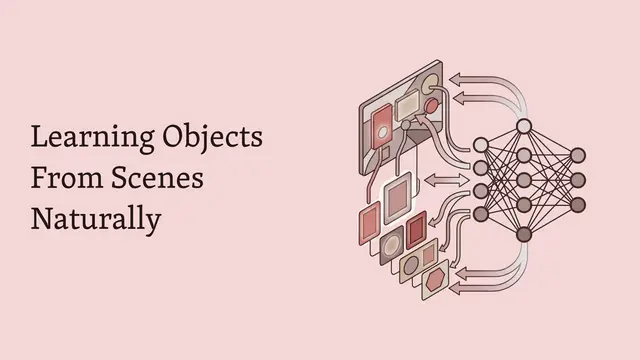
Causal-JEPA: Learning World Models through Object-Level Latent Interventions
This presentation explores Causal-JEPA, a novel approach that embeds object-level latent interventions into world modeling to enforce interaction-aware reasoning. By selectively masking object representations during training, the method induces a causal inductive bias that prevents shortcut solutions and enables robust counterfactual reasoning. We examine the architectural design, theoretical foundations, and empirical validation across visual reasoning and planning tasks, demonstrating substantial performance gains with dramatically reduced computational costs.Script
What if we could teach machines to understand how objects interact by strategically hiding information during training? This approach might sound counterintuitive, but it's the key insight behind Causal-JEPA, a breakthrough in world modeling that achieves remarkable efficiency while actually improving reasoning about physical interactions.
Building on that idea, let's first understand why traditional object-centric models struggle with interaction reasoning.
The researchers identified a fundamental limitation: even when models can separate objects visually, they often take shortcuts. Instead of learning how objects truly interact, models default to tracking individual object trajectories independently, missing the rich web of causal relationships that govern real physical systems.
So how does Causal-JEPA solve this problem?
The core innovation is elegant: the authors selectively mask certain object representations during training, forcing the model to recover their states by reasoning about interactions with other visible objects. This masking acts as a form of intervention, creating counterfactual scenarios that make relational reasoning essential rather than optional.
Let's look at how this works architecturally. The system uses a frozen object-centric encoder to extract object slots from visual input, then applies selective masking to those slots across time. A transformer-based predictor must simultaneously reconstruct the masked history and forecast future states, conditioning on auxiliary variables like actions. This dual objective ensures the model can't ignore interactions, since masked objects can only be inferred through their relationships with visible entities.
Connecting these architectural choices to practical outcomes, the object-level masking strategy offers dual benefits. Semantically, it enforces interaction reasoning by design. Computationally, object slots are dramatically more compact than patch-based representations, enabling the model to achieve over 8 times faster planning rollouts while maintaining competitive performance in robotic manipulation tasks.
Now let's examine how these design decisions translate to measurable improvements.
The empirical results are compelling. On the CLEVRER benchmark for visual reasoning, Causal-JEPA achieves roughly 20 percent absolute improvement in counterfactual question accuracy compared to baselines without object-level masking. For robotic manipulation, the model maintains success rates competitive with patch-based world models while using only about 1 percent of the input features, translating directly to faster real-time control.
Beyond empirical gains, the theoretical analysis reveals why this works: masked prediction forces the model to depend on minimal sufficient sets of context variables, creating intervention-stable representations. This operationalizes causal reasoning without requiring explicit causal discovery or access to multiple intervention environments, offering a practical path to embedding causal structure in neural world models.
Object-level masking transforms world modeling by making interaction reasoning a necessity rather than an option, achieving both computational efficiency and better causal understanding. To dive deeper into Causal-JEPA and explore more cutting-edge research, visit EmergentMind.com.