or state feedback. Integrate DWM with policy learning (e.g., model-predictive control, RL), leverage gradients/latent-space search, and validate real-world execution.
- Runtime and resource footprint are not reported: on-device or interactive digital twin use cases need real-time performance. Benchmark latency, memory, and throughput; investigate distillation or pruning to achieve interactive framerates.
- Generalization beyond the reported domains is uncertain: window-opening generalization is anecdotal; broader diversity is untested. Conduct cross-domain evaluations (industrial, outdoor, multi-user) and study failure patterns.
- Counterfactual and causal validation is limited: the paper claims improved causal structure but does not formally test counterfactuals. Design interventions (e.g., swap hands, zero actions, alter camera only) and quantify causal consistency and invariances.
- Safety and hallucination risks are unaddressed: plausible but incorrect dynamics could mislead downstream agents. Develop confidence thresholds, anomaly detection, and safeguard mechanisms before using DWM for embodied decision-making.
Glossary
- 3D Gaussian representation: A compact 3D scene representation using Gaussian primitives for efficient rendering and alignment. "enabling reconstruction of a 3D Gaussian representation of the static scene from pre-action frames~\cite{kerbl20233d,ye2025gsplat}."
- 3D Gaussian Splatting: A real-time rendering technique that represents scenes as 3D Gaussians to render radiance fields efficiently. "reconstructing full geometry and appearance using 3D Gaussian Splatting~\cite{xia2025drawer,liu2025artgs}."
- Adaptive Layer Normalization (AdaLN): A conditioning mechanism that modulates layer normalization parameters using external inputs for controlled generation. "AdaLN-based conditioning directly injects MANO~\cite{romero2017mano} pose parameters with global orientation and translation of both hands into the diffusion transformer through Adaptive Layer Normalization."
- Aria Glasses: Head-mounted cameras with built-in localization enabling precise egocentric trajectory capture. "We use Aria Glasses, which provide millimeter-level camera trajectory estimates via built-in SLAM~\cite{engel2023project}."
- Articulated scene modeling: Techniques for modeling objects with movable parts and their articulation parameters in 3D scenes. "and articulated scene modeling, either by estimating articulation structures~\cite{liu2023paris,weng2024digitaltwinart,liu2025singapo,mandireal2code} or reconstructing full geometry and appearance using 3D Gaussian Splatting~\cite{xia2025drawer,liu2025artgs}."
- Conditional independence structure: A modeling assumption where variables depend on inputs only through specific rendered views, simplifying probabilistic dependencies. "we assume a conditional independence structure such that the visual sequence depends on the static world and actions only through their egocentric renderings:"
- ControlNet: A neural network that injects structured conditioning (e.g., masks) into diffusion models to guide generation. "handâobject interaction videos from an initial frame using a hand-mask video injected into the diffusion process via ControlNet~\cite{zhang2023adding}."
- Decompositional neural reconstruction: Reconstructing scenes by decomposing them into object-level components to enable editing and interaction. "recent work explores decompositional neural reconstruction~\cite{wu2022objectsdf,ni2024phyrecon,ni2025dprecon,xia2025holoscene} and articulated scene modeling,"
- Digital twins: High-fidelity virtual replicas of real-world environments used for simulation and analysis. "current digital twins remain largely staticâlimited to navigation and view synthesis without embodied interactivity."
- Diffusion Transformer (DiT): A transformer-based backbone for diffusion models that predicts noise in latent space during denoising. "The Diffusion Transformer (DiT)~\cite{peebles2023dit} predicts the noise component from the noisy latent conditioned on the staticâscene and handâmesh latents ."
