Cross-Datacenter KVCache: Breaking the RDMA Barrier in LLM Serving
This presentation explores how hybrid-attention models enable practical cross-datacenter disaggregation of large language model serving. It demonstrates that selective offloading of long-context prefill operations, combined with intelligent cache management and bandwidth-aware scheduling, achieves 54% higher throughput while using only commodity Ethernet—fundamentally changing the economics and scalability of heterogeneous LLM deployment.Script
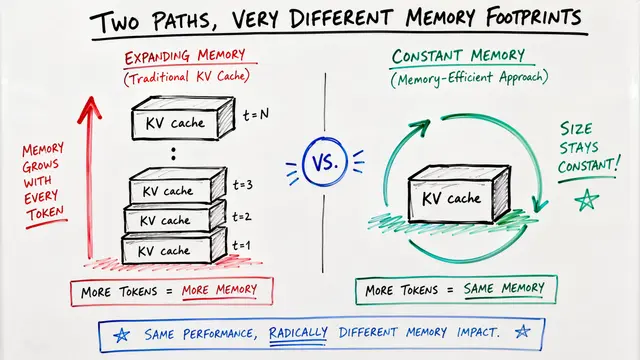
Dense-attention language models flood networks with so much cache data that splitting prefill and decode across datacenters has been impossible without expensive RDMA links. But hybrid-attention models change everything: the authors show that a single one-trillion-parameter model running on 32 H200 GPUs needs only 13 gigabits per second of bandwidth—easily handled by ordinary Ethernet.
The researchers introduce Prefill-as-a-Service, an architecture that routes only long-context requests to remote compute-optimized clusters for prefill, then transfers the compressed cache back to local memory-optimized hardware for decoding. Short requests bypass this entirely and stay local, avoiding unnecessary network hops.
Hybrid-attention models produce two kinds of state: fixed-size recurrent states from linear layers and variable-sized cache from full-attention layers. The system manages these in coordinated pools, enabling fine-grained reuse within clusters and efficient cross-cluster transfer of only the necessary attention cache.
Bandwidth-aware scheduling dynamically adjusts which requests get offloaded by modeling throughput across varying thresholds and link conditions. The system continuously balances prefill and decode capacity, adapting in real time to traffic bursts and cache hit rates—achieving 54% higher throughput and 64% lower time-to-first-token compared to homogeneous baselines.
Dense-attention models generate order-of-magnitude more cache per request, making cross-datacenter disaggregation infeasible at scale. Hybrid architectures fundamentally change the calculus: even at thousands of GPUs, aggregate bandwidth demand remains within modern inter-datacenter network capacity, unlocking independent scaling of compute and memory resources.
This work signals a fundamental shift: next-generation serving will co-evolve heterogeneous hardware, hybrid model architectures, and intelligent cache orchestration into fully elastic infrastructures. The KVCache bottleneck that once confined disaggregation to single datacenters is breaking—and you can explore the full details and create your own video at EmergentMind.com.