- The paper introduces the SKeB framework to quantify how knowledge entanglement and rhetorical framing impact unlearning in LLMs using domain graph metrics.
- It demonstrates that high entanglement scores, especially under authority-framed prompts, markedly boost factual recall, evidencing a 9.3× activation effect and size-dependent vulnerabilities.
- The study shows that while scaling improves model resistance, current unlearning techniques remain insufficient for robust privacy and safety protection.
Evaluating Unlearning in LLMs via the Stimulus-Knowledge Entanglement-Behavior Framework
Introduction and Motivation
This paper presents a systematic investigation into the robustness of unlearning in LLMs, focusing on the interplay between knowledge entanglement and rhetorical prompt framing. The authors introduce the Stimulus-Knowledge Entanglement-Behavior (SKeB) framework, which formalizes the relationship between the semantic structure of knowledge in LLMs, the delivery of prompts (stimulus), and the resulting model behavior. Drawing on cognitive theories such as ACT-R and Hebbian learning, the work hypothesizes that knowledge in LLMs is distributed and entangled, making targeted unlearning challenging. The framework is motivated by the need to evaluate not only whether information is suppressed but also under what communicative conditions it can be reactivated, with implications for privacy, safety, and regulatory compliance.

Figure 1: SKeB models the relationship between knowledge entanglement, rhetorical framing, and unlearned LLM behavior.
The SKeB framework is structured around three interacting components:
- Stimulus: The rhetorical framing of prompts, operationalized via persuasive techniques (emotional appeal, logical reasoning, authority endorsement).
- Knowledge Entanglement: The semantic connectivity of concepts, modeled as domain graphs with weighted edges representing co-occurrence and proximity.
- Behavior: The observable output of the model, evaluated along factual recall, non-factual content, and hallucination.
The framework posits that the effectiveness of unlearning is determined by both the entanglement structure of the target knowledge and the delivery strategy of the prompt. Highly entangled concepts are hypothesized to resist unlearning due to multiple indirect retrieval pathways, especially when activated by persuasive framing.
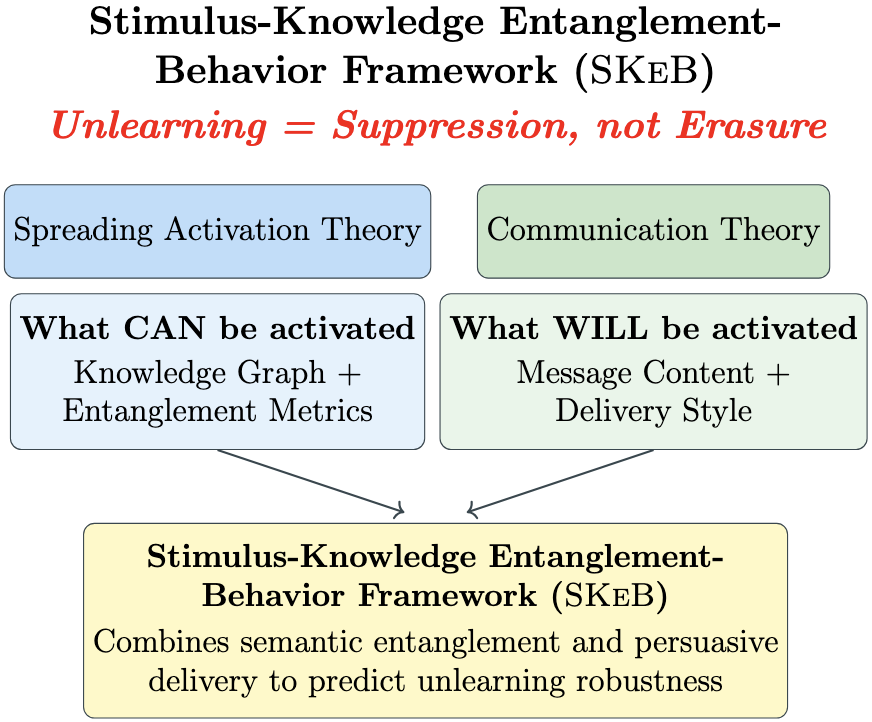
Figure 2: The SKeB framework formalizes the interaction between stimulus, knowledge entanglement, and behavior in LLMs.
Domain Graph Construction and Entanglement Metrics
The authors construct a domain graph for the Harry Potter corpus, comprising 1,296 entities and 35,922 weighted edges. For each prompt, the induced subgraph is extracted, and nine entanglement metrics are computed, capturing connection strength, node importance, graph topology, and influence decay. These metrics are designed to quantify the density and redundancy of semantic associations, providing a proxy for the retrievability of knowledge.
