- The paper introduces a novel two-phase approach using embedding alignment for LLM unlearning to effectively remove targeted concepts.
- It details an alignment pre-training phase followed by iterative adversarial unlearning that minimizes cosine similarity with target embeddings.
- Experimental results show reduced Forget QA accuracy and preserved model utility, highlighting the trade-off between forgetting and retention.
Embedding Alignment for LLM Unlearning
The paper "Align-then-Unlearn: Embedding Alignment for LLM Unlearning" (2506.13181) introduces a novel unlearning framework for LLMs that operates in the semantic embedding space. This approach addresses the limitations of existing token-based unlearning methods, which often fail to completely remove targeted knowledge and are susceptible to prompt rephrasing. The core idea is to augment an LLM with an embedding prediction module, which is then used to minimize the similarity between predicted embeddings and a target embedding representing the concept to be removed.
Methodological Overview
The Align-then-Unlearn framework comprises two primary phases: alignment pre-training and unlearning. During alignment pre-training, the LLM is augmented with an embedding prediction module (E), parameterized by θE, which learns to predict future semantic embeddings. The LLM (M) is parameterized by θM.
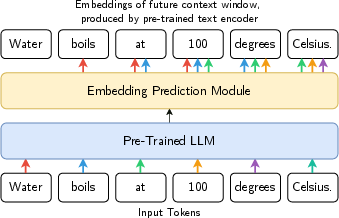
Figure 1: Align-then-Unlearn predicts a single embedding representing the next k tokens, rather than individual tokens.
The alignment loss, Lalign, minimizes the cosine distance between predicted embeddings (e^t) and reference embeddings (et), derived from the ground-truth future window using a frozen, pre-trained text encoder such as MPNet. The optimization objective for the embedding predictor is:
$\theta_E^* = \arg\min_{\theta_E} \mathbb{E}_{x_{1:T}\left[ \mathcal{L}_{\text{align} \right]}.$
In the subsequent unlearning phase, the LLM parameters are fine-tuned to reduce the similarity between the predicted embeddings and the target unlearning concepts. A concept description (e.g., "Stephen King") is converted into a target embedding (eunlearn) using the same frozen encoder. The unlearning loss, Lunlearn, minimizes the cosine similarity between e^t and eunlearn, with a margin threshold τ. The optimization is expressed as:
$\theta_M^* = \arg\min_{\theta_M} \mathbb{E}_{x_{1:T}\left[ \mathcal{L}_{\text{unlearn} \right]}.$
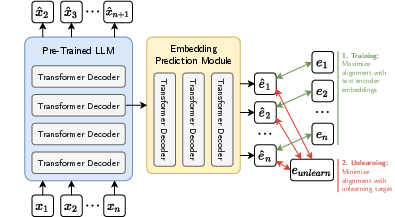
Figure 2: An overview of the Align-then-Unlearn architecture.
To prevent early convergence, the method alternates between realigning the prediction head and continuing unlearning in the main model. This iterative process fosters an adversarial dynamic, enhancing the robustness of the unlearning process.
Robustness Analysis
The framework's robustness stems from the iterative process that alternates between minimizing the unlearning loss for the LLM ($\mathcal{L}_{\text{unlearn}(\theta_M, \theta_E)$) and realigning the embedding prediction head ($\theta_E^* = \arg\min_{\theta_E} \mathcal{L}_{\text{align}(\theta_E, \theta_M^{\text{updated}})$). This creates an adversarial dynamic where the LLM updates to obscure the unlearning target from the embedding prediction head, while the embedding prediction head improves its ability to predict future semantics from the LLM's states.
The paper argues that robust unlearning requires the LLM to alter its representations so that even an optimally realigned embedding prediction head produces predictions with minimal similarity to the unlearning target. The authors suggest that full suppression of the unlearning target may suppress related concepts, reducing overall utility. They propose that partial unlearning via early stopping or thresholded objectives is preferable.
Experimental Evaluation
The effectiveness of Align-then-Unlearn was evaluated using the Real-World Knowledge Unlearning (RWKU) benchmark. The Phi-3-mini-4k-instruct model served as the base LLM, while all-mpnet-base-v2 was used as the pre-trained text encoder. Key metrics included Forget Score (measuring remaining knowledge of the unlearning target), Neighbor Score (measuring retained knowledge about related concepts), and Utility Score (measuring the general capability of the model after unlearning).
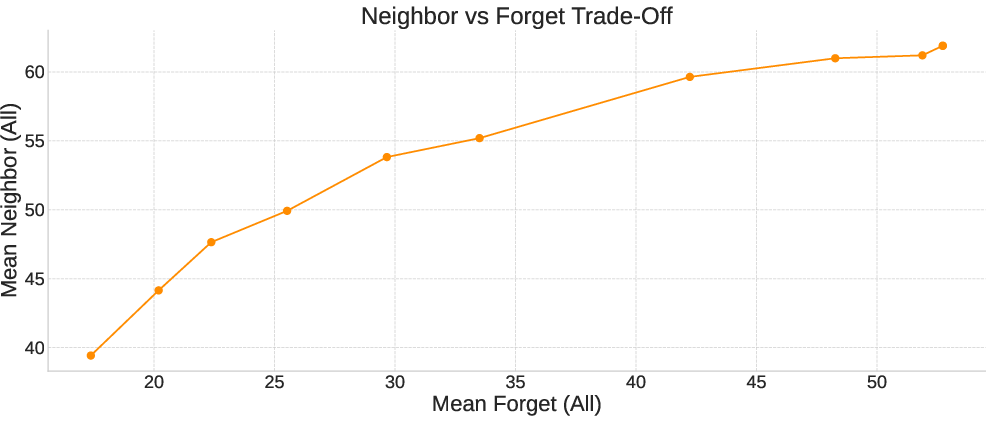
Figure 3: The tradeoff between effective forgetting and retention of related knowledge.
