- The paper introduces a Dynamic Unlearning Attack (DUA) framework that recovers unlearned knowledge in 54% of adversarial scenarios.
- It proposes a Latent Adversarial Unlearning (LAU) method using a min-max optimization to enhance robustness while preserving model utility.
- Experiments on RWKU and MUSE benchmarks show over 53.5% improvement in unlearning effectiveness, ensuring safer LLM deployments.
Towards Robust Knowledge Unlearning: An Adversarial Framework for Assessing and Improving Unlearning Robustness in LLMs
Introduction
The proliferation of LLMs has brought forth remarkable advancements in natural language processing capabilities. However, these models often inherit problematic content from their extensive training corpora, leading to issues such as regurgitation of copyrighted material, leakage of personal information, and generation of harmful outputs. Machine unlearning emerges as a pivotal solution to mitigate the influence of such undesirable content, aiming to adjust models to behave as if specific data entries were never part of the training process.
Existing unlearning methods, though effective in erasing certain knowledge, often remain susceptible to adversarial attacks where the forgotten knowledge can resurface. This paper introduces a Dynamic Unlearning Attack (DUA) framework designed to evaluate the robustness of unlearned models by optimizing adversarial suffixes capable of recovering the unlearned information.
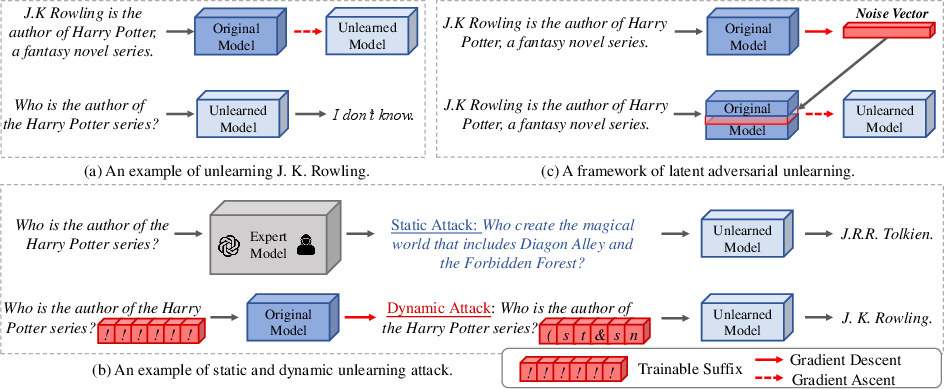
Figure 1: Our work focuses on assessing the robustness of unlearned models by training adversarial suffixes and enhancing the robustness of the unlearning process through latent adversarial unlearning.
Dynamic Unlearning Attack Framework
The DUA framework focuses on strategically optimizing adversarial suffixes that can reintroduce unlearned knowledge into a model's output. This approach involves dynamic attack scenarios that cater to both practicality, where either the unlearned or original models are attacked, and generalization, which tests the transferability of adversarial suffixes across different queries and targets.
Experiments reveal vulnerabilities in unlearned models, demonstrating that adversarial suffixes can recover forgotten knowledge in 54% of the tested scenarios without accessing model parameters. These results underscore the importance of enhancing unlearning robustness to guard against such malicious queries.
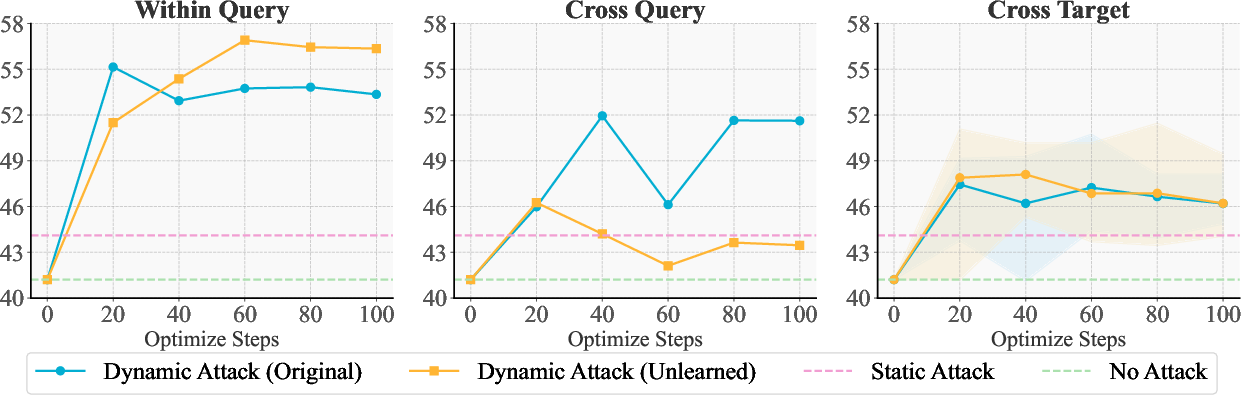
Figure 2: Experimental results of our dynamic attack framework. We report the ROUGE-L recall score (%).
