- The paper presents RARE, a framework that quantitatively measures RAG systems’ robustness against real-world query and document perturbations.
- It employs dynamic benchmarks and automated pipelines like RARE-Get to generate domain-specific single-hop and multi-hop queries.
- Results reveal that robustness varies by perturbation type, with mid-sized models sometimes outperforming larger ones.
"RARE: Retrieval-Aware Robustness Evaluation for Retrieval-Augmented Generation Systems" (2506.00789)
Introduction
The paper "RARE: Retrieval-Aware Robustness Evaluation for Retrieval-Augmented Generation Systems" introduces the RARE framework, which addresses the shortcomings in the robustness evaluation of Retrieval-Augmented Generation (RAG) systems. These systems, essential for integrating external knowledge into LLMs, have performance vulnerabilities when exposed to real-world perturbations, conflicting contexts, or rapidly changing information. Existing evaluation benchmarks often provide an optimistic assessment of RAG systems by relying on static datasets and general-knowledge queries, which fail to simulate real-world complexity and dynamics.
RARE Framework Components
RARE-Met: This component introduces a robustness evaluation metric for RAG systems subjected to perturbations in queries and documents as well as real-world retrieval scenarios. It defines robustness in terms of the system's ability to remain accurate despite these perturbations. Notably, robustness metrics include:
- Overall Robustness: Measures performance when both queries and documents are perturbed.
- Query and Document Robustness: Focus on perturbations in queries or documents separately.
RARE-Get: This is an automated pipeline that synthesizes domain-specific benchmarks dynamically through knowledge graph triplet extraction. It generates single and multi-hop question sets in a manner that evolves with the corpus, ensuring that the evaluation remains aligned with the latest information.
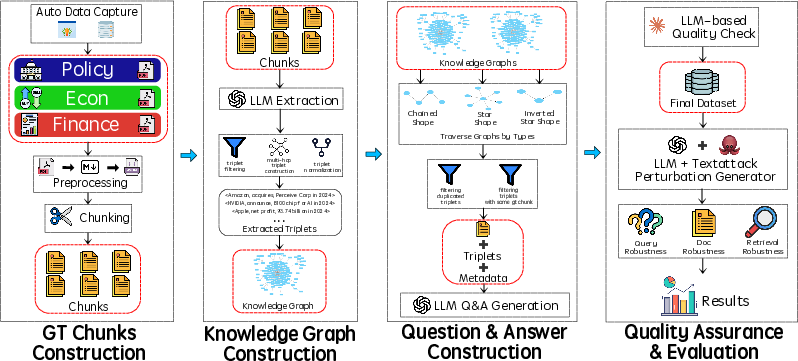
Figure 1: Illustration for the RARE framework.
Methodology
Query and Document Perturbations
The paper defines sophisticated perturbation strategies for both queries and documents:
- Query Perturbations: Surface-level and advanced-level perturbations that include character and word-level changes as well as LLM-based grammatical modifications.
- Document Perturbations: Focus on lexical and answer relevance, utilizing three distinct types to simulate real-world retrieval challenges.
Dynamic Benchmark Dataset
The RARE-Set dataset spans various domains such as finance, economics, and policy, comprising over 400 specialized documents and approximately 48,322 queries. It emphasizes generating domain-specific, technical queries essential for evaluating RAG systems under realistic conditions. The dataset features diverse querying patterns necessary for complex reasoning, including single-hop and multi-hop queries.
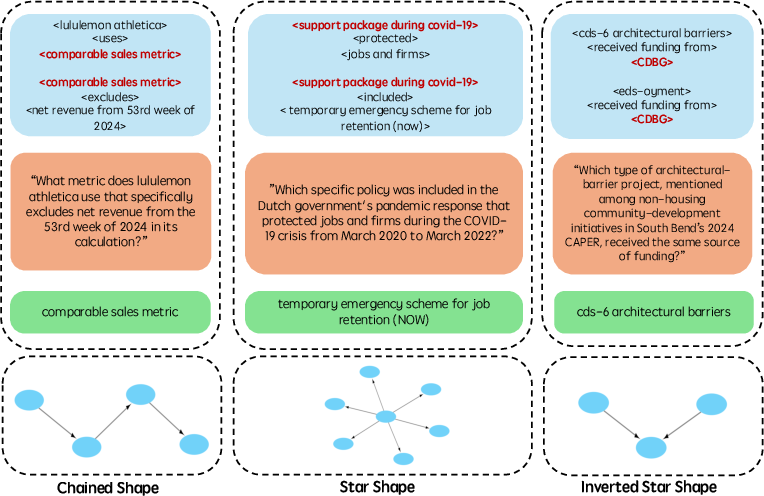
Figure 2: Examples of the multi-hop questions.
