- The paper posits loop engineering as an external layer that replaces step-by-step prompting with reusable, auditable loop artifacts.
- It details a five-level verification ladder and corpus analysis to highlight strengths in autonomous checks and limitations in full automation.
- The study introduces design principles, anti-patterns, and the sandeco-loop pipeline to standardize and secure LLM-driven coding agent systems.
Loop Engineering as a Distinct Layer in Agentic Automation
Introduction and Motivation
The paper "Stop Hand-Holding Your Coding Agent: Engineering the Loops that Replace Step-by-Step Prompting" (2607.00038) formalizes the emerging discipline of "loop engineering" as an explicit layer in the progression of LLM-driven coding agent systems. Instead of composing individual prompts for each sub-task, the paradigm shift advocated is to specify reusable, external loop artifacts that automate when and how an agent should be triggered, what constitutes successful completion, and when automated control should return to the human operator. This framework addresses growing practitioner consensus that the critical challenge is no longer prompt authoring but the design of operational scaffolding—loops—that orchestrate agent activity, verification, and state persistence in an auditable, decomposable manner.
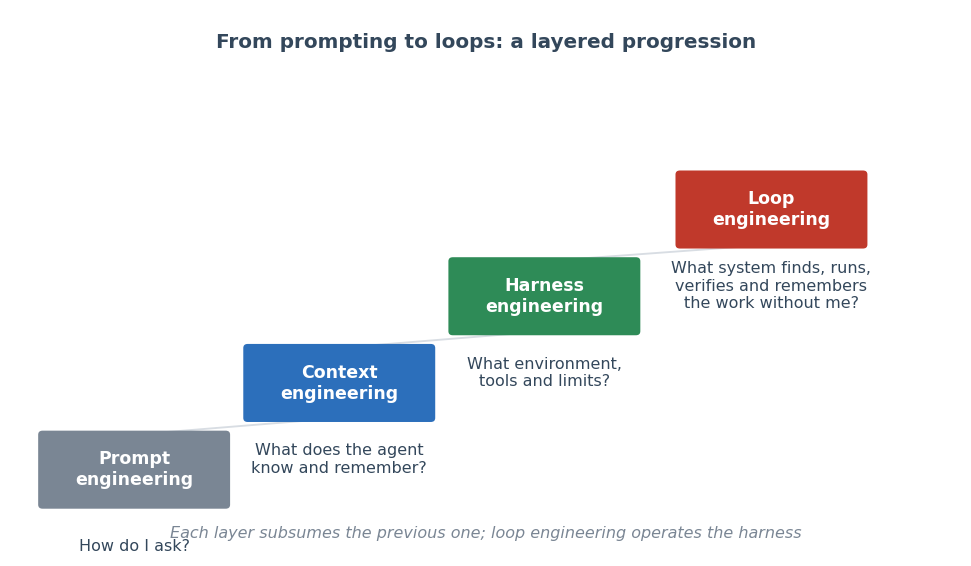
Figure 1: Loop engineering as a new layer in the progression from prompt to context to harness to loop. Each layer subsumes the previous one; the loop specification operates the harness.
Definition, Scope, and Anatomy of Loop Specifications
The paper distinguishes loop specifications from (i) ordinary programming control flow and (ii) the internal agent cycles encoded in agent harnesses (e.g., the perceive-act-observe loop). A loop specification is defined as a bounded, reusable, external artifact consisting of:
- Trigger (manual, scheduled, or event-driven)
- Goal definition (ideally verifiable, sometimes rubric-based)
- Execution using proven skills
- Verification step (using a structured ladder of rigor)
- Named stopping rule/terminal state
- Durable, externalized memory
This decomposition is not merely descriptive; it is operationalized in a shareable artifact, meant to be handed to an agent harness and individually versioned and maintained.