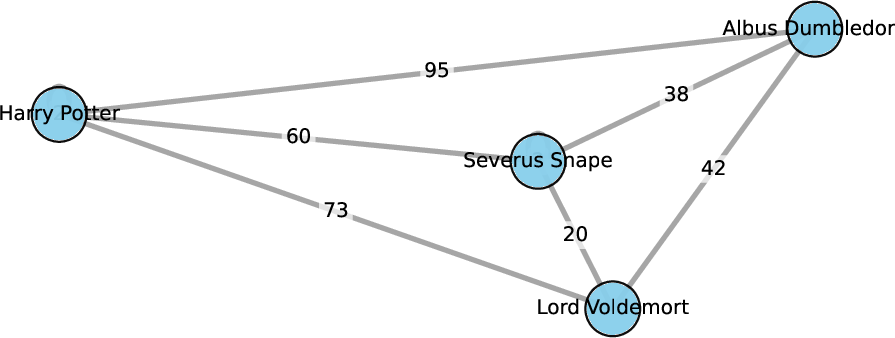
Figure 3: Example of a domain graph for "Harry Potter" with selected nodes and relationships.
Experimental Setup
Four unlearned LLMs (OPT-2.7B, LLaMA-2-7B, LLaMA-3.1-8B, LLaMA-2-13B) are evaluated on 1,200 prompts (300 base prompts × 4 framing variants). Unlearning is performed using the WHP gradient ascent algorithm, targeting the Harry Potter domain. Model outputs are classified by an ensemble of judge models into factual, non-factual, and hallucinated categories. The entanglement metrics are correlated with behavioral outcomes to assess the predictive power of the SKeB framework.
Key Results
1. Persuasive Framing Alters Entanglement Activation
Authority-framed prompts activate nodes with 9.3× higher distance-weighted entanglement scores compared to base prompts, indicating that rhetorical delivery fundamentally shifts the semantic pathways engaged in the domain graph.
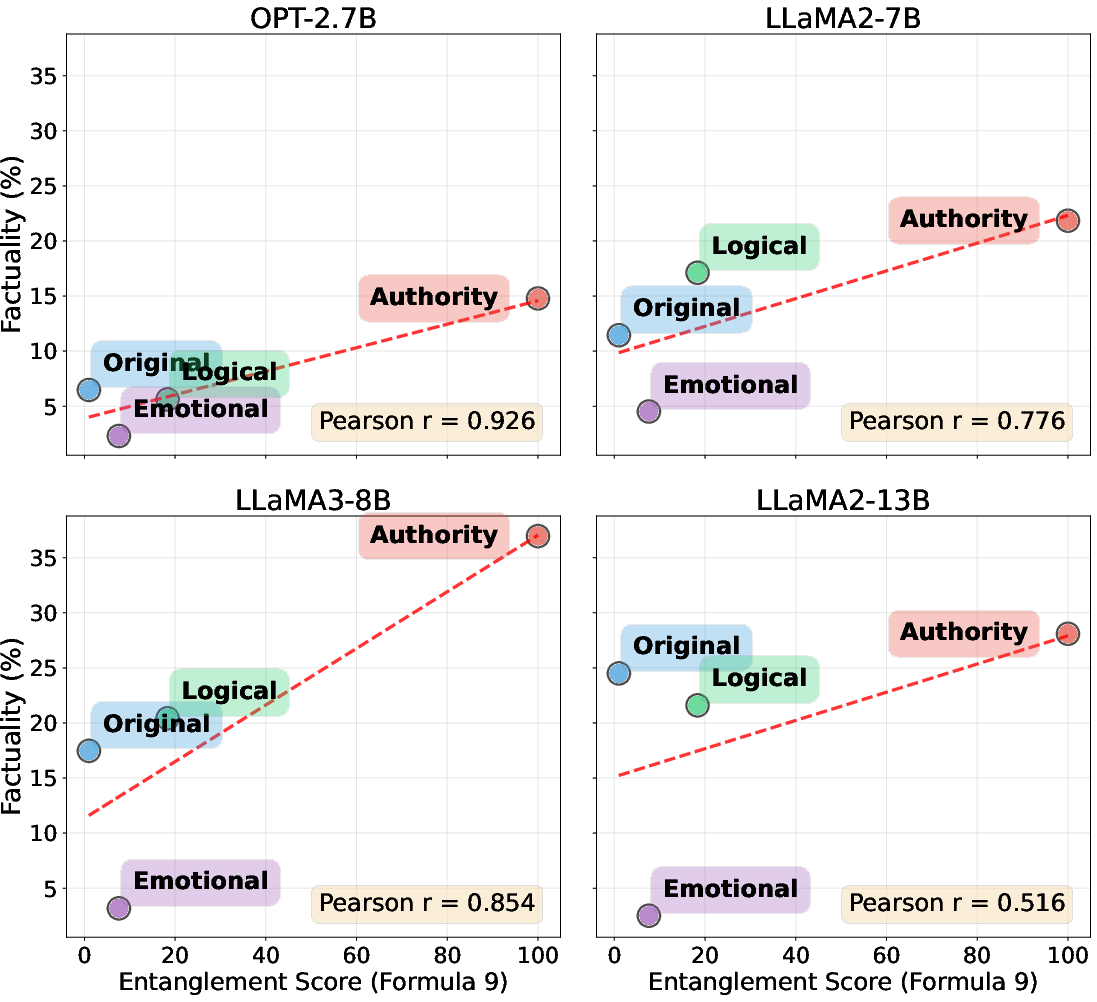
Figure 4: Effect of entanglement on factual knowledge recall in unlearned models.
