Causal-JEPA: Learning World Models through Object-Level Latent Interventions
This presentation explores Causal-JEPA, a novel approach to world modeling that embeds object-level latent interventions into the learning process. By selectively masking object representations during training, C-JEPA forces models to reason about interactions between entities rather than relying on shortcuts. The method achieves substantial improvements in visual reasoning tasks and drastically reduces computational requirements for model-based control, all while inducing a principled causal inductive bias without reconstruction objectives.Script
What if we could teach AI systems to understand not just what objects are, but how they truly influence each other? Traditional world models often take shortcuts, ignoring the rich web of interactions that define real dynamics.
Building on that tension, the authors identify a fundamental limitation: while object-centric representations isolate entities effectively, they provide no inherent incentive for the model to reason about how those entities interact. This opens the door to shortcut learning where models predict futures based solely on isolated self-dynamics.
So how does Causal-JEPA address this gap?
The core innovation is deceptively elegant. The researchers apply object-level masking, where specific object slots lose their temporal context and must be reconstructed from the interactions and states of other entities. This structured intervention compels the model to build genuine relational understanding rather than memorizing isolated trajectories.
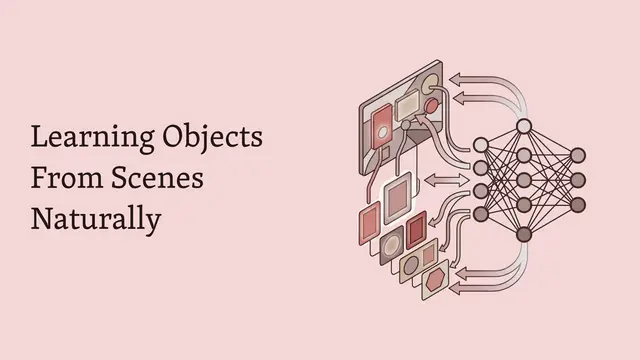
Here we see the full training pipeline in action. Object-centric encoders first extract slot representations from raw visual input. Then, selected slots are masked across time, and a transformer predictor must simultaneously complete the masked history and forecast future states. Auxiliary variables like actions are integrated as separate entity tokens, conditioning predictions on exogenous influences. This joint objective creates a powerful learning signal that enforces interaction-aware reasoning.
Transitioning to architectural efficiency, the contrast is striking. While patch-based world models process thousands of tokens, C-JEPA operates on a small number of object slots, using only 1.02% of the typical latent input features. This compression yields over 8-fold speedups in planning rollouts without sacrificing control performance, making real-time model predictive control genuinely practical.
The empirical results validate the approach compellingly. On the CLEVRER visual reasoning benchmark, the researchers achieve roughly 20% absolute gains in counterfactual question accuracy compared to baseline architectures without object-level masking. For robotic manipulation, C-JEPA maintains strong performance while drastically reducing computational overhead, and ablations confirm that performance improves monotonically with masking ratio before eventually plateauing.
Theoretically, this approach is grounded in principles of causal reasoning. The masking regime creates intervention-like training scenarios where optimal predictors must identify minimal sufficient context for each masked entity. This operationally embeds causal structure without requiring explicit causal graph estimation or intervention across multiple environments, connecting naturally to frameworks like invariant risk minimization.
Of course, important limitations remain. The method inherits dependencies from its object-centric encoder, and the authors note they lack validation against datasets with explicit causal annotations. Future work could explore end-to-end training of encoders and predictors, integration with foundation models, and scaling to more complex open-ended environments with intricate interaction structures.
Causal-JEPA demonstrates that structured masking of object-level latents can instill genuine interaction reasoning in world models, bridging efficiency and interpretability with principled causal induction. To dive deeper into this work and explore related advances in world modeling, visit EmergentMind.com.