- DreamSim: A perceptual similarity metric for comparing generated content against ground truth. "we report LPIPS~\cite{zhang2018unreasonable} and DreamSim~\cite{fu2023dreamsim} scores for perceptual similarity"
- Egocentric hand-mesh renderings: Rendered views of articulated hand meshes from the wearer's perspective to encode action geometry and motion. "egocentric hand mesh renderings that encode both geometry and motion cues in the egocentric view"
- Egocentric observation model: A modeling framework that grounds predictions in views observed from a first-person camera trajectory. "Built on an egocentric observation model, DWM predicts residual visual changes conditioned on rendered static scene views and hand mesh trajectories."
- Image-to-video paradigm: Generative approach that extrapolates future video frames from a single image, often entangling background and dynamics. "These approaches commonly adopt an image-to-video paradigm that hallucinates both the scene and its evolution from a single frame, entangling background synthesis with action-driven dynamics."
- Inpainting diffusion model: A diffusion-based generator trained to fill or reconstruct masked regions in videos or images using contextual priors. "we initialize DWM from a pretrained video inpainting diffusion model~\cite{VideoX-Fun}."
- Inpainting priors: The learned generative biases of inpainting models that preserve structure and continuity, used to stabilize training. "Inpainting Priors for Residual Dynamics Learning."
- Joint-axis estimates: Supervisory signals specifying axes of rotation for articulated objects to support motion modeling. "These approaches often require additional supervision such as joint-axis estimates~\cite{qian20233doi,sun2024opdmulti} or detailed segmentation~\cite{kirillov2023sam}, limiting scalability and generalization."
- Latent video diffusion model: A diffusion model operating in a compressed latent space for efficient video generation. "we instantiate the generative process as a latent video diffusion model~\cite{rombach2022ldm} conditioned on two egocentric signals:"
- LPIPS: A learned perceptual image patch similarity metric that correlates with human judgments of visual similarity. "using the LPIPS perceptual metric~\cite{zhang2018unreasonable}:"
- MANO: A parametric hand model providing pose and shape parameters for articulated hand representation. "AdaLN-based conditioning directly injects MANO~\cite{romero2017mano} pose parameters with global orientation and translation of both hands into the diffusion transformer through Adaptive Layer Normalization."
- Plücker-ray encodings: A representation of rays in projective space used to condition vision models on camera geometry. "Plücker-ray encodings~\cite{zhu2025aether,zhou2025seva}"
- Point-map observations: Structured geometric inputs encoding 3D points to improve view and depth consistency. "depth or point-map observations~\cite{yu2024viewcrafter,mark2025trajectorycrafter,tu2025playerone}"
- PSNR: Peak Signal-to-Noise Ratio; a pixel-level metric assessing reconstruction fidelity. "and PSNR and SSIM for pixel-level quality."
- Residual dynamics: The action-induced changes in state or appearance relative to a static baseline. "A core idea behind our formulation is to model only the residual dynamics caused by human actions while preserving all unaltered regions."
- RGBâgeometry generation: Joint modeling of color (RGB) and geometric signals to enforce 3D consistency in generated content. "or joint RGBâgeometry generation~\cite{wu2025spmem,zhen2025tesseract,zhu2025aether} to enforce 3D consistency."
- SDEdit: A stochastic denoising-based editing method that adds noise to inputs and guides denoising with text to produce edits. "We apply SDEdit~\cite{meng2021sdedit} to static videos using text-prompt guidance describing the target action and resulting scene changes (CVX SDEdit)."
- SLAM: Simultaneous Localization and Mapping; algorithms estimating camera trajectory and building a map from sensor data. "which provide millimeter-level camera trajectory estimates via built-in SLAM~\cite{engel2023project}."
- SMPL-X: A parametric human body model with expressive hands, face, and body for full-body pose control. "The actor is parameterized using SMPL-X~\cite{pavlakos2019smplx}, which provides full-body pose control."
- SSIM: Structural Similarity Index; a pixel-level metric measuring perceptual degradation between images. "and PSNR and SSIM for pixel-level quality."