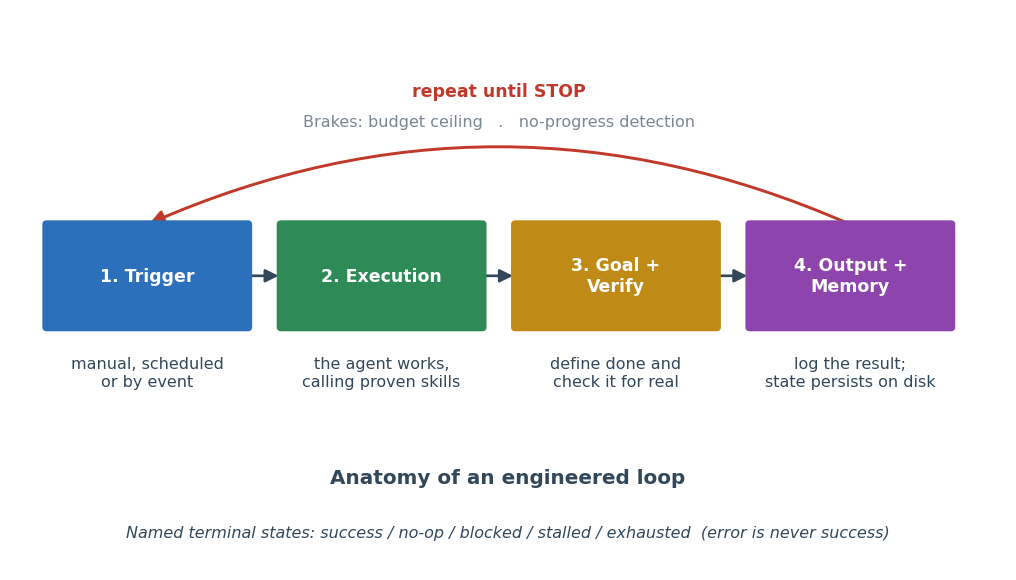
Figure 2: The anatomy of a loop specification, showing its essential components including trigger, skills, goal, verification, stopping states, and persistent memory.
The core claim is that the locus of technical difficulty—and scientific value—shifts to verification: designing checks that robustly decide when work is genuinely complete. Loop engineering is distinctly justified only when outcome-dependent feedback modifies the next agent action, conferring iteration and adaptability not achievable with scheduled one-shot prompts.
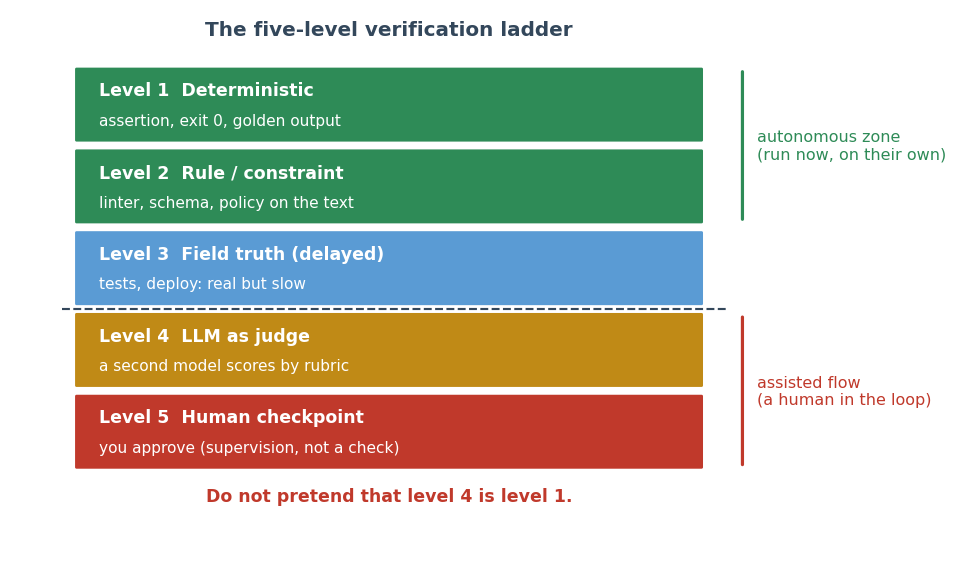
Taxonomy and Verification: The Five-Level Ladder
The taxonomy of loop design comprises five axes: trigger type, goal type (verifiable or judgment-based), verification rigor, execution architecture, and terminal states. The central innovation is the explicit verification ladder:
The ladder makes it explicit that only levels 1-3 offer strong, autonomous verification. Levels 4 and 5 exclusively constitute "assisted flow." The recommendation is to maximize use of levels 1/2, minimize reliance on level-4 model-judge pathways, and always structurally decouple generator and verifier—directly addressing the problem of spontaneous reward hacking demonstrated in recent LLM literature [pan2024spontaneous].