Table \ref{tab:dataset_comparison} provides a comparative analysis of RARE with previous benchmarks in terms of time-sensitivity, dynamism, and automation, underscoring its exhaustive and relevant nature across multiple demanding domains, offering a more significant and dynamic benchmark compared to precedents.
Experimental Evaluation
The RARE framework provides quantitative insights into RAG systems' vulnerabilities. Experiments on the newly constructed dataset with leading open-source and closed-source LLMs revealed their systematic susceptibility to document perturbations, with model size not a strict determinant of robustness. In particular, mid-sized generators may outperform larger ones, highlighting the importance of model architecture and training methodologies.
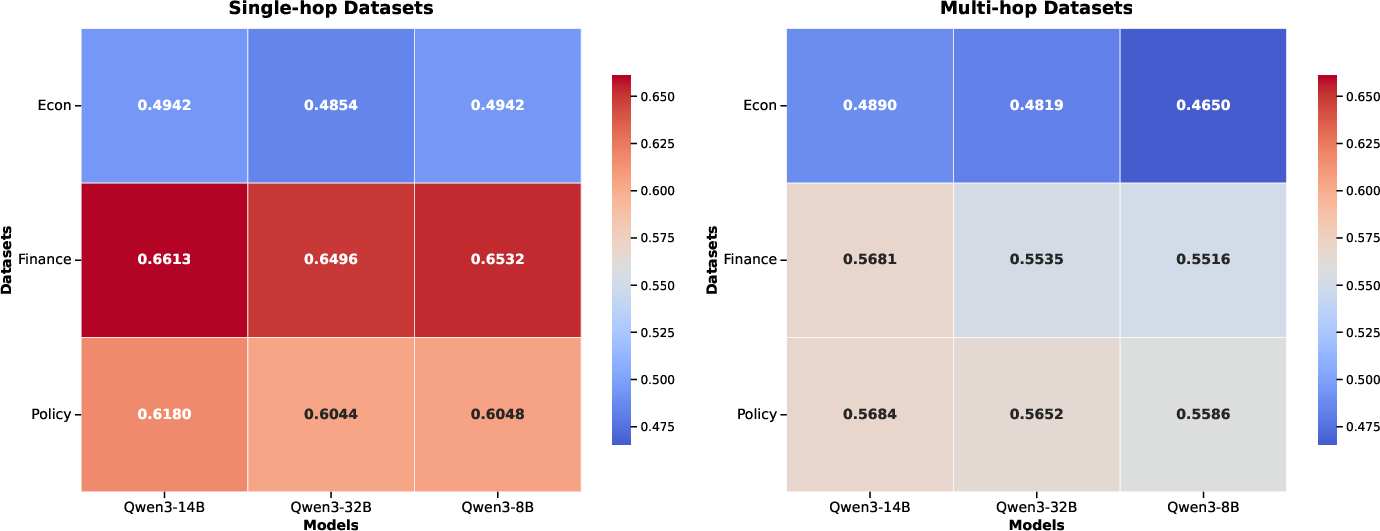
Figure 3: Overall robustness scores across different domains among top-3 LLMs.
The robustness scores by domain and perturbation type, shown in Table \ref{tab:robust_ideal}, indicate that RAG systems perform better on single-hop queries than on multi-hop queries, with significant robustness declines under document perturbations. This underlines the necessity of incorporating diverse document conditions and query complexities into RAG benchmarks to evaluate robustness against dynamic information changes realistically.
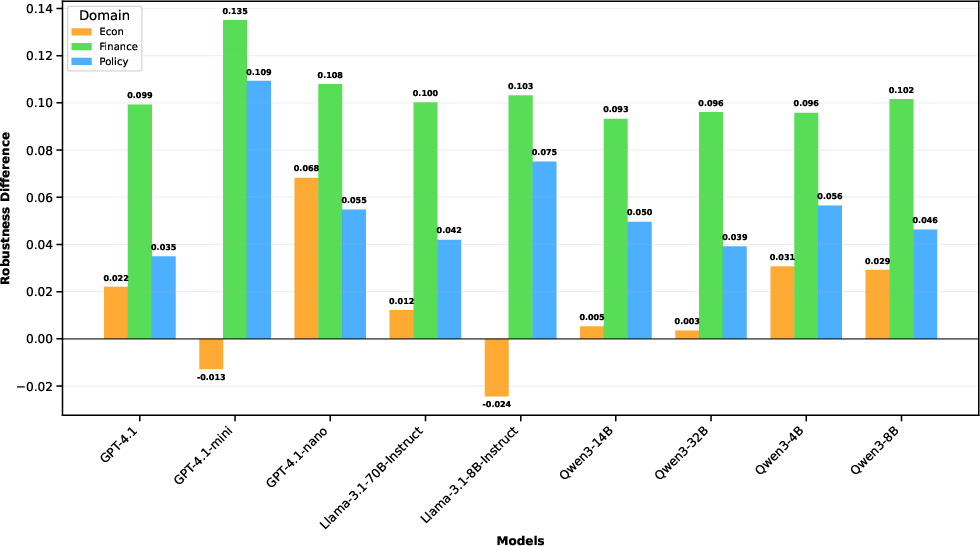
Figure 4: Difference in multi-hop and single-hop robustness scores by domain...
