Attention Residuals: Selective Depth-Wise Aggregation for Deep Language Models
This presentation examines Attention Residuals, a novel mechanism that replaces the standard static residual connections in deep neural networks with selective, attention-based aggregation across layers. The work reveals fundamental limitations in how traditional architectures accumulate information through depth, introduces a practical solution that treats layer-wise aggregation as an attention problem, and demonstrates consistent improvements in scaling behavior and reasoning performance across large-scale language models.Script
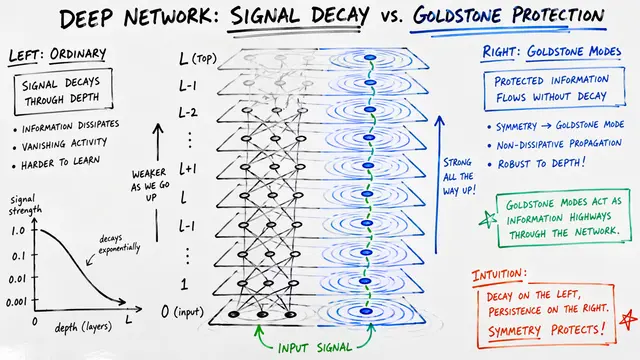
Every deep neural network faces a hidden bottleneck: as signals pass through dozens or hundreds of layers, early representations fade into noise while magnitudes explode. The standard residual connection, despite enabling deep training, treats every layer output identically, accumulating them with fixed weights that cannot adapt to what the model actually needs at each depth.
This creates what the authors call PreNorm dilution. As you stack layers, the contribution from layer 5 becomes vanishingly small by layer 50, buried under dozens of later updates. Meanwhile, the sheer magnitude of the accumulated vector keeps growing linearly with depth. It's a fundamental mismatch: we've learned that attention over time is essential for sequences, yet we still add layers together as if context across depth doesn't matter.
The authors propose a direct solution: treat depth like another sequence and apply attention.
In Attention Residuals, each layer computes softmax weights over all prior outputs, choosing which earlier representations to emphasize. A learned query vector at each depth determines the attention pattern, making aggregation input-dependent and selective. For scalability, Block Attention Residuals groups layers and applies attention only across block summaries, cutting memory and communication costs while preserving nearly all the performance gains.
The results are striking. Attention Residuals consistently outperform standard residuals across model sizes, with sharper scaling laws and healthier gradient flow through depth. On reasoning benchmarks, the gains are even more pronounced: a 7.5 point jump on GPQA-Diamond and improvements across mathematical and coding tasks. Visualizations show that layers learn meaningful skip connections, selectively attending to distant predecessors and the original embedding, rather than just their immediate neighbors.
This work reframes depth itself as a learnable attention problem, not just a static stacking operation. With Block Attention Residuals, the technique is practical at extreme scale, ready for immediate deployment in modern architectures. The improvements in both training dynamics and reasoning capability suggest that deep networks have been underutilizing their layers, and selective aggregation finally lets them access the full depth of their representations. Attention Residuals unifies depth with sequence modeling, revealing that the same principles that transformed how we process time can now transform how we process layers.
Selective depth-wise aggregation turns out to be just as essential as selective attention over tokens—depth is a sequence too, and treating it that way unlocks models that are both deeper and smarter. Visit EmergentMind.com to explore more research and create your own videos.