- The paper presents JensUn, a method leveraging Jensen-Shannon Divergence to achieve utility-preserving and robust unlearning of LLMs under rigorous evaluation.
- It introduces a novel evaluation framework using LLM-based semantic judges and worst-case paraphrase assessments to accurately measure forgetting.
- Empirical results show that JensUn effectively eliminates targeted knowledge while maintaining high performance on retain sets and resisting benign relearning.
Utility-Preserving, Robust, and Almost Irreversible Unlearning in LLMs: The JensUn Approach
Introduction and Motivation
The proliferation of LLMs has intensified the need for effective machine unlearning—removing specific knowledge from a model without retraining from scratch. This is critical for privacy, copyright compliance, and safety, especially when models inadvertently memorize sensitive or harmful information. However, existing unlearning methods often fail under rigorous evaluation, either leaving residual knowledge or degrading model utility. The paper introduces JensUn, a method leveraging Jensen-Shannon Divergence (JSD) as the core loss for both forget and retain sets, aiming to achieve stable, utility-preserving, and robust unlearning. The work also proposes a comprehensive evaluation framework, including a new dataset (LKF), semantic LLM-based judges, and worst-case paraphrase-based assessments.
The JensUn Method: JSD-Based Unlearning
JensUn formulates unlearning as a multi-objective optimization over a forget set DF and a retain set DR:
Lunlearning(θ)=λFLF(θ,DF)+λRLR(θ,DR)
- Forget Loss (LF): Minimize the JSD between the model output and a fixed target (e.g., a refusal string like "No idea" or a non-informative token sequence) for each token in the forget set.
- Retain Loss (LR): Minimize the JSD between the unlearned model's output and the base model's output on the retain set, preserving general capabilities.
The JSD is symmetric and bounded, providing stable gradients and preventing catastrophic forgetting or utility collapse. This enables longer, more stable fine-tuning compared to unbounded losses (e.g., cross-entropy or KL-divergence), which can destabilize the model.
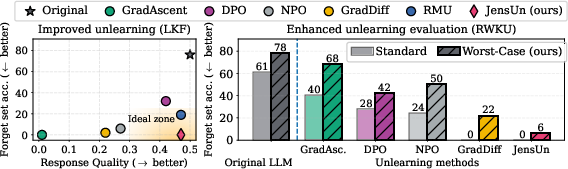
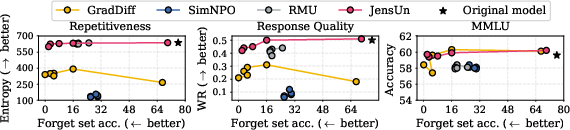
Figure 1: JensUn yields the best trade-off between unlearning quality (forget set accuracy) and utility of the LLM.
Implementation Details
- Target Selection: The target for the forget loss can be a refusal string, whitespace, or random tokens. Empirically, all yield similar unlearning efficacy, allowing for application-specific customization.
- Optimization: Standard AdamW optimizer with cosine learning rate scheduling is used. Hyperparameters λF and λR are tuned to balance forgetting and utility.
- Retain Set Construction: For QA-based datasets, the retain set should be semantically related but disjoint from the forget set to avoid leakage.
- Training Regime: Fine-tuning is performed for 10–60 epochs, with or without paraphrased queries, depending on the dataset.
Evaluation Framework: Beyond ROUGE
The paper identifies critical flaws in standard unlearning evaluation protocols, particularly the use of ROUGE-L, which is insensitive to semantic correctness and paraphrasing.
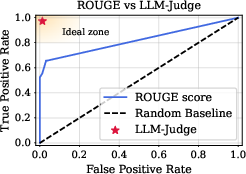
Figure 2: ROUGE-L can misjudge unlearning success; LLM-based semantic judges align better with human evaluation.
Key Evaluation Innovations
Empirical Results
Forget-Utility Trade-off
JensUn consistently achieves the lowest forget set accuracy (0% in LKF, 6.1% in RWKU QA) while maintaining high utility (measured by MMLU, response repetitiveness, and win rate vs. the base model). Competing methods either fail to fully forget or suffer significant utility degradation.
