- The paper introduces MSWA that refines traditional local attention by using varying window sizes across heads and layers, reducing computational cost.
- It implements a dual strategy combining head and layer variations to efficiently capture both local and global dependencies in Transformers.
- Experimental results show improved perplexity and efficiency on benchmarks like Wikitext-103, demonstrating MSWA's practical benefits.
MSWA: Refining Local Attention with Multi-Scale Window Attention
Introduction
The paper "MSWA: Refining Local Attention with Multi-Scale Window Attention" (2501.01039) introduces a novel mechanism for improving Transformer-based LLMs. It critiques the inefficiencies of standard self-attention, particularly the quadratic time complexity and exponentially increasing cache size associated with conventional models. Sliding Window Attention (SWA) offers a classical solution by reducing attention to fixed-size local context windows but lacks adaptability for varying context scales. The proposed Multi-Scale Window Attention (MSWA) advances beyond SWA by introducing diverse window sizes for different heads and layers, facilitating efficient scaling with reduced computational and memory demands.
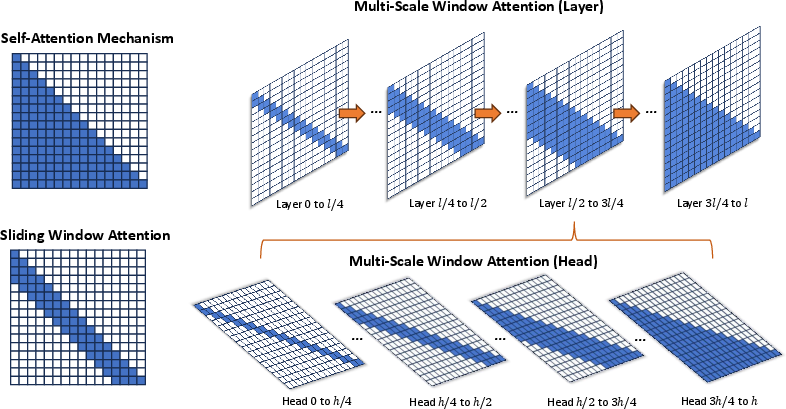
Figure 1: Illustration of Multi-Scale Window Attention mechanism.
Multi-Scale Window Attention
Diverse Window Sizes Across Heads
In MSWA, each attention head within a layer can utilize different window sizes compared to the uniform approach in SWA. This adjustment is inspired by hierarchical designs in computer vision and allows for contextual modeling at multiple scales simultaneously. MSWA-h divides heads into groups with progressively larger windows (ranging from 4w to $2w$), ensuring efficient attention distribution aligned with the locality of reference in NLP data. Consequently, MSWA optimizes attention resources and representation capacity by varying context lengths within single layers, enhancing the model's adaptability across diverse contexts.
Diverse Window Sizes Across Layers
MSWA-l introduces variation in window size allocation across layers, assigning progressively larger windows from shallow to deep layers. This approach accommodates the increased need for long-range dependency capture as processing proceeds deeper into the Transformer model, transitioning from local to global context modeling. Shallow layers handle local fine-grained information efficiently, while deeper layers are tasked with integrating long-range contextual details. This paradigm enhances the model's robustness and capability for dynamic attention allocation throughout its depth.
Integration of Head and Layer Strategies
The MSWA mechanism ultimately combines head and layer diversity strategies, achieving a balanced allocation of attention resources that enhances contextual understanding at varied lengths and distances. This is accomplished with an overall reduction in computational cost—estimated at 87 of traditional SWA configurations—demonstrating efficiency without compromising performance. Such a design not only optimizes local and global information synthesis but also facilitates smoother scalability in modern NLP applications.
Combination with Linear Attention
MSWA's integration with linear attention, as depicted in (Figure 2), synergizes local and efficient global attention mechanisms. Alternating layers of MSWA and linear attention capture both local sensitivity and global awareness. This powerful configuration addresses the loss of focus often associated with linear attention by maintaining efficiency while effectively modeling complex dependencies within lengthy documents.
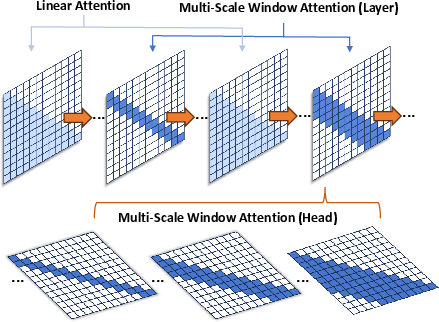
Figure 2: Combination of MSWA and linear attention.
Experimental Results
The paper reports substantial empirical evaluations of MSWA, demonstrating its superiority over traditional SWA and other attention variants. Training on language modeling benchmarks such as Wikitext-103 and enwik8 establishes MSWA's enhanced performance with significant reductions in complexity cost compared to standard self-attention mechanisms. It highlights perplexity improvement and bits-per-character efficiency, robustly proving its effectiveness. MSWA's combination with linear attention yields further promising results, showcasing improvements in efficiency and competitive language modeling capability.
Evaluation on downstream tasks demonstrates MSWA's compatibility and practical value for large-scale LLMs like Llama-7B. Fine-tuned models exhibit strong adaptability and superior reasoning performance across multiple common-sense benchmarks, reaffirming MSWA's practical applicability in real-world scenarios.
Computational Efficiency
MSWA delivers high computational efficiency, as evidenced in Figure 3, with attention mechanisms showing decreased prediction times for large batch sizes. This efficiency is distinct, especially under increased window sizes, solidifying MSWA's capability for scalable deployment.
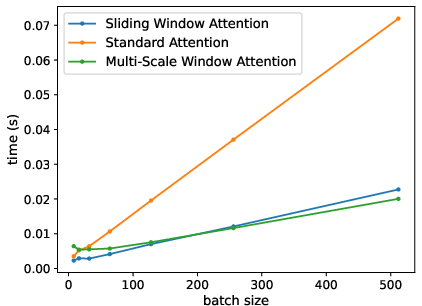
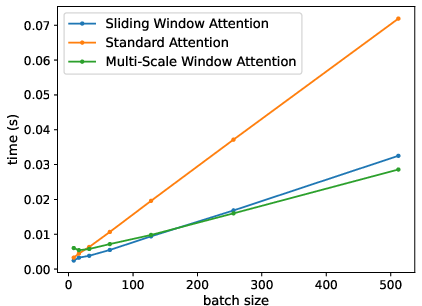
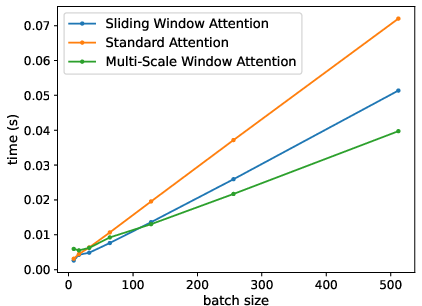
Figure 3: Computational time required by each attention mechanism to predict the next token.
Conclusion
Multi-Scale Window Attention (MSWA) extends traditional local attention frameworks to offer nuanced and efficient contextual modeling. By leveraging multi-scale provisions across heads and layers, it refines the attention operation with reduced computational overhead. The theoretical and practical merits of MSWA are substantiated through rigorous experimentation, confirming its potential for future implementation in scalable AI systems where diverse contextual awareness is paramount.