The method was compared against SOTA unlearning methods, and results were reported at different checkpoints based on the average accuracy on forget tasks. Align-then-Unlearn demonstrated effective removal of target information, reducing Forget QA accuracy to 13.5\% while maintaining overall model utility, achieving 64.5\% accuracy on MMLU. Analysis of the forgetting–performance trade-off revealed that stronger forgetting typically reduces knowledge of nearby concepts.
Further experiments explored applying Align-then-Unlearn at different layers (10, 20, and 30) of the Phi-3-mini-4k-instruct model. The results indicated that no single layer consistently outperformed others, though individual targets exhibited clear differences.
Conclusions and Future Directions
The Align-then-Unlearn framework presents a promising approach to LLM unlearning by focusing on conceptual similarity rather than specific tokens. Key advantages include data-efficient unlearning and fine-grained control over the scope of unlearning.
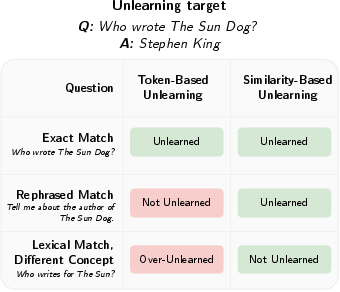
Figure 4: Token-based unlearning fails on rephrasings and over-forgets unrelated knowledge.
The authors identify limitations such as the need for dynamic threshold adjustment and the potential for overgeneralization, which may inadvertently affect related concepts. Future research directions include exploring dynamic threshold adjustment, applying the embedding prediction module to multiple or specific layers, joint training of the encoder and embedding head, and evaluating effectiveness for unlearning exact text sequences.
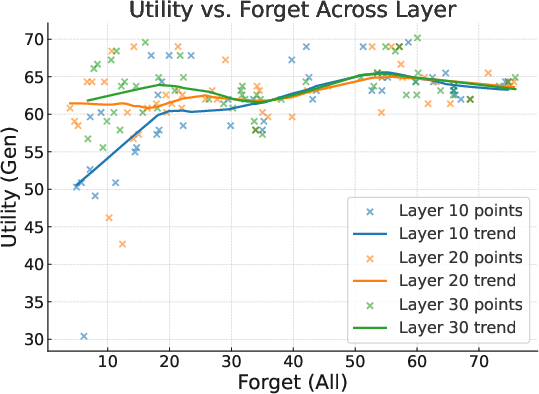
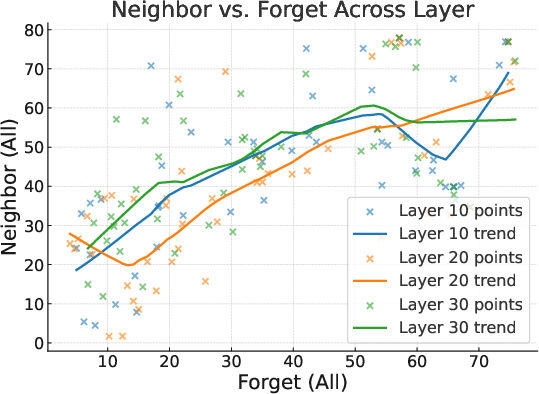
Figure 5: The tradeoff between forgetting and model performance.
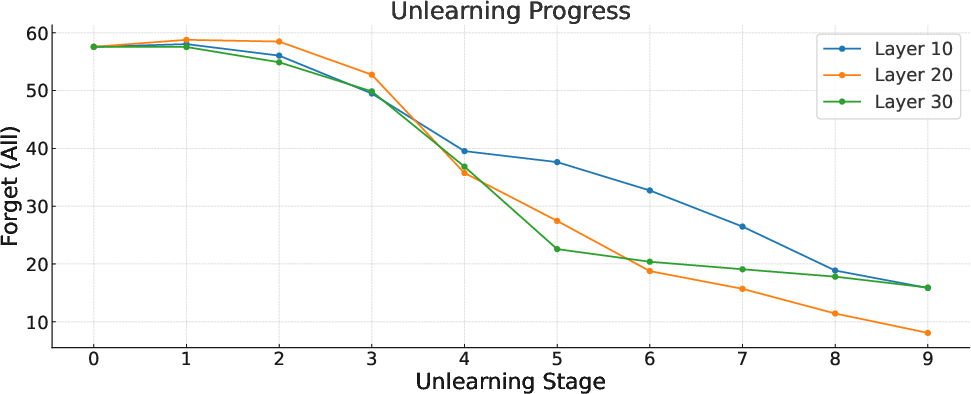
Figure 6: Comparison of forget scores over time when applying unlearning to different layers.