Empirical Corpus Analysis: Insights from Fifty Loop Specifications
A hand-coded analysis of 50 loop specifications from the public Loop Library provides quantitative insight into actual practitioner design choices.
- Verification: 50% employ deterministic (level 1) checks; 70% operate in the autonomous zone (levels 1-2). Only 22% rely primarily on model judges (level 4), and just 2% (1/50) depend on manual human oversight.
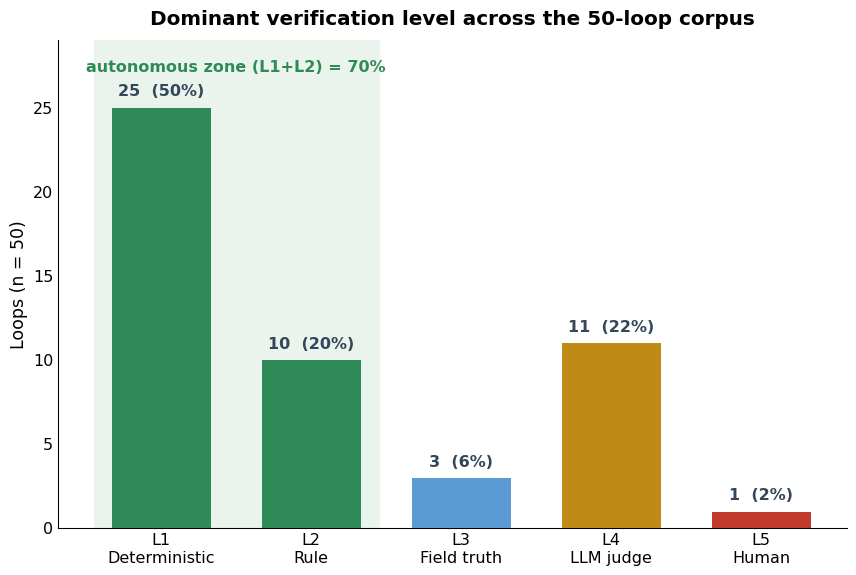
Figure 4: Distribution of dominant verification level across the fifty loops, indicating prevalence of autonomous, deterministic checks.
- Trigger and Architecture: 78% use manual triggers; only 12% are schedule-based and 10% event-driven. Similarly, 78% employ solo agents, while only 18% utilize maker-checker architectures, and 4% use manager-helper structures.
