- The paper shows that verbal confidence primarily signals a model's commitment (commit/abstain) rather than being an accurate estimate of answer correctness.
- It compares multiple confidence measures, revealing that calibrated log-probabilities align more closely with correctness while verbal signals reflect behavioral readiness.
- Activation steering and residualization analyses confirm a dissociation between internal commitment states and truth evaluation in both reasoning and non-reasoning models.
Verbal Confidence in LLMs: Behavioural Commitment Over Correctness
Experimental Paradigm and Motivations
The paper investigates whether verbal confidence reports in LLMs should be interpreted primarily as estimates of answer correctness or as signals reflecting a model's commitment to its own answer. Drawing inspiration from neuroscience paradigms involving post-decision opt-out behaviour in rodents and primates, a two-phase abstention task is implemented: first, the model answers a question and reports its confidence; subsequently, the model chooses whether to commit to its answer or abstain ("I don't know"). This structure isolates the confidence signal produced independently of the downstream commitment decision, enabling direct analysis of whether confidence reports predict answer correctness (truth) or subsequent commitment behaviour more effectively.
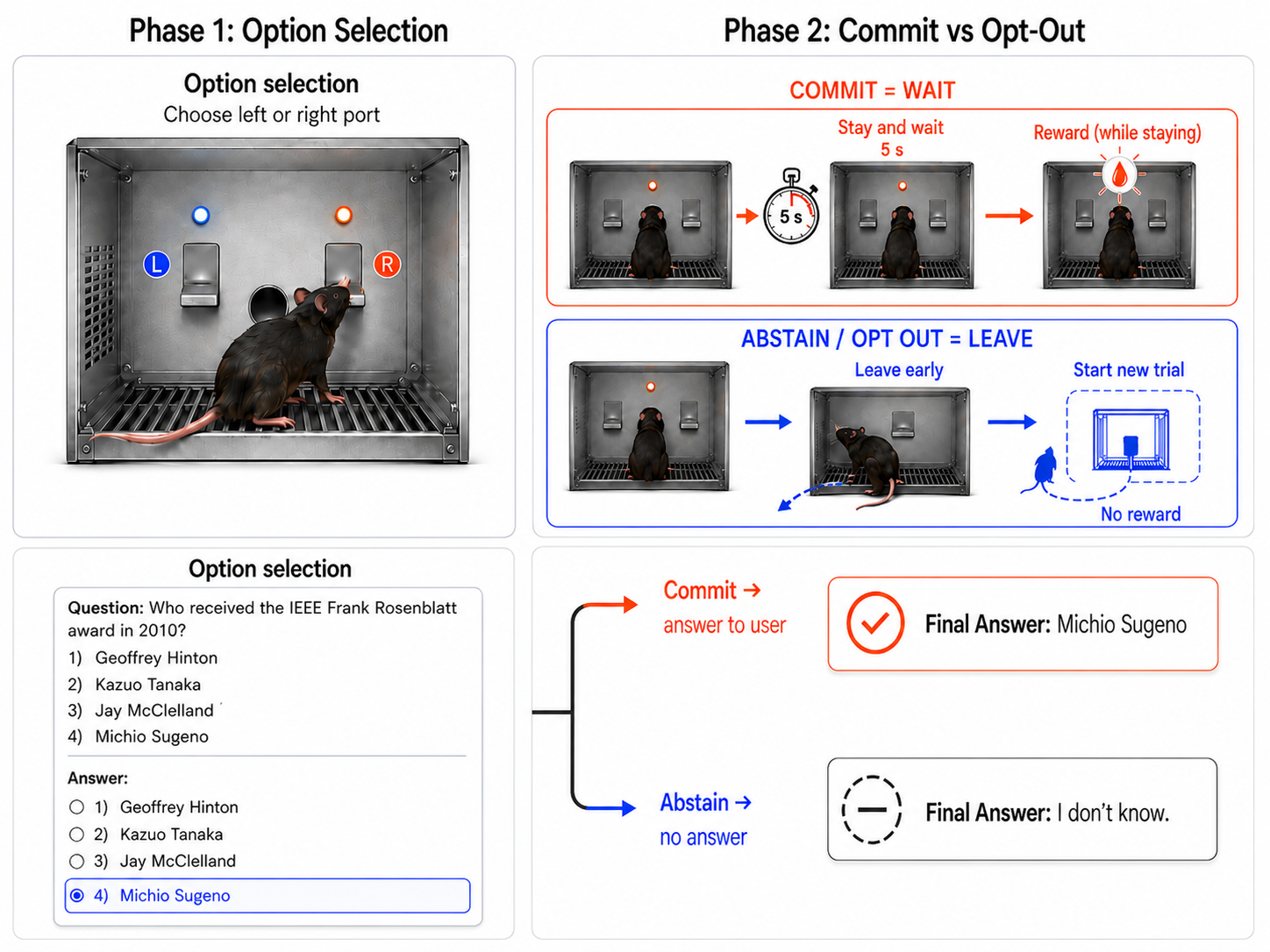
Figure 1: Two-phase abstention paradigm for LLMs, inspired by post-decision confidence studies in animals; Phase~1 produces answer and confidence, Phase~2 elicits binary commit/abstain.
Comparative Evaluation of Confidence Signals
