Federated Attentive Message Passing (FedAMP)
FedAMP introduces a novel federated learning methodology that enables client models to collaborate through adaptive, pairwise attention mechanisms. By leveraging attention-inducing communication between models, FedAMP personalizes learned parameters for each client while maximizing the benefits of inter-client similarity, offering provable convergence and demonstrably superior empirical results on non-IID data distributions compared to established methods like FedAvg and FedProx.Script
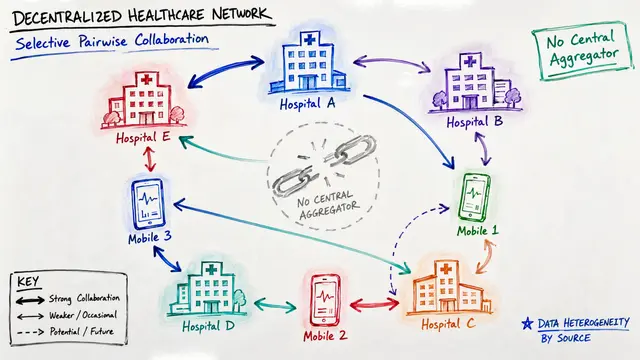
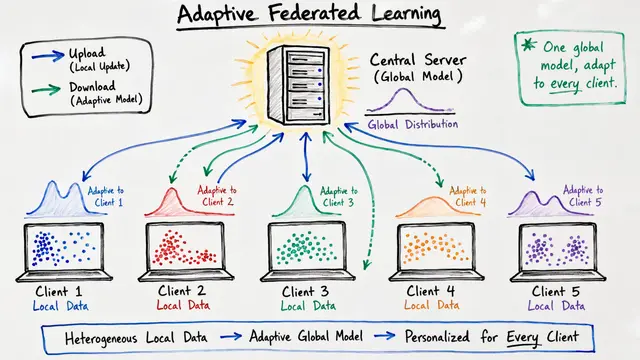
Federated learning promises collaborative machine learning without sharing raw data, but there's a persistent challenge: when each client holds data from a different distribution, traditional averaging methods fail spectacularly. On clustered non-IID data, FedAMP achieves 91% accuracy where FedAvg manages only 79%.
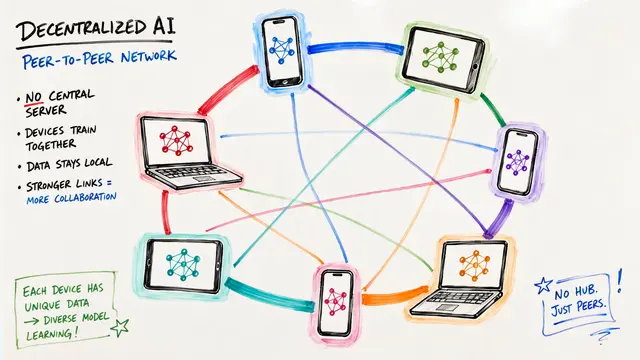
FedAMP alternates between two elegant steps. First, the server computes an attentive aggregate for each client, weighting contributions from similar models heavily and dissimilar ones lightly. Then each client performs a local update, pulled toward its personalized aggregate by a proximal penalty, balancing its own data with learned collaboration.
The attention mechanism adapts automatically to model similarity. When two client models are close in parameter space, the exponential kernel assigns them high attention weight, encouraging strong collaboration. As models diverge, attention drops exponentially, protecting each client from irrelevant or harmful updates.
On EMNIST with 62 clients partitioned into 3 latent clusters, FedAMP's learned attention heatmap reveals striking block structure. Clients within the same data cluster automatically discover each other and form tight collaborative groups, while attention across clusters remains minimal. The algorithm recovers hidden structure with no supervision.
The empirical gains are substantial and consistent. On Fashion MNIST under practical non-IID conditions, FedAMP achieves 91% balanced accuracy compared to 84% for the best competitor and 79% for standard federated averaging. On CIFAR-100, the heuristic extension reaches 53% where FedProx stalls at 37%.
FedAMP's proximal structure confers natural robustness: clients that drop out are simply excluded from aggregation, and noisy or corrupted models are automatically down-weighted by the attention kernel. This principled, provably convergent framework offers a powerful new lens for federated learning on heterogeneous data. Explore more federated learning breakthroughs and create your own videos at EmergentMind.com.