- The paper presents a novel claim-level evaluation framework that diagnoses both retriever and generator components in RAG systems.
- The methodology integrates semantic-based metrics to provide granular insights into faithfulness, noise sensitivity, and hallucinations.
- The experiments reveal that improved retriever quality and larger generator models significantly boost precision, recall, and overall performance.
A Detailed Analysis of "RAGChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation"
Introduction
The introduction of the "RAGChecker" framework addresses the increasing complexity in evaluating retrieval-augmented generation (RAG) systems effectively. These systems, which enhance LLMs by incorporating external knowledge bases, have found application in various fields. RAG systems face significant evaluation challenges due to their modular nature consisting of retrievers and generators. RAGChecker offers a sophisticated diagnostic framework to evaluate each component and their interactions thoroughly.
Modular Challenges and Metric Limitations
Evaluating RAG systems with accuracy presents substantial difficulties, especially given their modular configuration. Existing metrics often rely on rule-based or coarse-grained evaluations that cannot capture the full scope necessary for effective diagnostics:
- Retriever Metrics like recall@k and MRR hinge on annotated chunks, neglecting broader semantic scopes.
- Generator Metrics using BLEU, ROUGE, or BERTScore perform well on concise answers but miss nuances in lengthy responses.
The significant challenge lies in seamlessly integrating semantic-based metrics that can reconcile the intricacies of both retrieval and generation processes.
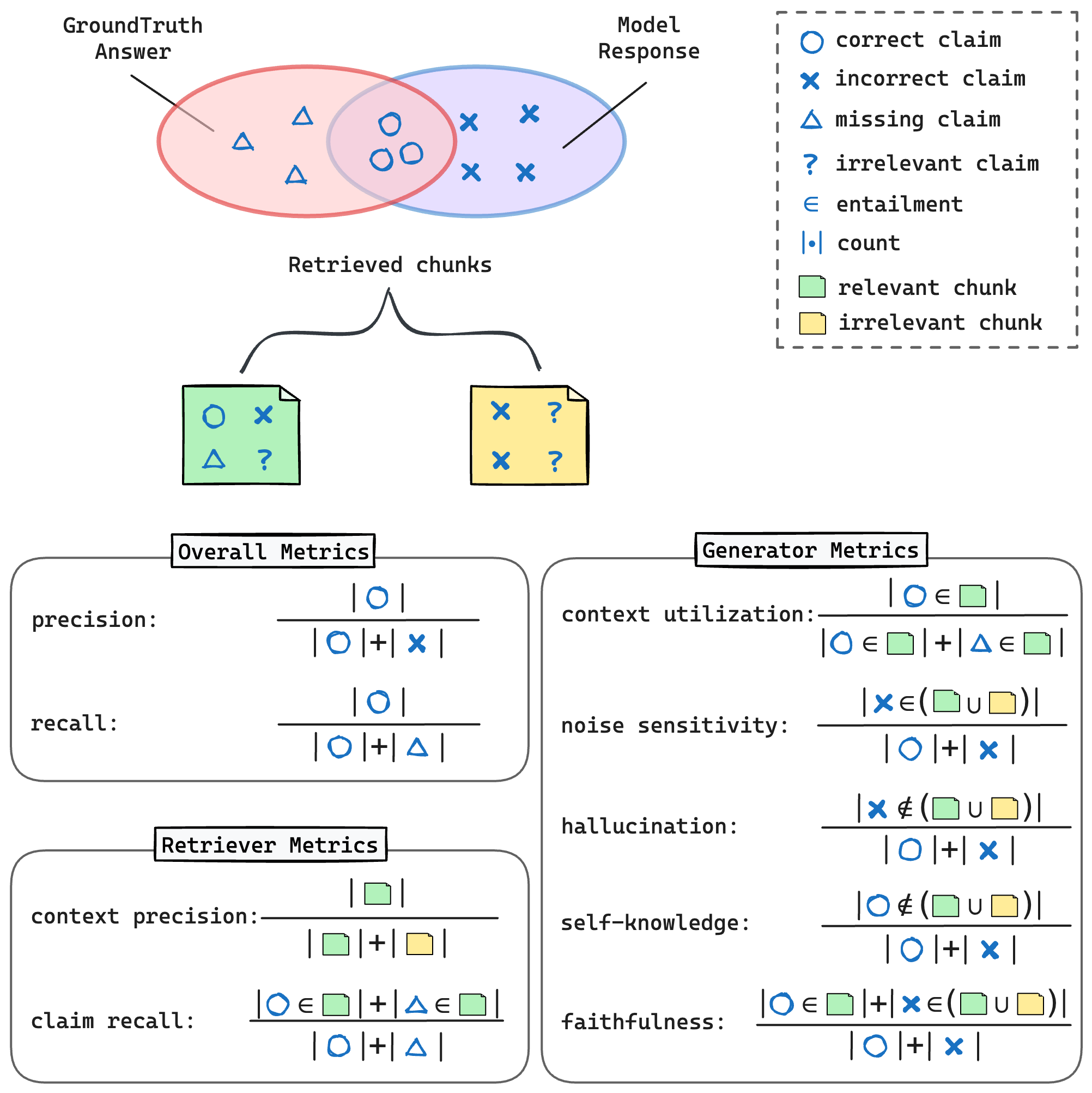
Figure 1: Illustration of the proposed metrics in RagChecker. The upper Venn diagram represents potential model response errors relative to the ground truth, with evaluation metrics presented below.
RagChecker Framework Structure
RagChecker introduces a claim-level entailment-based evaluation. It processes queries along with retrieved contexts, responses, and ground-truth answers to deliver comprehensive metrics that evaluate RAG systems wholly and at module levels:
- Overall Metrics: Provide a system-wide perspective through claim precision and recall, crucial for assessing a system's capacity to generate complete and accurate responses.
- Retriever Metrics: These evaluate how many relevant chunks are retrieved (context precision) and how many claims from ground truth are covered (claim recall).
- Generator Metrics: Analyze the generator's effectiveness by measuring faithfulness to the context, noise sensitivity, hallucination, and the reliance on external knowledge versus self-knowledge.
Experimental Insights
Experiments with eight state-of-the-art RAG systems on a curated benchmark revealed several pivotal insights:
- Retriever Importance: Better retrievers like E5-Mistral paired with strong generators significantly improve precision, recall, and F1 scores.
- Generator Model Size: Larger models generally exhibit enhanced performance across all metrics due to better handling of retrieval complexities and context utilization.
- Faithfulness and Context Utilization: More informative context generally increases faithfulness and decreases hallucination but increases sensitivity to noise.
Diagnosis of RAG System Settings
Adjusting parameters like the number of chunks, chunk size, and generation prompts demonstrates the flexibility and diagnostic power of RagChecker:
- Increasing Context Amount: Leads to better faithfulness but also raises noise sensitivity.
- Prompt Requirements: Explicit prompts improve faithfulness and context utilization but highlight the complexity in optimizing all aspects simultaneously.
Conclusion
RagChecker elevates the standard for RAG system evaluation, equipping researchers and developers with actionable insights into system behavior. Future research could focus on refining retriever diagnostics and expanding RagChecker's applicability across diverse modalities and languages for more comprehensive RAG system analysis.