RQ-RAG: Learning to Refine Queries for Retrieval Augmented Generation
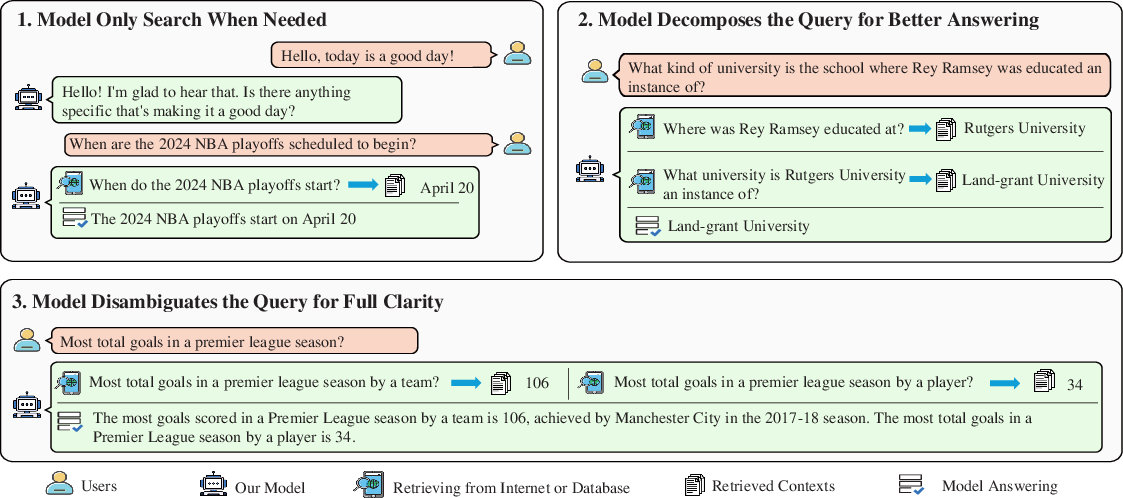
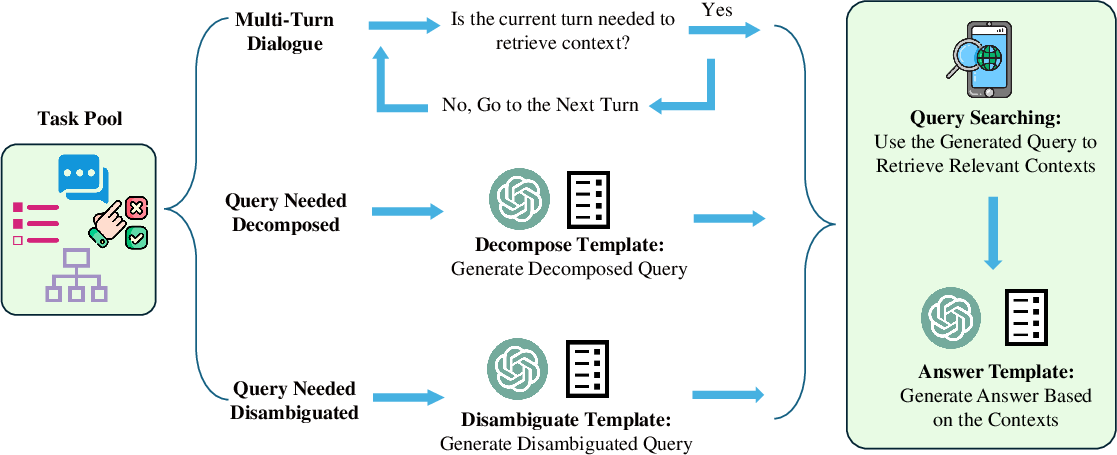
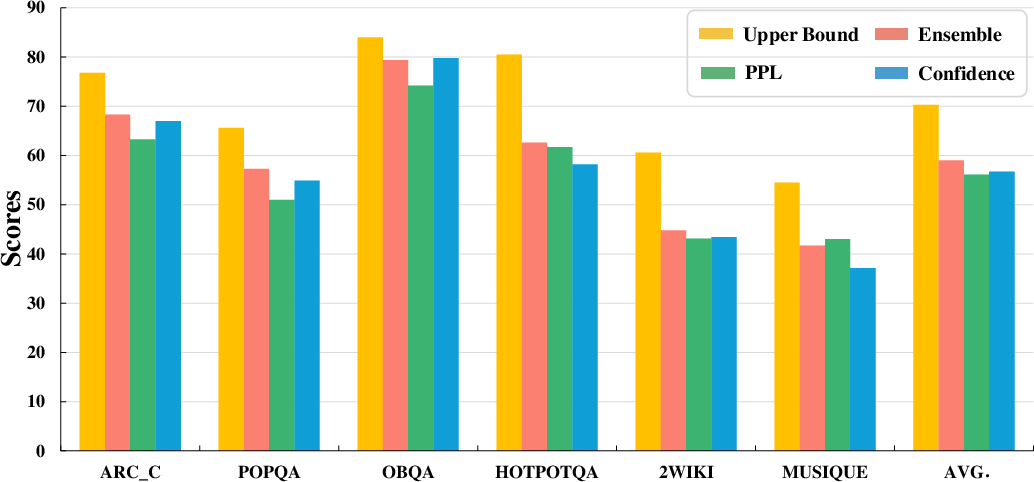
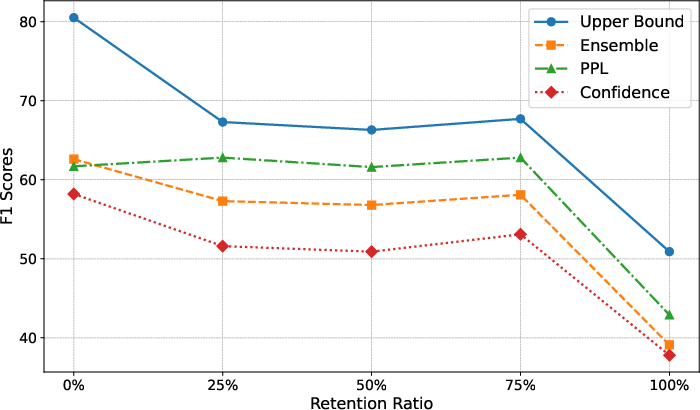
Abstract: LLMs exhibit remarkable capabilities but are prone to generating inaccurate or hallucinatory responses. This limitation stems from their reliance on vast pretraining datasets, making them susceptible to errors in unseen scenarios. To tackle these challenges, Retrieval-Augmented Generation (RAG) addresses this by incorporating external, relevant documents into the response generation process, thus leveraging non-parametric knowledge alongside LLMs' in-context learning abilities. However, existing RAG implementations primarily focus on initial input for context retrieval, overlooking the nuances of ambiguous or complex queries that necessitate further clarification or decomposition for accurate responses. To this end, we propose learning to Refine Query for Retrieval Augmented Generation (RQ-RAG) in this paper, endeavoring to enhance the model by equipping it with capabilities for explicit rewriting, decomposition, and disambiguation. Our experimental results indicate that our method, when applied to a 7B Llama2 model, surpasses the previous state-of-the-art (SOTA) by an average of 1.9\% across three single-hop QA datasets, and also demonstrates enhanced performance in handling complex, multi-hop QA datasets. Our code is available at https://github.com/chanchimin/RQ-RAG.
- Self-rag: Learning to retrieve, generate, and critique through self-reflection. In The Twelfth International Conference on Learning Representations.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457.
- Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. arXiv preprint arXiv:2011.01060.
- Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38.
- Dense passage retrieval for open-domain question answering. arXiv preprint arXiv:2004.04906.
- Ctrl: A conditional transformer language model for controllable generation. arXiv preprint arXiv:1909.05858.
- Openassistant conversations-democratizing large language model alignment. Advances in Neural Information Processing Systems, 36.
- Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474.
- Quark: Controllable text generation with reinforced unlearning. Advances in neural information processing systems, 35:27591–27609.
- Search augmented instruction learning. In The 2023 Conference on Empirical Methods in Natural Language Processing.
- Query rewriting for retrieval-augmented large language models. arXiv preprint arXiv:2305.14283.