- VideoCLIP: A model that embeds video and text into a shared space to compute semantic similarity. "using a pretrained VideoCLIP model~\cite{wang2024videoclip}:"
- Video variational autoencoder (VAE): A VAE tailored for videos that encodes and decodes spatiotemporal latents for generation. "The model operates in the latent space of a pretrained video variational autoencoder (VAE)~\cite{kingma2014vae,yang2025cogvideox},"
- World models: Generative-predictive models that learn environment dynamics to enable planning and action. "World models~\cite{ha2018worldmodel} aim to capture the underlying structure and dynamics of the environment so that intelligent systems can reason, plan, and act effectively."
Practical Applications
Immediate Applications
The following use cases can be deployed now using the paper’s core capabilities: scene–action–conditioned video diffusion, residual dynamics learning via inpainting initialization, egocentric hand-mesh conditioning, hybrid synthetic/real training, and simulation-based action evaluation with VideoCLIP/LPIPS.
- Robotics and Manufacturing — Action sandbox for preview and selection
- Use case: Offline “what-if” previews of dexterous actions before execution (e.g., grasping, opening doors/drawers) in a known workspace. Rank candidate maneuvers against a goal instruction or goal image using the paper’s action evaluation (VideoCLIP/LPIPS).
- Tools/workflows: A DWM-backed “action check” pane in robot teleop/UIs; batch scoring of candidate trajectories; integration with existing planners to prune risky/low-yield options.
- Assumptions/dependencies: Accurate static 3D reconstruction of the cell; egocentric hand pose (or mapped robot gripper pose) with camera trajectory; offline GPU inference; output is visual plausibility, not physics-validated.
- Digital Twins (AEC/FM, real estate, retail) — Interactive visualizations without full physics
- Use case: Add interactive “open/close/move” previews to static digital twins for customer demos, facility walkthroughs, or retail product set-ups.
- Tools/workflows: DWM “interactivity layer” that reuses fixed scene renderings and overlays manipulation-driven residual changes; Unity/Unreal plugin to export dynamic clips.
- Assumptions/dependencies: Static twin rendering and camera path available; short clip latency acceptable; manipulation realism is plausible but not physically guaranteed.
- Film, Games, and XR — Rapid previsualization of hand-centric interactions
- Use case: Previz for props and UI interactions by sketching hand trajectories and camera paths; generate coherent clips that retain background continuity due to the inpainting prior.
- Tools/workflows: DWM plugin for DCC tools (Unreal/Unity/Blender); retarget mocap or glove-based hand meshes into the DWM hand-conditioning stream.
- Assumptions/dependencies: Hand trajectory authoring or capture; suitable scene renders; creative teams accept non-physical (yet plausible) dynamics for blocking/ideation.
- Product and UX Design — Quick interaction prototyping
- Use case: Validate usability (reach, grip, actuation) of devices (e.g., knobs, latches, switches) by simulating how hand motions change the scene from the user’s viewpoint.
- Tools/workflows: CAD-to-DWM pipeline that renders the device’s static scene views and tests multiple hand paths for outcome plausibility.
- Assumptions/dependencies: Accurate hand-mesh conditioning; articulation is implicit (no explicit joint constraints); best for early-stage visual feedback.
- E-commerce — Auto-generate “hands-on” product clips
- Use case: Show opening/closing, unpacking, or assembly steps in realistic backgrounds without filming every variant.
- Tools/workflows: Batch generation service that consumes static renders and predefined hand trajectories to produce short product interaction videos.
- Assumptions/dependencies: Product models or high-quality twins; hand motions curated per SKU; tolerance for plausible but not mechanically exact motion.
- Education and Training — Instructional interaction videos
- Use case: Generate step-by-step handling clips for lab equipment or tools from an egocentric perspective, improving procedural understanding.
- Tools/workflows: Authoring tools where educators specify camera paths and hand sequences to produce demo videos.
- Assumptions/dependencies: Scene capture or 3D asset; hand trajectories from demonstration; acceptance that visuals convey intent rather than exact dynamics.