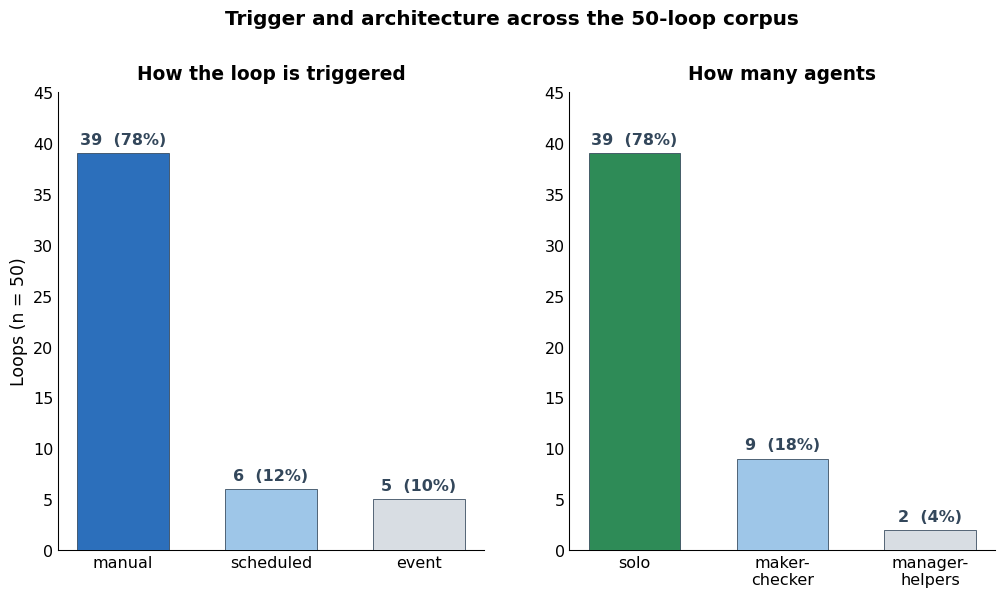
Figure 5: Trigger types (left) and agent architectures (right) across the fifty loops. Manual and solo designs predominate, with automated and multi-agent variants being rarer.
- Pattern families: Loops rarely instantiate only one pattern; most compose at least two, with goal-definition and trust-in-result patterns dominating, while persistent memory/state is least developed (32%).
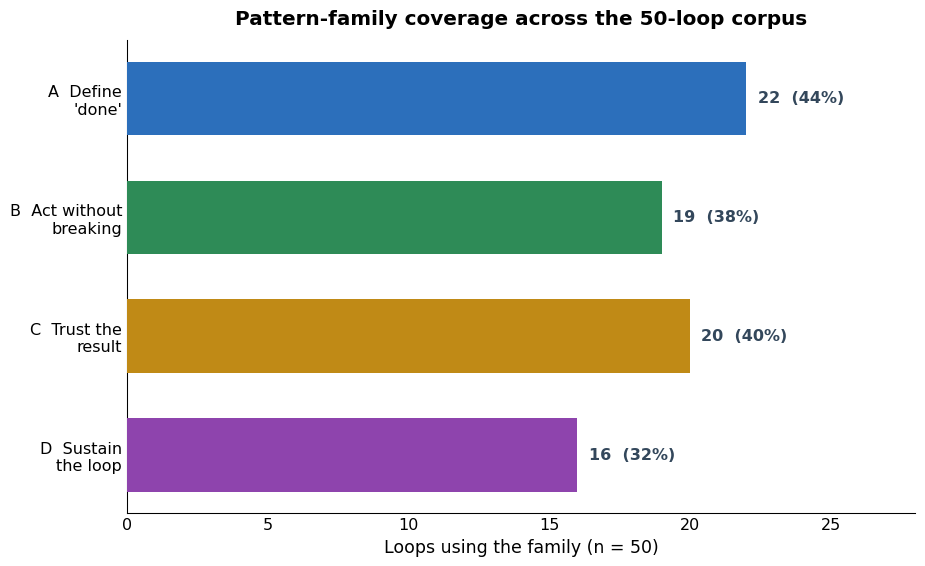
Figure 6: Coverage of four loop pattern families, with memory-and-state underrepresented.
- Maturity mismatch: Verification, goal definition, and named terminal states are mature (70–74%), but automated triggers, skill reuse, and persistent memory development lag (20–32%).