- GradAscent/GradDiff: Can achieve low forget accuracy but often collapse utility, producing degenerate outputs.
- NPO/SimNPO: Sensitive to hyperparameters; can either under-forget or degrade utility.
- JensUn: Bounded loss ensures stable optimization, allowing for longer unlearning without utility collapse.
Robustness to Benign Relearning
A critical property for practical unlearning is resistance to benign relearning—where the model is fine-tuned on unrelated data post-unlearning. JensUn demonstrates strong resilience: after extensive relearning, forget set accuracy remains low, and utility is preserved, unlike NPO or NPO+SAM, which are vulnerable to knowledge recovery.
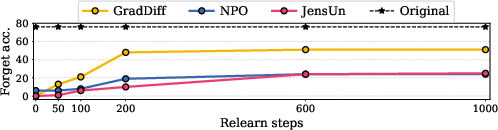
Figure 4: Forget set accuracy saturates after certain relearning steps; JensUn resists benign relearning more effectively than alternatives.
Evaluation Protocol Impact
Switching from ROUGE to LLM-Judge and worst-case paraphrase evaluation reveals that prior benchmarks overestimated unlearning quality by up to 43%. This exposes the inadequacy of previous protocols and underscores the necessity of robust, adversarial evaluation.
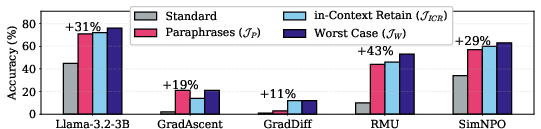
Figure 5: Worst-case evaluation over paraphrases and in-context retain samples significantly increases measured forget set accuracy, providing a more stringent assessment.
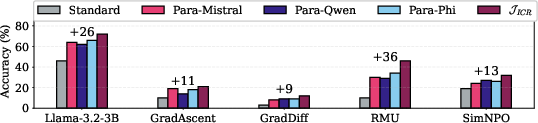
Figure 6: Diversity in paraphrase generation is crucial; worst-case over paraphrases reveals hidden residual knowledge.
Training Dynamics
JensUn's training curves show that forget set accuracy drops to zero rapidly, but optimal retain set performance is only recovered after further fine-tuning, highlighting the importance of balanced loss scheduling.
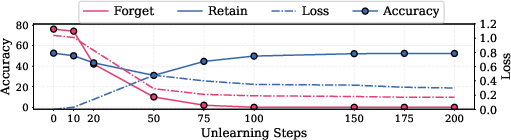
Figure 7: Training dynamics of JensUn show rapid forgetting followed by gradual recovery of retain set utility.
Practical and Theoretical Implications
- Deployment: JensUn enables LLM providers to remove specific knowledge with minimal impact on general capabilities, supporting compliance with privacy regulations and user requests for data removal.
- Evaluation: The proposed framework sets a new standard for unlearning assessment, emphasizing semantic correctness and adversarial robustness.
- Scalability: The method is compatible with standard LLM fine-tuning pipelines and does not require architectural changes or retraining from scratch.
- Limitations: The approach assumes access to a well-defined forget/retain split and may require substantial paraphrase generation for robust evaluation. Computational cost is dominated by LLM-Judge inference and paraphrase generation, but these are parallelizable.
Future Directions
- Automated Paraphrase Generation: Integrating more diverse and adversarial paraphrasing strategies could further strengthen evaluation.
- Unlearning at Scale: Extending JensUn to larger models and more complex knowledge structures (e.g., multi-hop reasoning, code) remains an open challenge.
- Theoretical Guarantees: Formalizing irreversibility and robustness properties under various attack models is a promising direction.
- Integration with Model Editing: Combining unlearning with targeted model editing could enable fine-grained control over LLM knowledge.
Conclusion
JensUn establishes a new state-of-the-art in LLM unlearning by leveraging the boundedness and stability of the Jensen-Shannon Divergence, achieving superior forget-utility trade-offs and robustness to relearning. The accompanying evaluation framework exposes the limitations of prior benchmarks and provides a rigorous, semantically grounded protocol for future research. This work lays the foundation for trustworthy, utility-preserving unlearning in large-scale LLMs, a prerequisite for their safe and responsible deployment.