KARL: Knowledge Agents via Reinforcement Learning
This presentation explores KARL, a breakthrough knowledge agent trained through large-batch reinforcement learning to master complex grounded reasoning tasks. Unlike previous approaches limited to narrow benchmarks or open-domain questions, KARL tackles six structurally distinct closed-corpus challenges—from constraint-driven entity search to technical documentation reasoning—using only vector search as its tool. Through systematic synthetic data generation, off-policy RL optimization, and intelligent test-time compute scaling, KARL achieves state-of-the-art performance while offering superior cost and latency tradeoffs compared to closed-source models like Claude Opus.Script
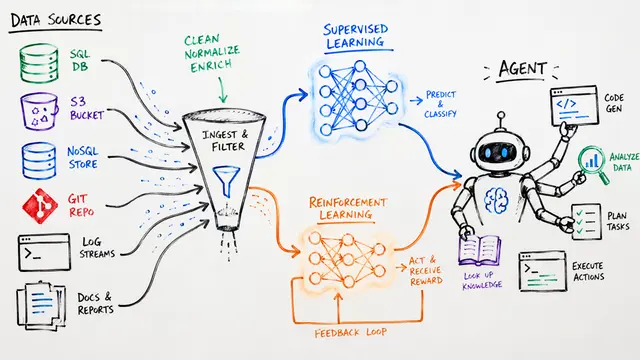
Training language models to be effective knowledge agents has been constrained by benchmarks that don't stress the real complexity of information seeking. The researchers behind KARL decided to change that, building an agent that masters six fundamentally different reasoning challenges using reinforcement learning and a single tool: vector search.
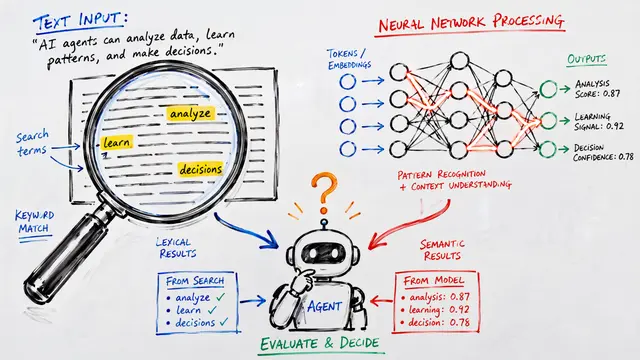
The new benchmark suite exercises behaviors that typical question answering or retrieval tasks miss entirely. Each task lives in a closed corpus where multi-step, evidence-grounded search is required. This structural diversity means an agent can't succeed by pattern matching—it must genuinely retrieve, reason, and synthesize across very different information architectures.
How do you train an agent to handle such variety without overfitting to any single task structure?
The authors built a multi-stage agentic pipeline that synthesizes training data by dynamically exploring the corpus. A question-answer generator creates grounded pairs, a solver agent attempts them repeatedly, and only questions with intermediate pass rates—those that are challenging but solvable—make it through. A quality filter then screens for ambiguity and correctness. This curated signal becomes the foundation for reinforcement learning.
The contrast with supervised fine-tuning is striking. While distillation from expert models boosts performance on training tasks, it fails to generalize. Direct multi-task reinforcement learning across two training benchmarks improves all six, including four never seen during training. The agent learns transferable reasoning strategies, not just dataset patterns.
Test-time compute scaling pushes performance even further. By generating multiple independent rollouts in parallel or using value-guided tree search, KARL matches Claude Opus on the full benchmark—but at 33 percent lower cost per query and 47 percent lower latency. This Pareto dominance across both cost and speed redefines what's possible for open knowledge agents.
KARL proves that systematic synthetic data, large-batch off-policy reinforcement learning, and multi-task training can yield agents that generalize far beyond their training distribution—all with a single search tool. Visit EmergentMind.com to explore the paper in depth and create your own research video.