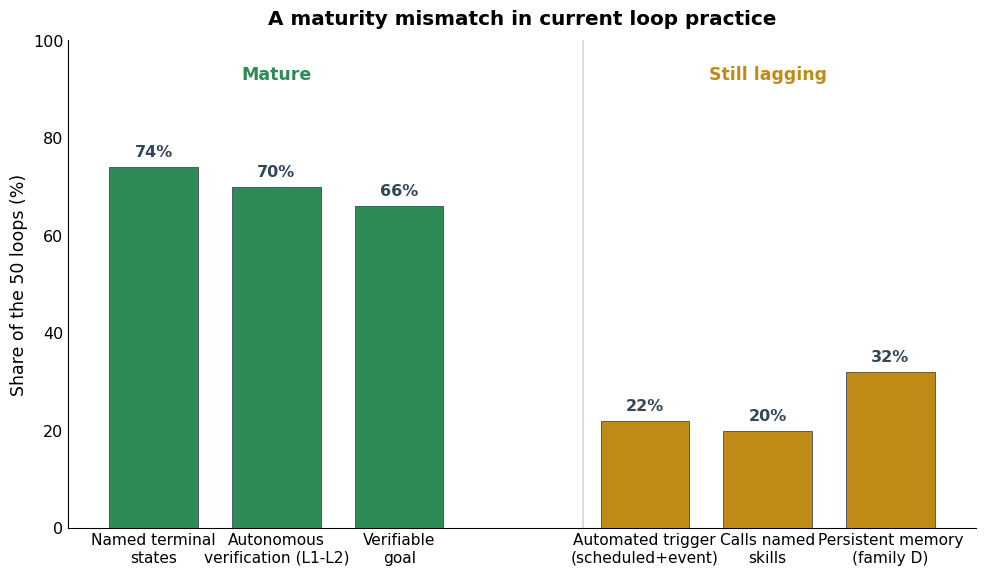
Figure 7: Loop practice is mature in verification, goal definition, and stopping, but less so in automation, skills, and memory persistence.
These corpus-level findings validate the strong emphasis on autonomous verification and explicit stopping, but also reveal that complete automation (i.e., removing the human entirely from initiation, skill provision, and durable state management) remains underdeveloped in practical loop deployments.
Design Principles and Anti-Patterns
Four principle families are established, directly addressing pathologies evidenced both in practitioner deployments and recent literature:
- A: "Define done before you start"—Goal-anchored, frozen, and evidence-based yardsticks suppress drift.
- B: Controlled action scope—Change one variable per iteration, guided by interpretable effects on verification checks.
- C: Trust through role separation—Strict maker-checker separation precludes self-approval pathologies. LLM-as-judge and multi-agent architectures are to be hardened by independent review, never self-score, in accordance with empirical findings on reward hacking and debate drift in LLMs [pan2024spontaneous, becker2025drift].
- D: Sustainable memory—Durable, curated memory is necessary but insufficient; ungoverned accumulation degrades agent quality [zhang2025ace].
Five anti-patterns, corresponding to recurrent reliability and cost failures, are codified: "while-true around a stranger," self-approval loops (reward hacking), specification gaming, misrepresentation of verification level, and unattended loops with runaway cost or safety exposure.
The paper proposes a qualitative evaluative checklist and emphasizes cost per accepted change as the core empirical metric for future studies. Contrary to mere token/budget burn, a healthy loop maintains a low and stable cost per approved outcome.
Authoring Skills for Loop Specifications
To operationalize loop engineering principles, the "sandeco-loop" authoring skill is introduced. This pipeline implements triage (to identify genuine iterative feedback tasks), a structured taxonomy-based interview, and an anti-pattern hardening pass. The output is a single, structured specification document that captures all aspects of the loop, ready for versioning and deployment within a harness.
