Personalized Federated Learning via Feature Distribution Adaptation
This presentation explores pFedFDA, a novel approach to personalized federated learning that tackles data heterogeneity through adaptive feature distribution modeling. By leveraging generative classifiers and local-global interpolation, the method achieves remarkable improvements in challenging scenarios involving data scarcity and covariate shifts, delivering over 6% accuracy gains compared to state-of-the-art approaches while maintaining robust generalization to new clients.Script
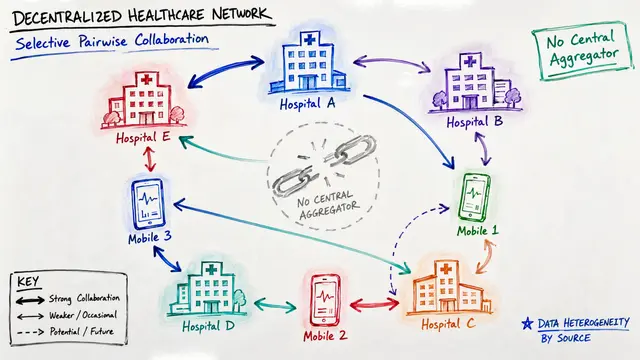
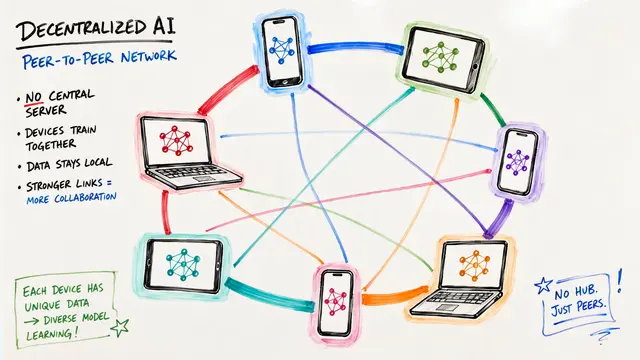
When federated learning meets real-world data, clients don't share the same distributions. Standard approaches like FedAvg struggle with this heterogeneity, leading to what researchers call client drift and disappointing performance.
The authors introduce pFedFDA, which reframes personalization as a feature distribution adaptation problem. Instead of forcing all clients to share identical representations, they train a global feature distribution that each client can locally adapt to their unique data.
The method works through a generative classifier built from Gaussian feature distributions. Clients receive global distribution parameters, train their feature extractors to minimize classification loss, then estimate their local distributions using efficient low-sample techniques and interpolation with the global model.
In experiments across CIFAR and EMNIST datasets, pFedFDA delivered striking results. Under data-scarce conditions with covariate shifts, it achieved accuracy improvements exceeding 6.9 percent compared to the next-best method, and showed robust generalization even to clients with unseen distribution shifts.
Ablation studies revealed that the local-global interpolation method is key to balancing the bias-variance trade-off. A single interpolation coefficient proved cost-effective for most scenarios, though adapting separate coefficients for means and covariances offered additional gains under severe distribution shifts.
By treating personalization as generative distribution adaptation, pFedFDA opens new paths for federated learning in privacy-sensitive domains where data heterogeneity is the norm, not the exception. To explore how this approach reshapes collaborative machine learning and create your own research videos, visit EmergentMind.com.