Three confidence signals are analyzed: class-based verbal confidence (Class-VC), numeric verbal confidence (Num-VC), and calibrated log-probability (Cal-LP). Class-VC and Num-VC are explicit, user-facing measures, while Cal-LP is derived from token-level probabilities calibrated through temperature scaling. The study spans four non-reasoning models (Gemma~3 27B, Gemma~4 31B, GPT-4o, Qwen~3 235B), as well as four reasoning models across diverse benchmarks, including MCQ and freeform expert-level tasks.
Empirically, Cal-LP exhibits superior correctness discrimination (AUROC 0.62–0.80), while verbal signals are comparatively weaker. However, the central finding is a robust dissociation: verbal confidence more strongly predicts the model’s later commit/abstain decision than it predicts objective correctness, whereas Cal-LP’s ability to predict abstention is tightly coupled to correctness discrimination.
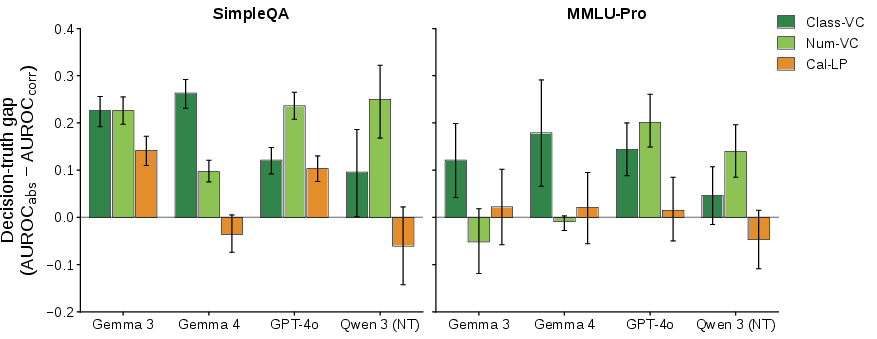
Figure 2: Decision-truth gap: verbal confidence signals display systematically stronger prediction of commitment behaviour than answer correctness; Cal-LP’s gap is negligible or negative.
Structural and Variance Analyses
Joint logistic regression and variance partitioning reveal that verbal signals carry dominant unique variance for abstention, while Cal-LP carries dominant unique variance for correctness. ANOVA-based decomposition using partial η2 demonstrates that verbal confidence's variance is organized primarily by the future commit/abstain decision, not by correctness (e.g., Class-VC: decision η2 up to 0.48 vs correctness η2 ≤ 0.05). By contrast, Cal-LP shows much stronger correctness-related structure and more variable decision alignment.