- Computer Vision and Embodied AI Research — Data augmentation for hand–object interaction
- Use case: Augment datasets with diverse backgrounds and camera motions while preserving targeted contact-induced changes for training segmentation, detection, or anticipation models.
- Tools/workflows: DWM-driven generation of labeled (or weakly labeled) clips with known hand inputs; use in pretraining or curriculum learning.
- Assumptions/dependencies: Labeling strategy (e.g., transfer hand/object masks); manage distribution shift from synthetic visual dynamics.
- HCI and Safety Communication — Visual “what-if” demos
- Use case: Show what happens when a control is operated (e.g., pressing an elevator button triggers doors; opening a valve causes flow) for signage, onboarding, or SOP videos.
- Tools/workflows: DWM template library for common interactions applied to captured scenes.
- Assumptions/dependencies: Scenes and outcomes must be curated to avoid misleading physics; carefully chosen camera trajectories.
- Accessibility and Rehab Planning — Interaction feasibility previews
- Use case: Clinicians or caregivers preview whether a patient’s hand configuration could operate household devices; illustrate compensatory strategies.
- Tools/workflows: Library of canonical hand poses and trajectories mapped to home digital twins; clinician-controlled scene rendering.
- Assumptions/dependencies: Clinical teams accept qualitative plausibility; requires accurate hand model selection per patient.
- Benchmarking and Methodological Research — Navigation–manipulation disentanglement tests
- Use case: Evaluate new world-modeling approaches on DWM’s disentangled conditioning (static scene + hand action) and residual-dynamics objective.
- Tools/workflows: Reproduce the hybrid dataset recipe (TRUMANS + fixed-camera real videos), egocentric capture protocol, and action-evaluation pipeline.
- Assumptions/dependencies: Access to datasets or equivalents; consistent VAE/diffusion backbones; reproducibility of hand mesh estimates.
Long-Term Applications
These use cases require further research, scaling, or systems integration (e.g., real-time inference, stronger physics, broader generalization, or standardized interfaces).
- Robotics — Model predictive control with learned visual world models
- Use case: Use DWM as a prediction module inside MPC for dexterous manipulation in cluttered environments; choose control sequences that maximize goal alignment over predicted video futures.
- Tools/products: Real-time DWM variants; hand-to-gripper retargeting; integration with cost functions beyond CLIP/LPIPS (task success proxies).
- Assumptions/dependencies: Significant latency reduction; robust mapping from human hand meshes (MANO) to robot end-effectors; calibrated, updated scene twins.
- Real-time AR Assistants — Egocentric guidance with interactive previews
- Use case: On-device suggestions that simulate how to operate appliances/tools in-situ, overlaying short predicted clips before users act.
- Tools/products: AR glasses app with SLAM, hand tracking, and condensed diffusion; on-device or edge inference; UI for step confirmation.
- Assumptions/dependencies: On-device acceleration, battery/thermal limits; robust egocentric hand tracking in-the-wild; privacy-preserving pipelines.
- Physics-aware Interactive Digital Twins — Operations and maintenance
- Use case: Facility operators foresee consequences of manipulations (valves, breakers) with articulation constraints and materials behavior blended into learned visuals.
- Tools/products: Hybrid physics + diffusion models; articulated object discovery; scene graphs linked to DWM residuals.
- Assumptions/dependencies: Scaling beyond plausible to physics-consistent predictions; broad coverage of articulated mechanisms; safety validation.
- Training Robot Policies from Visual Imagination — Synthetic rollouts for RL/IL
- Use case: Generate diverse, action-conditioned interaction videos to bootstrap policies for grasping and tool use (e.g., preference learning from simulated outcomes).
- Tools/products: DWM-driven data engines; video–policy alignment modules; domain randomization schedules.
