Demystifying Reinforcement Learning in Agentic Reasoning
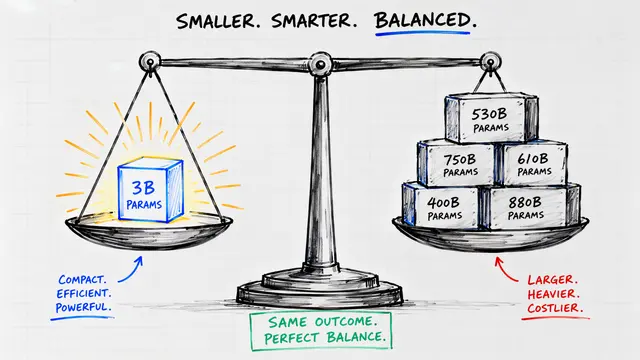
This presentation explores how to train compact language models to reason like agents using reinforcement learning. By systematically examining data quality, algorithmic design, and reasoning strategies, the research reveals that a carefully designed 4-billion-parameter model can match or exceed the agentic reasoning performance of models eight times larger. The findings provide actionable recipes for building autonomous agents that know when to think deeply and when to call tools—unlocking a new path toward efficient, capable AI systems.Script
What if a tiny language model could match the reasoning power of systems eight times its size? This paper reveals how reinforcement learning transforms compact models into capable agents—if you get the recipe right.
Training agents with reinforcement learning raises three hard questions: how agents balance internal reasoning with tool use, how data quality drives effective learning, and how algorithms maintain productive exploration. The authors tackle all three systematically.
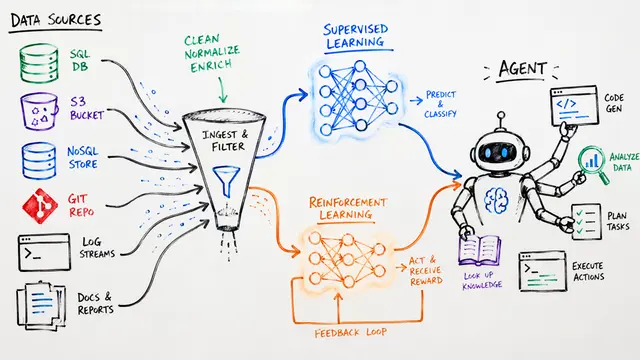
The key insight starts with data.
Real trajectories—capturing the full context of tool invocation—beat synthetic data by over 20 percent on hard math problems. This isn't just about quantity; it's about teaching agents the logic of tool use from authentic examples.
Dataset diversity keeps the agent exploring. Models trained on math alone collapse into narrow strategies, but adding science and code sustains entropy and speeds learning. Model-aware curation—filtering data to match the model's skill level—further sharpens gradient signals and unlocks bottlenecks.
Now, how do you design the learning algorithm itself?
The clipping upper bound controls exploration. Clip too low, and the agent gets stuck. Clip too high, and training becomes unstable. The optimal range—shown here for 4-billion and 7-billion parameter models—balances entropy with convergence. This single knob makes a dramatic difference.
Three techniques stand out: clipping higher with overlong penalties, token-level loss aggregation, and entropy management. Together, they let agents explore broadly without drifting into instability—a balance that conventional reinforcement learning often misses.
Agents that think before acting vastly outperform reactive agents. The deliberative mode—reasoning internally before invoking tools—achieves over 70 percent tool-call success. Reactive agents call tools more often but solve fewer problems. Quality of reasoning beats quantity of actions.
The result is DemyAgent-4B, a model one-eighth the size of its competitors, achieving state-of-the-art agentic reasoning on math, science, and code benchmarks. This proves that with the right data, algorithms, and reasoning strategy, compact models can outthink giants.
Reinforcement learning doesn't just train agents—it reveals how reasoning and tool use intertwine. When a 4-billion-parameter model can rival systems eight times larger, we're not just building smarter agents; we're discovering the principles that make intelligence efficient. To explore more research like this and create your own videos, visit EmergentMind.com.