SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via Continuous Integration
This presentation introduces SWE-CI, a groundbreaking benchmark that shifts code intelligence evaluation from static, single-shot correctness to dynamic, long-term codebase maintenance. Through a rigorous dual-agent protocol modeling real-world continuous integration cycles, SWE-CI exposes a critical gap: while leading language models excel at snapshot-based coding tasks, they struggle to maintain code quality and avoid regressions across extended evolutionary cycles. The benchmark reveals that even state-of-the-art models introduce regressions frequently, with most achieving zero-regression rates below 0.25, highlighting the profound distance between current capabilities and truly autonomous software maintenance.Script
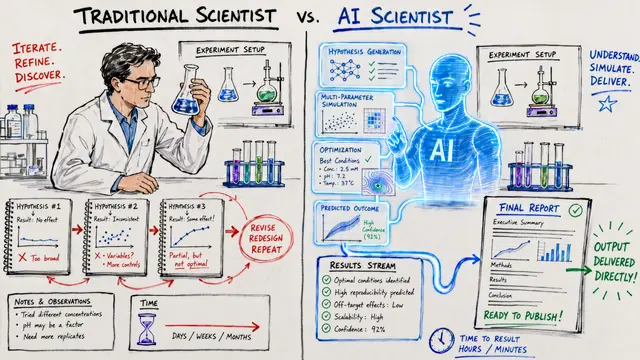
Most AI coding benchmarks measure whether a model can solve a problem once. But software development isn't a snapshot, it's an ongoing conversation with a codebase that evolves for months or years. What happens when you ask an AI agent to maintain code through dozens of commits and hundreds of test changes? That's the question SWE-CI answers, and the results are sobering.
The problem is fundamental. Existing benchmarks treat coding as a one-and-done task. They measure whether an agent can write correct code right now, but they never ask whether that code can survive the next 50 commits. SWE-CI exposes what happens when those early shortcuts and brittle fixes accumulate into unmaintainable systems.
So how do you measure maintainability at scale?
The researchers built SWE-CI from 4,900 repositories, filtering down to 100 high-quality evolutionary transitions. Each sample captures authentic development with complete source, intermediate tests, and pre-built runtimes. Then they introduce a dual-agent protocol: an Architect diagnoses test failures and writes requirements, while a Programmer implements changes. This separation enforces discipline and prevents agents from gaming the system by modifying tests.
The metric innovation is EvoScore. It's a future-weighted mean that prioritizes sustained maintainability over immediate correctness. A model that ships a quick fix but creates fragile code will score poorly when that brittleness surfaces 20 iterations later. This is the first benchmark where technical debt becomes numerically visible.
When the researchers varied the gamma parameter to emphasize long-term performance, provider strategies became starkly visible. Some models, like those from MiniMax and DeepSeek, optimize for the long game. Others chase immediate wins. Claude and Qwen stay robust regardless, suggesting more balanced training. But here's the critical finding: even the best models achieve zero-regression rates below 0.5. Most introduce breaking changes constantly. The gap between static benchmark performance and real-world maintenance capability is enormous.
SWE-CI doesn't just reveal a performance gap, it redefines what performance means for code intelligence. If we want AI agents that can truly participate in software development, they need to maintain codebases, not just write them once. To explore more research like this and create your own videos, visit EmergentMind.com.