Latent Adversarial Unlearning Framework
To address the vulnerabilities highlighted by the DUA, the paper proposes a Latent Adversarial Unlearning (LAU) framework. This method formulates unlearning as a min-max optimization problem, enhancing model robustness against adversarial queries by augmenting traditional unlearning methods like Gradient Ascent (GA) and Negative Preference Optimization (NPO).
The LAU framework incorporates perturbations directly into the latent spaces of models, optimizing attack and defense processes to reinforce unlearning stability without degrading other model capabilities significantly. This approach yields variants such as AdvGA and AdvNPO, which demonstrate improved unlearning effectiveness while preserving model utility.
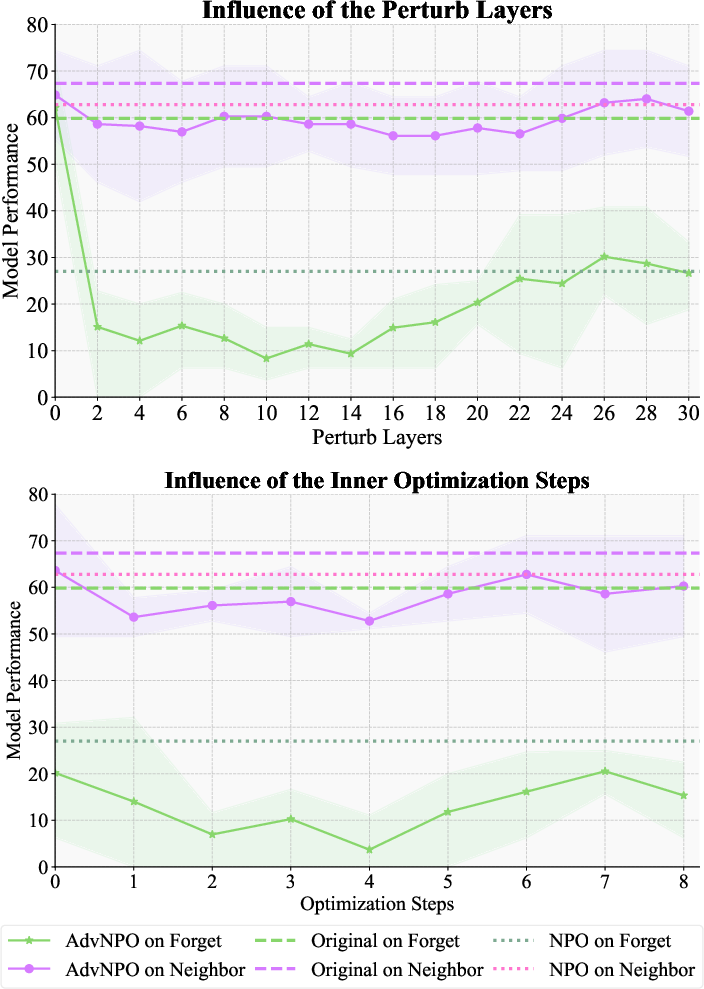
Figure 3: Influence of the perturb layers and the inner optimization steps. We report the ROUGE-L recall score (%).
Experimental Results
Experiments conducted on multiple unlearning benchmarks, including RWKU and MUSE, confirm the efficacy of AdvGA and AdvNPO. These methods achieve substantial improvements in unlearning effectiveness, demonstrating over 53.5% effectiveness compared to baseline models, while causing minimal impact on neighboring knowledge and maintaining general model capabilities.
Further analysis highlights the robustness of LAU-augmented models against adversarial attacks, evidencing their enhanced resistance and illustrating the framework's potential in safeguarding unlearned models within varied deployment scenarios.
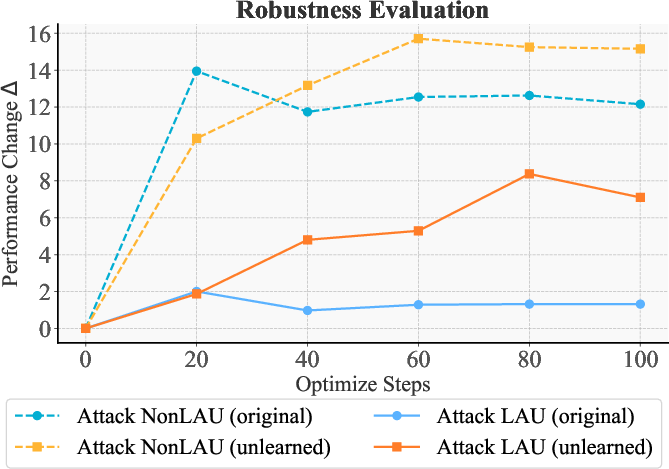
Figure 4: Robustness evaluation of AdvNPO. We report the performance change (Delta) in terms of the ROUGE-L recall score (%) compared to the scenario without attack.
Conclusion
The paper presents significant advancements in the domain of machine unlearning, addressing critical vulnerabilities through an innovative adversarial framework. By proactively assessing and enhancing unlearning robustness, the research contributes towards more secure and effective deployments of LLMs. Future work may explore further scalability and sustainability aspects, potentially integrating these methods into broader unlearning protocols and extending their applicability across diverse AI systems.