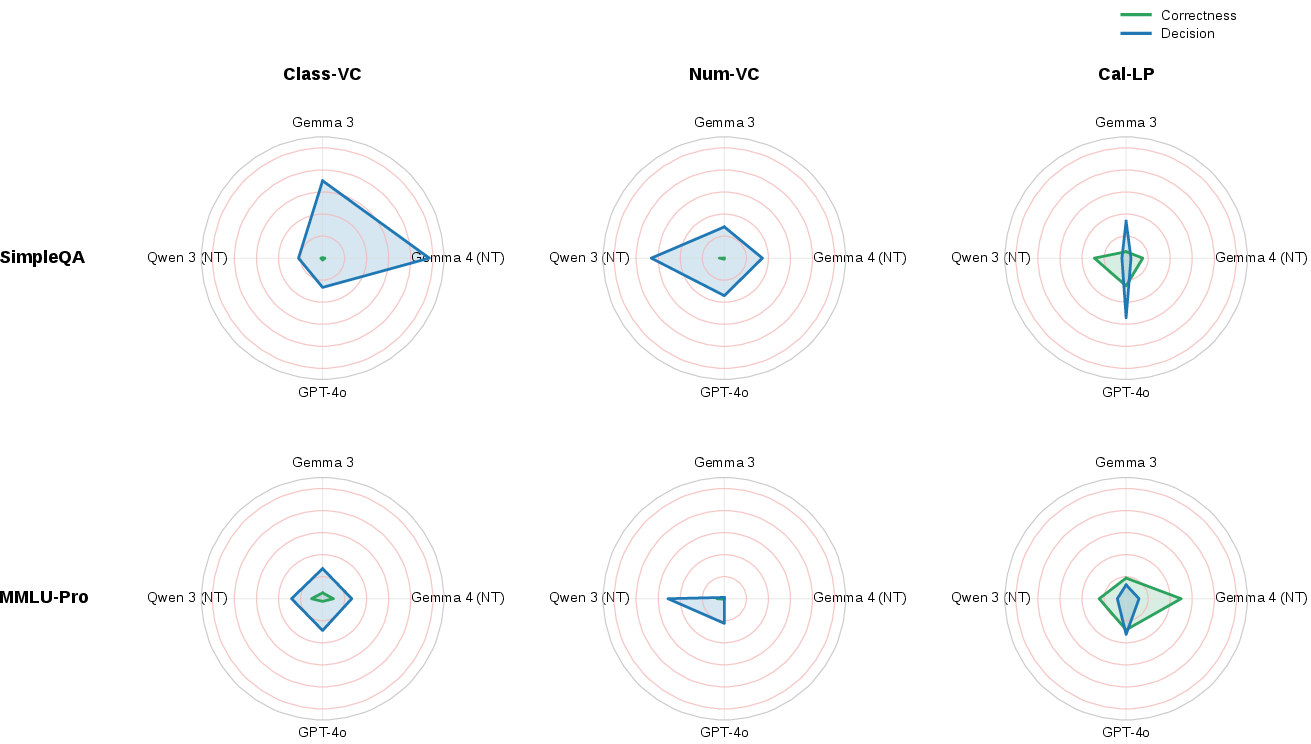
Figure 3: Radar plots of partial η2 indicate verbal confidence is dominated by behavioural commitment, Cal-LP retains substantial correctness structure.
Residualization: Dissociating Truth and Behaviour in Confidence
To differentiate whether decision-aligned verbal confidence merely reflects thresholded truth signals or contains unique behavioural information, reciprocal residualization is performed. After removing the component of verbal confidence linearly explained by Cal-LP (“answer-evidence proxy”), the residual verbal confidence remains highly predictive of the later commit/abstain decision, while its alignment to correctness collapses to chance or below.