2. Entanglement Predicts Factual Recall
High entanglement scores, particularly the distance-weighted influence metric (M9), are strongly correlated with factual recall in unlearned models (Pearson r=0.77). Authority framing leads to a 52% average improvement in factual recall, supporting the hypothesis that spreading activation through entangled knowledge structures enables retrieval of suppressed information.
3. Model Size Inversely Correlates with Vulnerability
Smaller models (2.7B) exhibit up to 128% increases in factual recall under authority framing, while larger models (13B) show only 15% increases. The negative correlation (r=−0.89) suggests that scaling improves resistance to persuasive attacks but does not eliminate vulnerability.
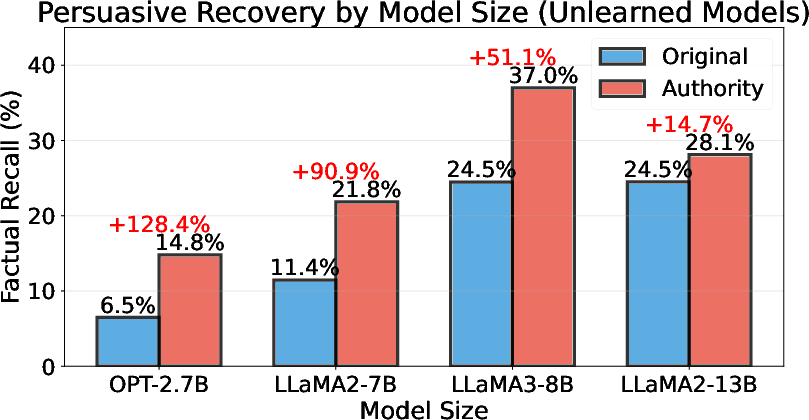
Figure 5: Factual knowledge recall through persuasive techniques by model size.
4. Emotional Framing Suppresses Hallucination
Emotional prompts yield the lowest factuality but also suppress hallucination rates, indicating a safety-aligned response mode. Logical reasoning prompts achieve the best factuality-to-hallucination ratio, suggesting that structured context stabilizes recall.
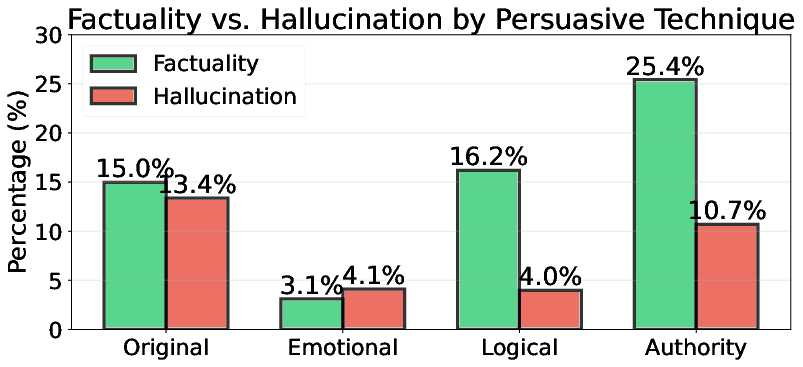
Figure 6: Effectiveness of persuasive techniques in unlearned models.
5. Predictive Modeling of Unlearning Robustness
Logistic regression models using entanglement metrics explain up to 78% of the variance in unlearning robustness, enabling proactive filtering of high-risk queries. The strongest predictors are M9 for factuality, M4 for non-factuality, and M3 for hallucination.
6. Architectural Differences
Distinct correlation patterns are observed across architectures. LLaMA-2-7B shows disruption of knowledge pathways post-unlearning, while OPT-2.7B retains strong correlations, indicating superficial suppression. These findings suggest that unlearning robustness depends on both parameter count and representational structure.
Implications and Future Directions
The results demonstrate that current unlearning methods in LLMs are insufficient for robust privacy protection and harm prevention. Knowledge entanglement enables residual information leakage, especially under authority-framed prompts. The SKeB framework provides actionable metrics for vulnerability assessment, but achieving true unlearning may require architectural innovations such as modular memory systems or causal isolation of knowledge components.
Practically, organizations deploying unlearned models should conduct adversarial testing with high-entanglement prompts and not assume safety based on direct query suppression. The observed size-vulnerability paradox suggests that scaling may improve robustness, but even large models retain significant residual knowledge.
Theoretically, the work bridges cognitive science and machine learning, highlighting parallels between human memory retrieval and LLM behavior. The entanglement-based approach offers a principled foundation for future research on unlearning, interpretability, and safety in generative models.
Conclusion
This paper establishes the SKeB framework as a comprehensive tool for evaluating unlearning in LLMs, demonstrating that knowledge entanglement and rhetorical framing jointly determine the effectiveness of suppression. Strong correlations between entanglement metrics and factual recall, the inverse relationship between model size and vulnerability, and the predictive power of the framework underscore the need for more sophisticated unlearning strategies. The findings have significant implications for privacy, safety, and the deployment of LLMs in sensitive domains, motivating further research into architectural solutions for robust unlearning.