Cosmos-Predict 2.5: The Future of World Simulation
This presentation explores the development of Cosmos-Predict 2.5 and Transfer 2.5, a suite of video foundation models designed specifically for Physical AI. We cover the shift to Flow Matching, high-fidelity data curation, and a comprehensive post-training stack including RL and model merging to solve the challenges of training robots and autonomous systems in realistic, controllable environments.Script
What if we could train robots and self-driving cars in a digital world so realistic that it was indistinguishable from the physical one? The authors present Cosmos-Predict 2.5, a unified world foundation model designed to simulate the physical universe with high fidelity.
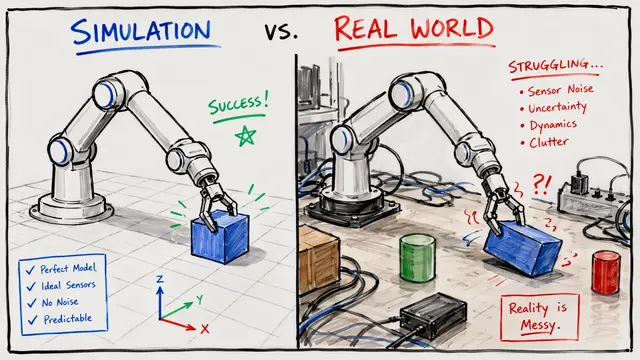
Building physical AI faces a massive bottleneck because training in the real world is simply too dangerous and inefficient. While classical simulators exist, they often fail to capture the messy complexity of reality, creating a desperate need for high-fidelity world models.
Building on this need, the researchers developed a unified architecture that utilizes Flow Matching instead of standard diffusion to predict environment dynamics. By integrating 3D relative positional embeddings, the system can generate stable, 93-frame video sequences from text, images, or existing video clips.
To ensure the model understands physics, the authors curated a massive dataset by filtering 35 million hours of video down to 200 million high-quality clips. They used an advanced vision-language model to create detailed captions, focusing specifically on real-world domains like robotics and autonomous driving.
Transitioning from raw training to optimization, let us examine the post-training stack that polishes these models for expert use.
This figure demonstrates how targeted supervised fine-tuning significantly boosts performance across diverse environments. By training on specialized datasets for robotics or human dynamics and then merging the results, the researchers created a model that excels across all physical categories simultaneously.
Beyond fine-tuning, the team applied reinforcement learning using a reward model called VideoAlign to sharpen visual quality and motion. To make the system practical for real-time applications, they distilled the model so it can generate frames in just 4 steps without losing benchmark accuracy.
The practical results are impressive, ranging from simulating 7 synchronized camera views for autonomous vehicles to enabling Sim2Real translation. In robot experiments, policies trained with this synthetic data saw a success rate jump from 1 out of 30 to 24 out of 30 in adversarial conditions.
This work provides a robust foundation for the future of Physical AI, outperforming prior models while remaining smaller and more efficient. By releasing the code and checkpoints, the authors have opened the door for a new generation of safer, more capable autonomous systems.
Thank you for exploring this breakthrough in world simulation; you can head over to EmergentMind.com to learn more about this paper. Cosmos-Predict 2.5 proves that high-fidelity video generation is the key to unlocking scalable and safe autonomous intelligence in the real world.