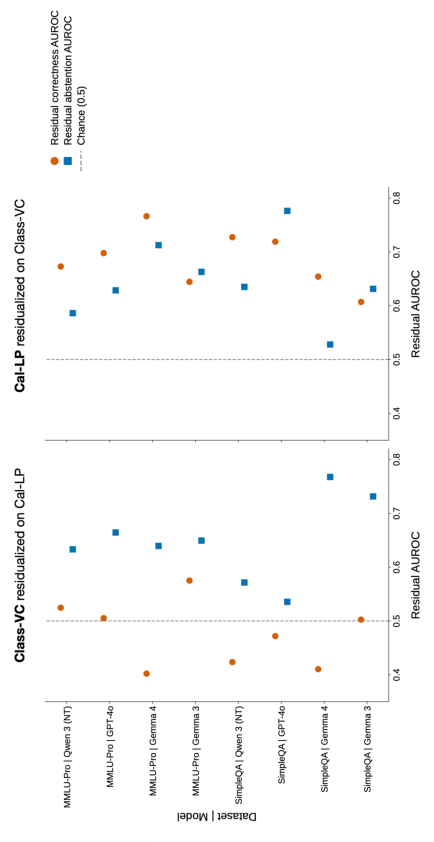
Figure 4: Residual verbal confidence retains strong abstention-predictive power after removal of Cal-LP component, while correctness discrimination vanishes; Cal-LP residuals retain coupled discrimination.
This dissociation matches the generative Account~2 in Figure~9: verbal confidence contains both truth and decision components, with the latter dominating behavioural alignment.
Generalization Across Reasoning Models
The decision–truth dissociation replicates robustly across four reasoning models on four benchmarks. Verbal confidence shows a positive decision–truth gap in 15/16 reasoning-model cells (median AUROC gap +0.16); Cal-LP’s gap is again negligible. ANOVA confirms the same profile as non-reasoning models: decision-aligned variance in verbal confidence dominates, correctness-aligned variance is consistently smaller.
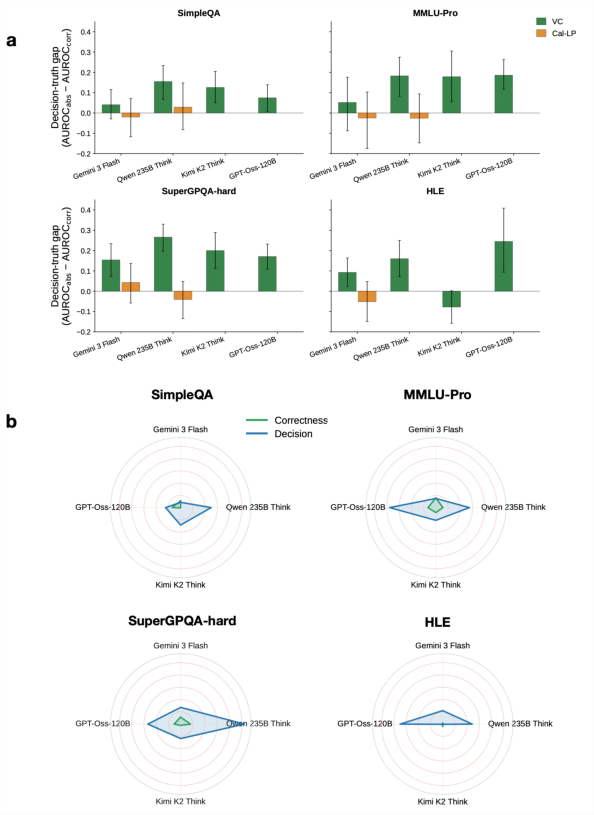
Figure 5: Decision–truth gap and variance decomposition generalizes to diverse reasoning models and datasets.
Scaling Behavioural Versus Truth Prediction
Across 46 verbal confidence cells, abstention AUROC consistently exceeds correctness AUROC by a substantial margin (mean gap +0.16). The scaling pattern for Cal-LP is qualitatively different: its abstention AUROC tracks correctness AUROC closely (slope β≈0.91), fitting the y=x reference line; verbal confidence scales more steeply, further highlighting its behavioural dominance.
