DINOv2: Self-Supervised Vision Foundation
This presentation explores DINOv2, a revolutionary self-supervised Vision Transformer that serves as a universal backbone for computer vision tasks. We'll examine its architectural innovations, self-supervised training paradigm, curated data pipeline, and remarkable performance across classification, segmentation, and retrieval tasks without requiring labeled data.Script
What if a computer vision model could learn to see the world without ever being told what it's looking at? DINOv2 achieves exactly this breakthrough, creating a universal visual backbone that masters everything from image classification to dense segmentation through pure self-supervised learning.
Let's start by understanding what makes DINOv2's architecture so powerful.
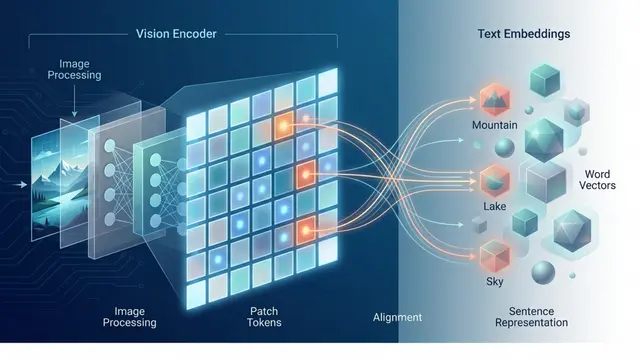
Building on this foundation, DINOv2 comes as a complete family of Vision Transformers, ranging from efficient small models to massive billion-parameter variants. Each model processes images by dividing them into patches and learning rich representations through transformer blocks.
These aren't just standard transformers though. DINOv2 introduces several key innovations including separate heads for different learning objectives and efficient attention mechanisms that make training at massive scale actually feasible.
What makes this architecture truly versatile is its dual-purpose design. The same model simultaneously produces global image understanding for tasks like classification and detailed spatial features perfect for dense prediction tasks like segmentation.
Now let's explore how DINOv2 learns without any labeled data.
At the heart of DINOv2's learning is an elegant teacher-student setup. The student network learns by trying to match the outputs of a teacher network, which itself evolves as a moving average of the student's parameters.
Beyond basic distillation, DINOv2 combines multiple self-supervised objectives. The iBOT loss learns spatial understanding by predicting masked image regions, while sophisticated regularizers ensure the model learns diverse and stable representations.
The training process itself required breakthrough engineering. DINOv2 combines efficiency innovations like mixed precision and gradient sharding with stability measures like carefully tuned schedules and separated learning heads.
But even the best architecture means nothing without the right training data.
Unlike previous models that relied on uncurated web data, DINOv2 trains on LVD-142M, a carefully assembled dataset of 142 million images. The key innovation here is using only pixel content for curation, completely avoiding metadata biases.
This curation process is remarkably sophisticated, using distributed clustering across 100,000 image groups and advanced deduplication techniques. The result is a dataset that's both diverse and balanced, setting the foundation for truly generalizable visual features.
So how does this self-supervised approach actually perform in practice?
The results are remarkable. DINOv2 matches or exceeds supervised models on ImageNet classification while showing exceptional robustness on challenging out-of-distribution datasets where other models typically struggle.
But classification is just the beginning. The dense patch-level features excel at pixel-wise tasks like segmentation and depth estimation, proving that DINOv2's spatial understanding rivals task-specific architectures.
Perhaps most impressively, these features work beautifully for retrieval and cross-modal tasks, often requiring no fine-tuning at all. You can literally freeze the backbone and achieve state-of-the-art results on new tasks.
This versatility has led to adoption across incredibly diverse domains.
From medical imaging to autonomous driving, DINOv2's universal features adapt remarkably well. The key insight is that good visual representations learned on natural images transfer beautifully to specialized domains with minimal adaptation.
What's particularly elegant is how efficiently DINOv2 transfers. Whether through lightweight LoRA adapters, knowledge distillation, or simply frozen feature extraction, it delivers strong performance without massive computational overhead.
DINOv2 also excels at enhancing other models, providing rich semantic signals to systems that might lack class-discriminative features. It's become a go-to backbone for multi-modal fusion and semantic enhancement.
Let's conclude by examining what DINOv2 means for the future of computer vision.
DINOv2 reveals several profound insights about visual learning. Self-supervised methods can truly rival supervised approaches when combined with thoughtful architecture design and systematic data curation rather than just massive scale.
Of course, challenges remain, particularly when there's significant mismatch between natural image pretraining and specialized application domains. But the flexibility of the architecture enables efficient adaptation even in these cases.
DINOv2 represents a fundamental shift toward universal visual understanding through self-supervised learning, proving that the right combination of architecture, training, and data curation can create truly generalizable vision systems. Visit EmergentMind.com to explore more cutting-edge developments in foundation models and self-supervised learning.