- When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. arXiv preprint arXiv:2212.10511.
- Can a suit of armor conduct electricity? a new dataset for open book question answering. arXiv preprint arXiv:1809.02789.
- Orca: Progressive learning from complex explanation traces of gpt-4. arXiv preprint arXiv:2306.02707.
- OpenAI (2023). Gpt-4 technical report. arXiv preprint arXiv:2303.08774.
- Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744.
- Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67.
- The probabilistic relevance framework: Bm25 and beyond. Foundations and Trends® in Information Retrieval, 3(4):333–389.
- Large language models can be easily distracted by irrelevant context. In International Conference on Machine Learning, pages 31210–31227. PMLR.
- Replug: Retrieval-augmented black-box language models. arXiv preprint arXiv:2301.12652.
- Retrieval augmentation reduces hallucination in conversation. arXiv preprint arXiv:2104.07567.
- Asqa: Factoid questions meet long-form answers. arXiv preprint arXiv:2204.06092.
- Recitation-augmented language models. arXiv preprint arXiv:2210.01296.
- Stanford alpaca: An instruction-following llama model.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Musique: Multihop questions via single-hop question composition. Transactions of the Association for Computational Linguistics, 10:539–554.
- Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. The 61st Annual Meeting of the Association for Computational Linguistics.
- Freshllms: Refreshing large language models with search engine augmentation. arXiv preprint arXiv:2310.03214.
- Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837.
- Align on the fly: Adapting chatbot behavior to established norms. arXiv preprint arXiv:2312.15907.
- Wizardlm: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304.12244.
- Recomp: Improving retrieval-augmented lms with compression and selective augmentation. arXiv preprint arXiv:2310.04408.
- Hotpotqa: A dataset for diverse, explainable multi-hop question answering. arXiv preprint arXiv:1809.09600.
- Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems, 36.
- Making retrieval-augmented language models robust to irrelevant context. arXiv preprint arXiv:2310.01558.
- Chain-of-note: Enhancing robustness in retrieval-augmented language models. arXiv preprint arXiv:2311.09210.
- Lima: Less is more for alignment. Advances in Neural Information Processing Systems, 36.
- Docprompting: Generating code by retrieving the docs. arXiv preprint arXiv:2207.05987.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.