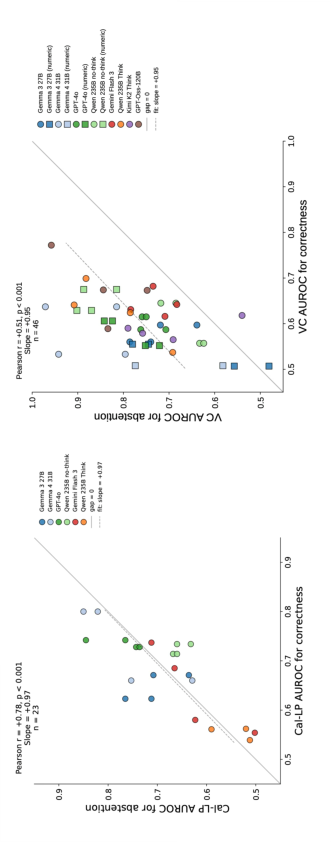
Figure 6: Cal-LP abstention prediction scales tightly with correctness; verbal confidence systematically exceeds this scaling, indicating excess behaviour-aligned signal.
Mechanistic Analyses: Internal Representation and Causal Control
Activation-based analysis in Gemma~4 31B and Gemma~3 27B demonstrates that the post-answer (PA) internal state encodes a near-categorical commit/abstain signal before the abstention prompt is presented. Linear probes predict abstention with AUROC up to 0.94 (Gemma~4), exceeding behavioural baselines, while correctness prediction plateaus at AUROC ≈0.66. The commitment and correctness probe directions are nearly orthogonal in activation space, and the distribution of decision-probe projection is strongly bimodal, aligning closely with commit/abstain behaviour.
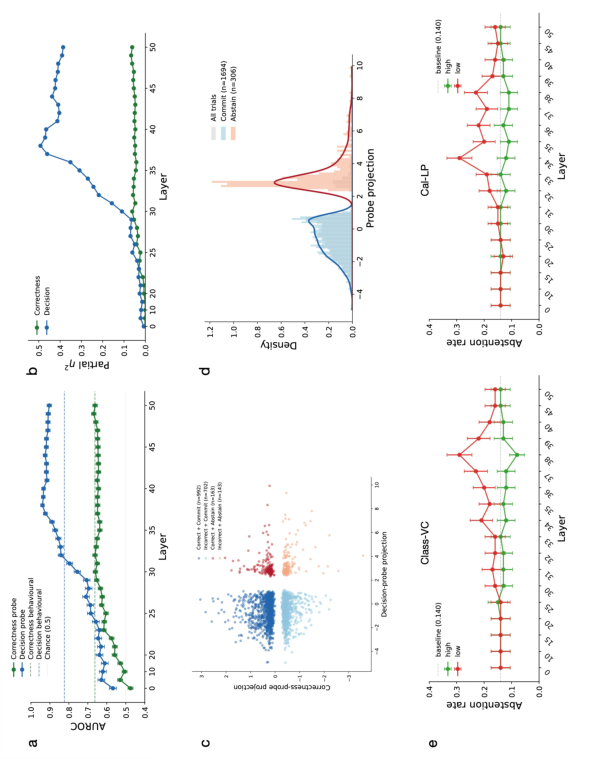
Figure 7: Peak layer linear probes reveal sharp dissociation: strong activation-based prediction for decision, weak for correctness; projections show orthogonality and bimodality.
Activation steering along the verbal-confidence-specific orthogonal direction causally shifts subsequent abstention, confirming functional operativity of commitment-aligned internal states.
Additional Characterizations and Controls
Verbal confidence distributions (both class-based and numeric) further illustrate the behaviour-aligned pattern, with commit/abstain structure dominating mean confidence profiles, and robustness analyses show these effects persist under altered abstention prompts, question formats, and reasoning traces.
