TIPSv2: Teaching Vision Models to See Words in Every Pixel
TIPSv2 introduces a breakthrough in vision-language AI by achieving unprecedented patch-level alignment between images and text. Through three key innovations—iBOT++ loss that supervises all image patches, head-only exponential moving averages for efficient training, and multi-granularity synthetic captions—the framework enables models to understand language at the pixel level, not just globally. This advancement sets new standards across 20 benchmarks, particularly excelling in zero-shot semantic segmentation and open-vocabulary tasks while maintaining efficiency.Script
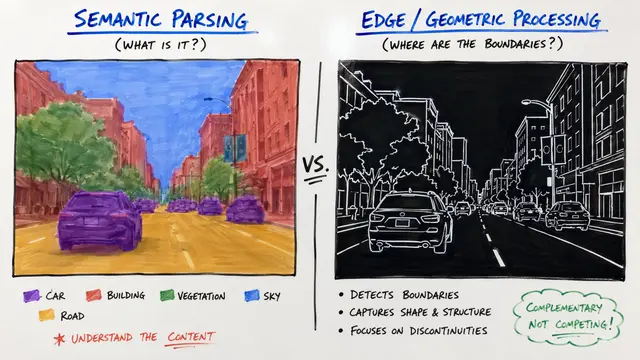
Most vision AI models understand images and text at a global level, matching entire pictures to captions. But what if we need the model to know which pixels correspond to which words? The authors of TIPSv2 discovered something surprising: when distilling knowledge into smaller models, students can actually surpass their teachers at this precise patch-to-text alignment, completely reversing the usual hierarchy.
The key innovation is iBOT++, which breaks from conventional masked image modeling. Instead of computing loss only on masked patches, iBOT++ supervises all patch tokens, both masked and visible. This seemingly simple change creates a consistent anchor between student and teacher representations, dramatically improving how well individual patches align with language.
TIPSv2 also introduces multi-granularity captioning, mixing web alt-text with synthetic captions from PaliGemma and Gemini. By training on captions with diverse levels of detail, from terse to richly descriptive, the model learns robust representations that capture both coarse semantics and fine-grained spatial concepts.
The results are striking. TIPSv2 achieves state-of-the-art performance across 20 benchmarks spanning nine task categories. On zero-shot semantic segmentation, the framework vastly outperforms prior methods on ADE20k, Pascal Context, and Pascal VOC, all while using more efficient training protocols than competitors.
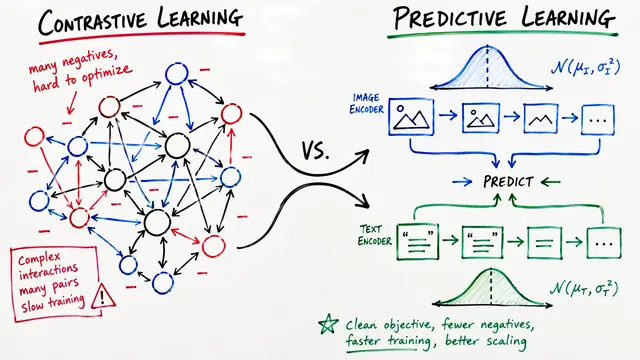
Efficiency matters too. By restricting exponential moving average updates to just the projection head rather than the entire encoder, TIPSv2 dramatically reduces memory requirements while maintaining training stability. The contrastive loss itself prevents representational collapse, eliminating the need for a full model copy as teacher.
TIPSv2 fundamentally shifts how vision models understand language, teaching them to align words not just with whole images but with individual pixels. This precise spatial grounding unlocks new possibilities for open-vocabulary segmentation and dense vision reasoning. To explore how these advances could transform your own multimodal applications, visit EmergentMind.com and create videos from the latest research.