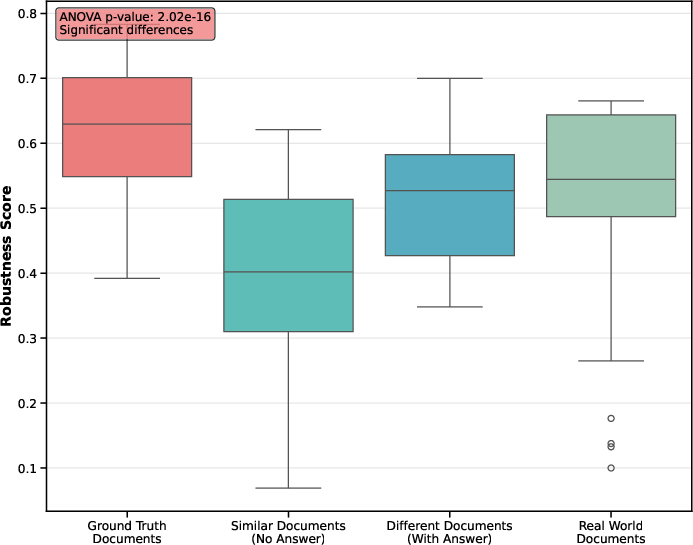
*Figure 5: Robustness distribution differences across all document perturbations (including real-world retrieval results) given original query. Document perturbations significantly affect the robustness of RAG system. All kinds of document perturbation reveal significant drop compared to original ground truth documents results. RAG systems exhibit considerable difficulty in accurately leveraging their internal knowledge (or refuse to answer) when the provided documents do not contain the correct answer. *
Results and Observations
The evaluation results are synthesized in Table \ref{tab:robust_ideal} and Table \ref{tab:robust_ideal}.
It is observed that, broadly, the robustness of RAG systems does not necessarily improve proportionally with generator size (Figure 6).
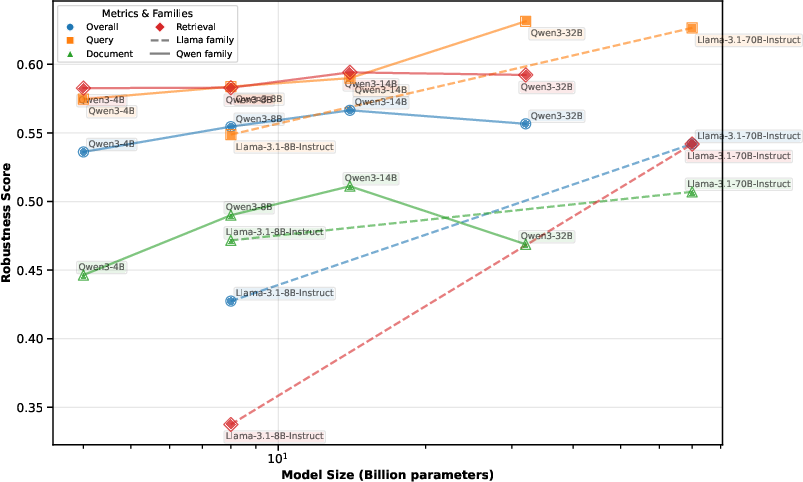
Figure 6: Relationship between the sizes of open-source generators and their robustness scores across various categories. Generally, larger generator sizes correspond to higher robustness scores. However, for Qwen 3 models, robustness scores tend to decline across all metric types—except for query perturbation—once the parameter size exceeds 14 billion.
RAG systems show greater robustness against query perturbations than document perturbations, as demonstrated in Figures \ref{query_perturbation_analysis} and \ref{tab:robust_ideal}. This observation indicates the models' reliance on internal knowledge when retrieval inputs undergo perturbations.