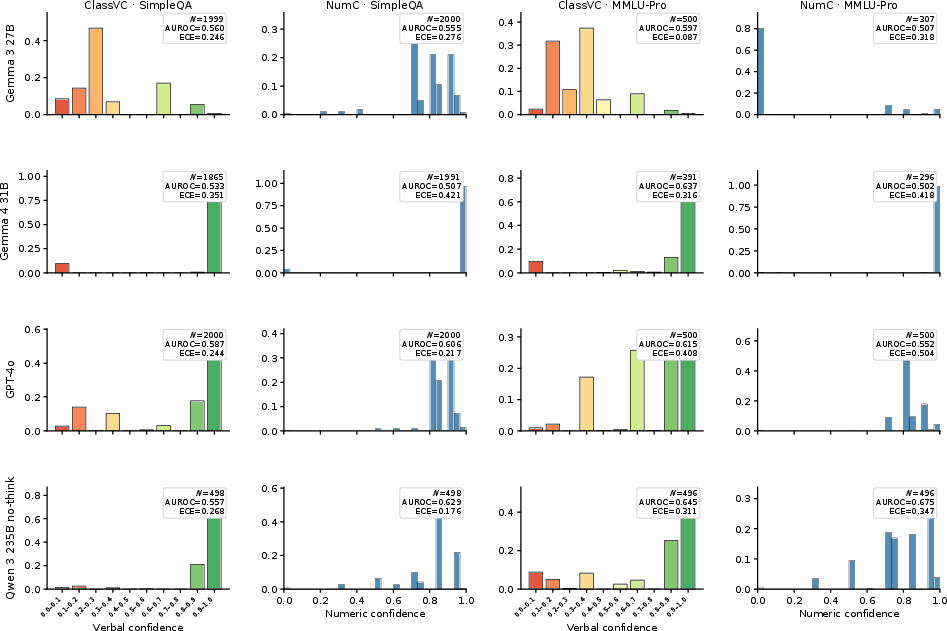
Figure 8: Verbal confidence distributions and metrics in non-reasoning models demonstrate dominant behaviour alignment across formats and benchmarks.
Theoretical schematic (Figure~9) formalizes two generative accounts, with empirical data supporting the truth-plus-decision signal (Account~2), validated by residualization analysis.
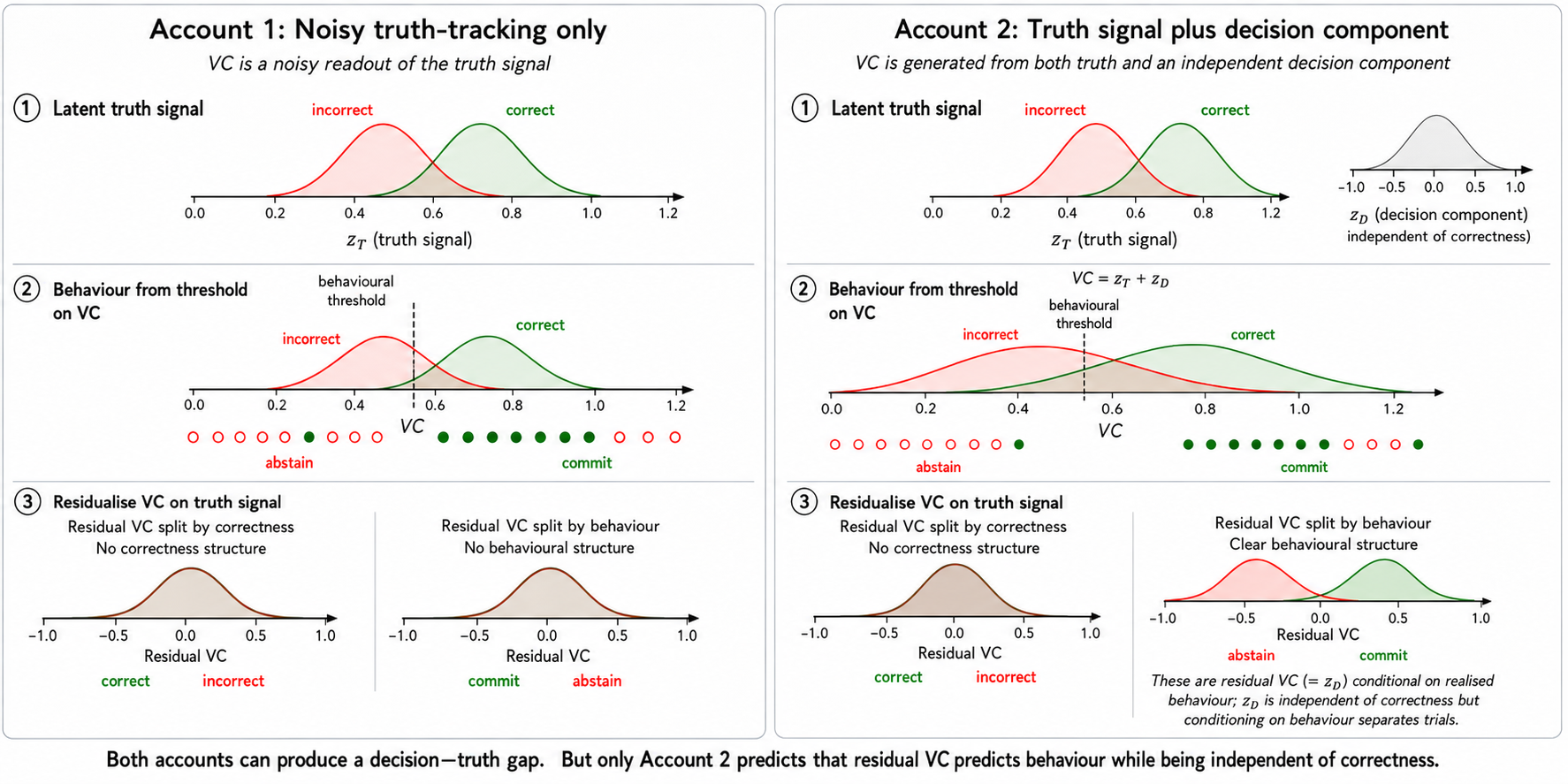
Figure 9: Schematic contrasting pure truth and truth+decision generative accounts; residual alignment differentiates.
Mean confidence in (correctness × decision) quadrants illustrates the predominant blockwise, decision-aligned pattern, distinguishing behaviour-facing from truth-facing signals.
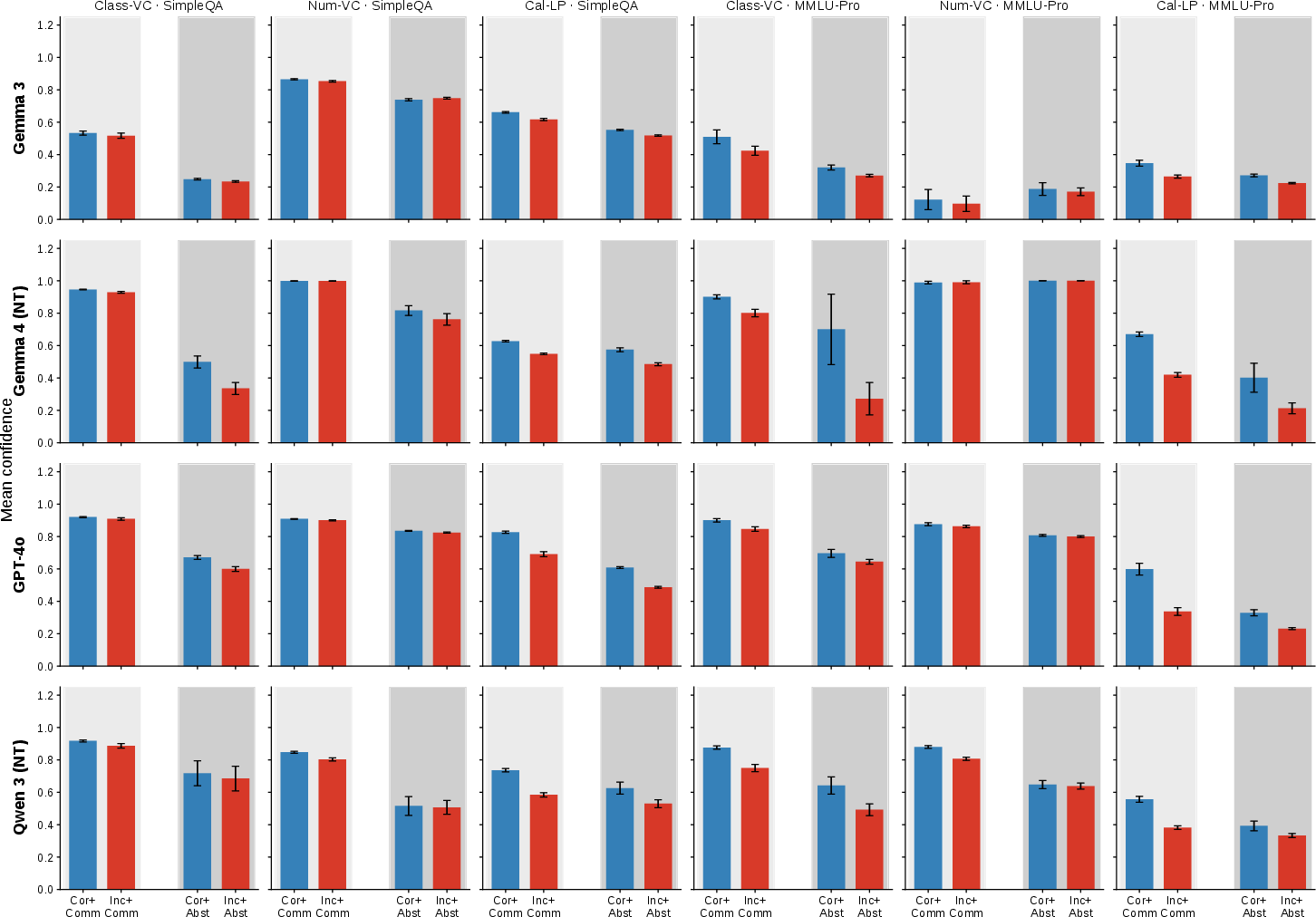
Figure 10: Mean confidence bar profiles across quadrants emphasize step-pattern for verbal confidence and mixed structure for Cal-LP.