- Assumptions/dependencies: Demonstrated sim-to-real correlation; reward proxies robust to video artifacts; curriculum that mixes real and generated experience.
- Human–Robot Collaboration and Shared Autonomy
- Use case: Preview-and-approve workflows where human operators simulate and adjust a cobot’s planned manipulation from an egocentric view.
- Tools/products: Joint planning UIs, consistency checks between simulated and real sensor frames, safety gating.
- Assumptions/dependencies: Reliable state estimation; codified guardrails for mismatch between visuals and actual physics.
- Healthcare and Rehabilitation — Personalized fine-motor therapy planning
- Use case: Therapists co-design tasks with visual previews showing required hand trajectories and expected device responses tailored to patient limitations.
- Tools/products: Patient-specific hand models; compliance testing modules; outcome logging and adaptation.
- Assumptions/dependencies: Clinical validation and regulatory approval; integration with medical data and ethics constraints.
- Education and Skills Training at Scale (TVET, labs)
- Use case: Interactive content that simulates lab tool operation across many facilities without filming; students explore outcomes safely before hands-on practice.
- Tools/products: LMS-integrated DWM generator; authoring portals for instructors.
- Assumptions/dependencies: Broad library of accurate scene twins; QA processes to prevent unsafe misrepresentations.
- Accessibility and Inclusive Design — Ergonomic and reachability audits
- Use case: Simulate interactions across hand sizes/abilities to test compliance (e.g., ADA) and discover usability issues.
- Tools/products: Parameterized hand models; batch evaluation across device variants.
- Assumptions/dependencies: Standardized metrics and validators; evidence that visual outcomes correlate with usable-force/effort thresholds.
- Insurance and Risk Assessment — Human-factor incident analysis
- Use case: Pre-assess manipulation-related risks (e.g., pinch points, mis-operations) by simulating user actions across scenarios in digital twins.
- Tools/products: Scenario libraries; risk scoring linked to simulated video features.
- Assumptions/dependencies: Validated relationship between predicted visuals and real incident likelihood; governance around use in underwriting.
- Energy and Industrial Maintenance — Remote procedure rehearsal
- Use case: Plan and rehearse manipulations (switches, panels) for remote sites; brief technicians with egocentric previews.
- Tools/products: Integrated site twins, handheld/helmet cameras for capture, DWM job-planning tool.
- Assumptions/dependencies: Accurate up-to-date twins; safety certification; robust handling of harsh conditions.
- Urban Infrastructure and Policy — Accessibility and compliance previews
- Use case: Simulate public interface interactions (ticketing, elevators, doors) to test usability for varied populations before deployment.
- Tools/products: City-scale twin subsets; standardized evaluation protocols and audit reports.
- Assumptions/dependencies: Large-scale capture and maintenance of twins; privacy and data governance; external validation.
- Creative Tools — Interactive 4D content for VR/Metaverse
- Use case: Author hand-driven interactions that preserve static fidelity while animating plausible outcomes, enabling scalable content creation.
- Tools/products: DWM “interaction brushes” for VR authoring tools; libraries of hand actions.
- Assumptions/dependencies: Runtime optimization; creator controls for physics plausibility; content moderation.
Notes on feasibility and dependencies across applications:
- Core dependencies: a static 3D scene or high-quality renderings along a specified camera path; accurate egocentric hand pose estimation or authored MANO/SMPL-X trajectories; and sufficient compute for diffusion inference.
- Method characteristics: inpainting-initialized residual dynamics preserve backgrounds and camera motion well, but physical correctness (especially for fluids/deformables and precise articulations) is not guaranteed without added constraints.
- Generalization: hybrid training improves realism but coverage remains limited; domain adaptation and data expansion (articulated object diversity, materials) will broaden applicability.
- Ethics and privacy: egocentric capture and in-situ twins can include sensitive content; policies for consent, storage, and on-device processing are recommended.
Collections
Sign up for free to add this paper to one or more collections.

