Sliding Window Attention Training for Efficient Large Language Models
Abstract: Recent advances in transformer-based LLMs have demonstrated remarkable capabilities across various tasks. However, their quadratic computational complexity concerning sequence length remains a significant bottleneck for processing long documents. As a result, many efforts like sparse attention and state space models have been proposed to improve the efficiency of LLMs over long sequences. Though effective, these approaches compromise the performance or introduce structural complexity. This calls for a simple yet efficient model that preserves the fundamental Transformer architecture. To this end, we introduce SWAT, which enables efficient long-context handling via Sliding Window Attention Training. This paper first attributes the inefficiency of Transformers to the attention sink phenomenon resulting from the high variance of softmax operation. Then, we replace softmax with the sigmoid function and utilize a balanced ALiBi and Rotary Position Embedding for efficient information compression and retention. Experiments demonstrate that SWAT achieves SOTA performance compared with state-of-the-art linear recurrent architectures on eight benchmarks. Code is available at https://github.com/Fzkuji/swat-attention.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of unresolved issues that are missing, uncertain, or left unexplored, framed to inform actionable future research:
- Lack of formal theory for sigmoid-based attention: no analysis of expressivity, optimization dynamics, calibration, or information-retention capacity compared to softmax; no bounds tying memory capacity to window size (ω), depth (L), and slope magnitudes.
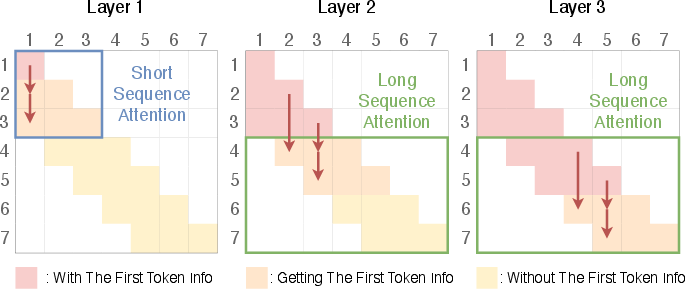
- No quantitative metric for “attention sink” mitigation in SWAT: the paper infers benefits but does not provide standardized measures (e.g., attention variance indices, sink strength curves over layers/lengths) to verify reduction across seeds and datasets.
- Heuristic slope design in “balanced ALiBi”: the choice of half positive/half negative slopes with geometric magnitudes is not justified or optimized; it remains unknown whether slopes should be learned, scheduled per layer/head, or adapted per example.
- Interplay between RoPE and balanced ALiBi is underexplored: unclear when both are necessary, whether they conflict or are redundant, and whether per-layer/per-head application or learned positional biases outperform fixed settings.
- Risk of sigmoid saturation and scale drift: no study of temperature/scaling choices for QK·T/√d, gradient saturation, or output rescaling (e.g., post-sigmoid normalization within the window) to ensure stable magnitudes as lengths vary.
- Missing comparisons to alternative normalizations/activations: no head-to-head against temperature-tuned softmax, entmax/sparsemax, linear-kernel attentions (Performer/Transformers), or normalization-free attention variants under SWA training.
- Limited evaluation on true long-context tasks: benchmarks focus largely on short-context commonsense reasoning; no results on LongBench/SCROLLS, Needle-in-a-Haystack/passkey retrieval, long-form QA/summarization (NarrativeQA, GovReport), or book-level tasks requiring far-token recall.
- No empirical “recall vs distance” curves: absence of controlled measurements showing how well information is preserved as a function of token distance and of ω, L, and slope assignments.
- Sliding-window training details are under-specified: stride/overlap policy, caching across window shifts, and curriculum over window size are not systematically studied; their impact on stability and final performance is unknown.
- Open question on adaptive windowing: how to learn or schedule window sizes at train/inference time based on content, compute budget, or confidence (the paper only suggests this as future work).
- Inference/runtime evidence is incomplete: the linear-complexity claim lacks wall-clock throughput, latency, memory, and energy comparisons vs FlashAttention softmax, linear-attention baselines, and state-space models under matched hardware and quality.
- KV-cache and implementation compatibility: no analysis of integration with existing accelerator kernels, FlashAttention variants, or memory-saving schemes; unclear constant-factor overheads of sigmoid+ALiBi+RoPE under production constraints.
- Transfer and retrofitting: no method to convert or fine-tune existing pretrained LLMs to SWAT without full retraining; distillation/adapter-based pathways and their performance/compute trade-offs remain unexplored.
- Scope beyond decoder-only LMs: unclear how SWAT extends to encoder-only/encoder–decoder models, bidirectional pretraining, or masked objectives.
- Robustness and distractor resilience: no tests under adversarial distractors, noisy long inputs, topic shifts, or domain transfer to assess whether dense sigmoid attention better resists recency bias or spurious correlations.
- Safety and hallucination impacts: unknown how shifting recency/historical bias (via slope balance) affects hallucination rates, factuality, and calibration on long contexts.
- Scaling behavior and stability: results stop at 760M parameters; no scaling laws vs model/data size, nor evidence of whether benefits persist or diminish at multi-billion-parameter scales.
- Hyperparameter sensitivity is noted but unmapped: there is no systematic exploration surface (ω, L, slope ranges, temperature, RoPE scaling) or automated tuning/regularization strategies to improve robustness.
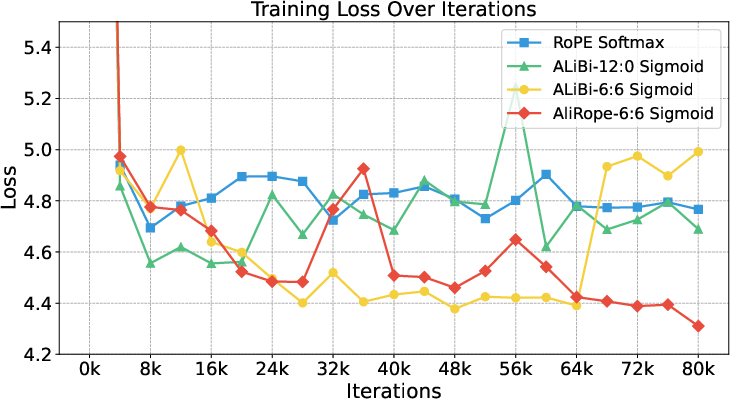
- Ambiguity around “AliRope-6:6” and replication details: exact slope bases, per-layer/head assignments, and training schedules are not fully specified; reproducibility would benefit from exhaustive hyperparameter and implementation disclosure.
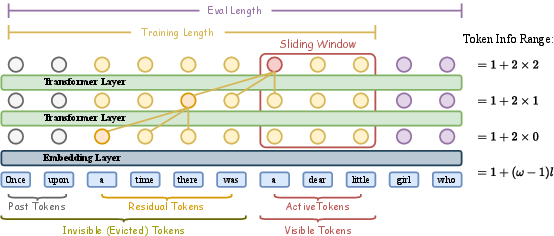
- Maximum effective attention distance remains a hard limit: beyond acknowledging ω×L as a ceiling, no concrete strategies are tested to extend it (e.g., hierarchical compression tokens, memory modules, retrieval-augmented hybrids) within the SWAT framework.
- Limited task breadth: minimal coverage of instruction following, multi-step reasoning (beyond commonsense), code generation (e.g., HumanEval), multilingual settings, or multimodal inputs; generality remains unverified.
- Normalization-free attention side effects: absence of analysis on log-likelihood calibration, uncertainty estimation, and downstream decision thresholds when attention weights are unnormalized.
Collections
Sign up for free to add this paper to one or more collections.

