- The paper introduces RagSynth as a framework to create synthetic datasets that optimize both retriever and generator components in RAG systems.
- It employs a multi-step methodology including data chunking, clue extraction, entity graph construction, and query variance to tackle retrieval and generation challenges.
- Experimental results using SynthBench show significant improvements in retrieval precision and generation fidelity across diverse domains.
Overview of "RAGSynth: Synthetic Data for Robust and Faithful RAG Component Optimization"
The paper introduces RagSynth, a framework that aims to optimize Retrieval-Augmented Generation (RAG) systems through the use of synthetic data. RAG systems enhance LLMs by incorporating a retrieval mechanism to fetch relevant documents and a generation component to synthesize answers. This paper addresses the existing challenges of retriever robustness and generator fidelity by proposing a comprehensive synthetic data construction approach.
RAGSynth: Synthetic Data Construction and Implementation
Modeling Approach
RagSynth constructs synthetic data by modeling complex relationships between documents, queries, clues, answers, and their mappings. The key entities in this approach are:
- Document Set (D): A collection from which relevant documents are retrieved.
- Query Set (Q): Queries linked with ground-truth answers.
- Clue Set (C): Intermediate data derived from document sentences to assist in answering queries.
- Answer Set (A): Standard and variant answers to provide comprehensive coverage during retrieval.
- Mapping Relationships (M): Links clues to documents, and answers to clues, ensuring traceability and source accuracy.
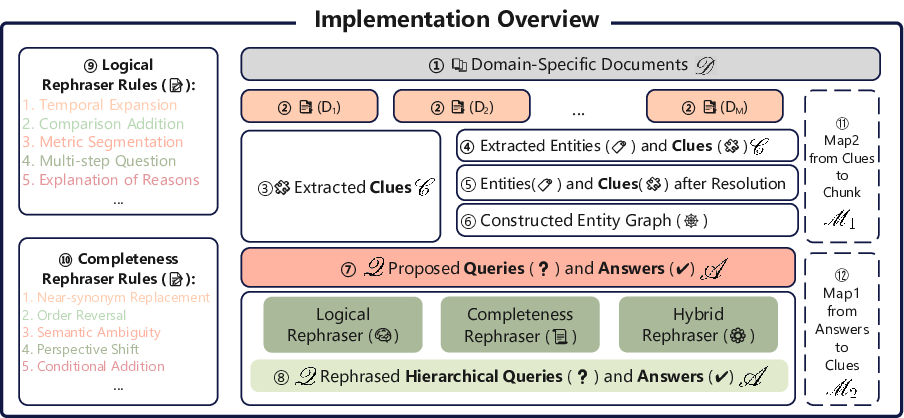
Figure 1: A specific implementation of the RagSynth. For single-hop, mappings among documents, clues, queries, and answers can be directly constructed. For multi-hop, entities and relationships are first extracted from documents, with relationships serving as clues. Subsequently, using these clues as intermediaries, mappings among documents, clues, queries, and answers are established. After constructing the basic dataset, we further generate a large number of variants of the basic queries and their corresponding answers through extensive logical and completeness transformations.
Implementation Steps
- Data Chunking: Documents are divided into manageable segments.
- Clue Extraction: Clues are derived for single- and multi-hop queries using entity relationships.
- Entity Graph Construction: Connects entities across documents for multi-hop queries.
- Query Generation and Variance: LLMs generate diverse queries via equivalence transformations and completeness variation.
- Comprehensive Dataset Development: Ensures various complexity levels in querying and retrieval.
SynthBench and Evaluation Metrics
Domain-specific Corpus and Benchmark
SynthBench is developed using datasets from diverse fields such as gaming, medical guidelines, university admissions, and software documentation. This benchmark is essential for evaluating the robustness and fidelity of RAG systems across different domains.
Evaluation Metrics
- Retrieval Precision: Measures retrieval accuracy using Precision@k.
- Generator Fidelity: Assessed via a new Criteria-based Score for Generation (CSG), evaluating completeness, understanding, and citation accuracy.
CSG comprises:
- Completeness Score for Answerable Parts
- Understanding Score for Unanswerable Parts
- Citation Completeness Score
These metrics address the limitations of existing evaluation methods, providing a comprehensive view of the system's performance.
Experimental Results
Main Findings and Improvements
- Retriever Performance: Substantial improvements were noted in retriever robustness across different datasets, especially when facing queries with partial clues.
- Generator Enhancements: SynthBench shows that fine-tuned generators using RagSynth have a higher fidelity score and better citation accuracy.
- Cross-domain Generalization: Enhanced retrievers and generators exhibit robust performance in domains beyond their training set, demonstrating RagSynth’s broad applicability.
Integrating optimized retrievers into various RAG architectures consistently enhanced their performance. This emphasizes the critical role of robust retrieval in ensuring effective RAG systems.
Conclusion
RagSynth emerges as a powerful tool for crafting synthetic datasets that bolster the retrieval and generation capabilities of RAG systems. Its methodological approach to data synthesis and the establishment of SynthBench provide a new avenue for developing robust RAG components that can adapt across domains. The demonstrated improvements in retrieval robustness and generation fidelity underscore the framework's potential impact on future RAG advancements. Future work aims to extend capabilities to more complex logical reasoning and cross-entity challenges beyond deterministic answers.