Test-Time Scaling Makes Overtraining Compute-Optimal
This presentation examines a fundamental challenge in large language model development: how to optimally allocate compute between training and inference. The authors introduce Train-to-Test scaling laws that unify pretraining costs with test-time inference budgets, demonstrating that when models will use repeated sampling at deployment, the compute-optimal strategy is dramatic overtraining—training smaller models on far more tokens than traditional Chinchilla scaling recommends. Validated across over 100 models and multiple benchmarks, this work shows that overtrained models consistently outperform larger Chinchilla-optimal models when test-time compute budgets are realistic, with performance gains often exceeding 2x on pass@k metrics.Script
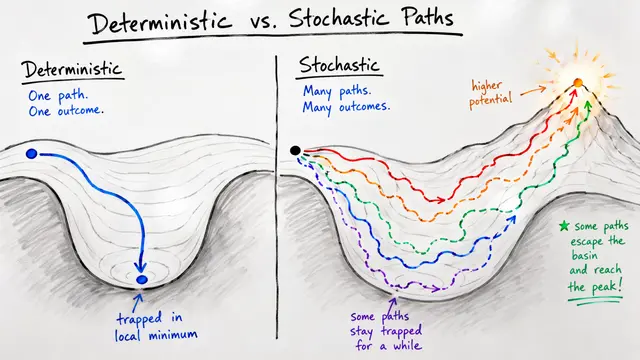
Training a language model is expensive. Running it at inference time is also expensive. For years, researchers optimized these two costs separately, but that turns out to be fundamentally wrong. When your deployment strategy involves sampling multiple responses, the entire game changes.
The problem is Chinchilla scaling, the dominant framework for deciding model size and training duration. It optimizes only pretraining compute and assumes you'll sample each model exactly once at inference. But modern systems generate dozens or hundreds of candidate responses, then select the best. Chinchilla never accounted for that.
The authors introduce a fundamentally different approach.
Train-to-Test scaling laws optimize three variables at once: model size, training tokens, and how many times you sample at inference. The math is explicit. Given your pretraining budget and your deployment inference budget, it tells you the optimal allocation. The authors validated this across more than 100 trained models, spanning standard benchmarks and synthetic reasoning tasks.
This chart shows the result. The Train-to-Test frontier consistently recommends smaller models trained on vastly more tokens than Chinchilla ever would. We're talking about models that see 50, 100, sometimes 200 tokens per parameter, far beyond the canonical 20 tokens per parameter heuristic. Overtraining isn't a bug in this framework. It's the optimal strategy.
The empirical results are striking. On LAMBADA, a 37 million parameter overtrained model achieves 49.9 percent pass@k accuracy. The Chinchilla-optimal model at 455 million parameters? Just 27.3 percent. The same pattern holds across arithmetic reasoning, knowledge retrieval, and spatial tasks. Smaller, heavily overtrained models dominate when you account for realistic test-time sampling budgets. And this advantage persists even after supervised fine-tuning.
The implication is clear: if your deployment involves repeated sampling, and it almost certainly does, then Chinchilla scaling is not just suboptimal, it's actively misleading. Overtraining is the new compute-optimal default. Visit EmergentMind.com to explore this paper further and create your own research videos.