Implications and Directions
These results have direct consequences for uncertainty communication in LLMs. Verbal confidence, currently widely used as a default black-box reliability signal, is not a faithful estimate of correctness: it is better understood as a behaviour-facing readout of internal commit-readiness. Cal-LP-derived signals are answer-evidence-aligned, retaining proportional scaling between correctness and abstention prediction. In reasoning models, the single-token log-probability calibration becomes less reliable due to distributed uncertainty, reinforcing the importance of characterizing sequence-level confidence measures. Mechanistic results indicate the possibility of decoupling confidence signal organization from correctness anchoring via targeted intervention in internal activation space.
Conclusion
The paper establishes that in current LLMs, verbal confidence reports are preferentially organized around the model's readiness to commit to an answer rather than the answer's objective correctness. Calibrated log-probabilities, by contrast, are more closely coupled to answer evidence. This challenges standard interpretation of verbal confidence as a correctness proxy, highlighting both theoretical and practical implications: improvements in uncertainty communication will require not only training on surface reports, but also the anchoring of internal, behaviourally operative representations to correctness. These results motivate research into training objectives targeting internal commitment states, development of robust sequence-level uncertainty measures for reasoning models, and mechanistic interventions to improve alignment of confidence and truth in future LLMs.
["Reported Confidence in LLMs Tracks Commitment More Than Correctness" (2606.29490)]