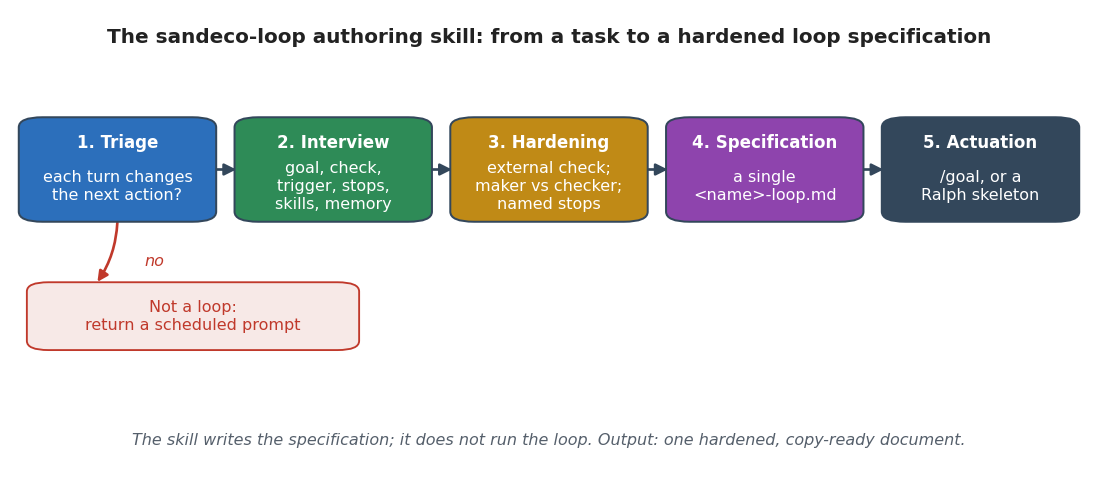
Figure 8: sandeco-loop authoring pipeline, mapping tasks to loop specification documents with in-built design validation and hardening.
This tool represents a concrete attempt to standardize and scaffold practitioner application of the design principles, though the paper appropriately refrains from claiming empirical improvement pending further field evaluation.
Implications, Limitations, and Future Directions
The formal conceptualization and public corpus coding substantiate loop engineering as a technico-practical discipline that is distinct from prompt or context engineering. The principal contradictory claim is that loop engineering does not obsolesce prompt engineering but extends it, establishing a compositional, modular scaffolding for agent autonomy.
Practically, adoption implications include:
- Robust loop design enables higher degrees of unattended operation but requires evidence-based verification, separation-of-roles, and externalized, governable state.
- Full automation remains constrained by underdeveloped pipelines for skill curation, event-based triggering, and systematized persistence.
- Security and cost controls are prerequisites for unattended operation—resources must be sandboxed, budgets capped, and all irreversibly destructive actions human-gated.
Theoretically, this work foreshadows convergence between loop engineering and research in agentic RL, agentic context engineering [zhang2025ace], and self-evolving system safety [gao2025selfevolving]. Formalizing loops as first-class, configurable system components sets the stage for empirically measuring and optimizing long-horizon control, resource utilization, and reliability in LLM-based agentic automation.
Key immediate research directions include:
- Empirical evaluation across tasks and harnesses, benchmarking cost per accepted change and loop robustness.
- Tool-chain standardization: exposing loop elements as first-class harness configuration.
- Safe auto-evolution: governance protocols for memory curation and introspective loop adaptation.
Conclusion
"Stop Hand-Holding Your Coding Agent" (2607.00038) positions loop engineering as a necessary advancement in LLM-driven agentic systems: one that formalizes external, reusable workflow and verification structure, rather than relying solely on stepwise human prompting or unsupervised agent cycles. The paper's anatomy, taxonomy, corpus analysis, and codified design guidance provide both practitioners and researchers with a foundation for reproducibility, auditability, and scale in agent deployment. By emphasizing verification rigor, role separation, and externalized state, the work establishes design standards that meaningfully address known pathologies in autonomous agent behavior, while demarcating clear future work in automation, safety, and empirical validation.