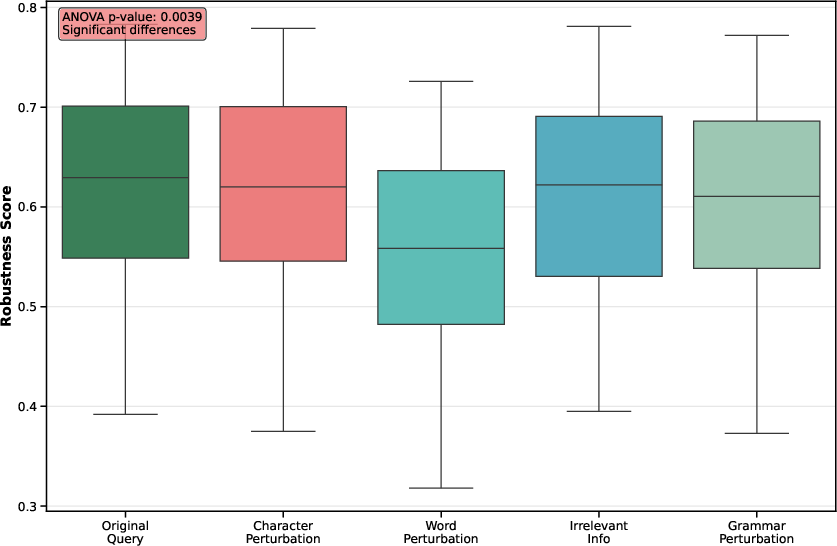
Figure 7: Robustness distribution differences across all query perturbations given original ground truth documents. Compared to document perturbations, query perturbations have a relatively smaller impact on the robustness of RAG systems (higher ANOVA p-value). Among various types of query perturbations, word-level perturbations exert a significantly greater influence on robustness than other forms.
Contrarily, Figure \ref{fig:query_vs_document_robust} demonstrates that query perturbations impact robustness less severely than document perturbations, showcasing a relatively smaller effect on the model's capability (Figure 7). However, word-level perturbations stand out as particularly challenging, suggesting a need to improve handling robustness against broader linguistic variations and errors.
Our evaluations (Table \ref{tab:robust_ideal}) reveal that despite their size, even state-of-the-art LLMs (GPT-4.1 and Qwen3) do not exhibit universally strong robustness across all metrics. There is a surprising vulnerability to document perturbations, particularly when retrieval results contain relevant but lexically different content.
Figure 6 highlights the relationship between the sizes of open-source generators and their robustness scores exposed by query and document perturbations, illustrating that an increase in model size does not guarantee proportional increases in robustness for larger Qwen models above 14 billion parameters.
Figure 2: Relationship between the sizes of open-source generators and their robustness scores across various categories. Generally, larger generator sizes correspond to higher robustness scores. However, for Qwen 3 models, robustness scores tend to decline across all metric types—except for query perturbation—once the parameter size exceeds 14 billion.
Additionally, the study indicates that real-world retrieval scenarios are concluded to have a profound influence on retrieval robustness (Figure 7).
Figure 7: Robustness distribution differences across all query perturbations given original ground truth documents. Compared to document perturbations, query perturbations have a relatively smaller impact on the robustness of RAG systems (higher ANOVA p-value). Among various types of query perturbations, word-level perturbations exert a significantly greater influence on robustness than other forms.
Implications and Future Directions
The RARE framework provides a robust solution for evaluating RAG system robustness across diverse, evolving information landscapes. It highlights critical gaps in document handling and multi-hop query processing, demonstrating current systems' limitations in handling perturbed inputs, regardless of scale. The introduction of a unified, large-scale dynamic framework has the potential to refocus RAG evaluations toward real-world conditions previously underestimated in traditional benchmarks. It offers direct guidance for evolving RAG systems to better handle the complexities of domain-specific and dynamic queries and documents.
Looking forward, future research can explore hybrid LLMs and adaptive information retrieval strategies or focus on enhancing training techniques for domain-specific information synthesis and dynamic contexts. Furthermore, advancing auxiliary evaluation frameworks like RARE-Met may facilitate the development of resilient RAG architectures.
Conclusion
RARE provides critical insights into the examination of RAG systems under varied realistic scenarios. This schema is an important step towards improving the robustness of RAG models in the ever-evolving datasets. The disparity in system performance across domains and query types signals a substantial opportunity to bolster the resilience of RAG architectures. Further investigation into hybrid architectures and domain adaptation techniques will potentially enhance RAG robustness and maintain relevancy in the fast-paced information landscape.