Evolution Fine-Tuning: Learning to Discover Across 371 Optimization Tasks
Abstract: Would experience designing faster GPU kernels also help close in on a long-standing open mathematical conjecture? LLMs integrated into evolutionary search have recently produced state-of-the-art solutions on optimization tasks, including open mathematical conjectures, GPU kernel design, scientific law discovery, and combinatorial puzzles. To achieve this, prior work applied search scaffolds to one target task at a time, so every new problem is approached from scratch and the experience accumulated during search is discarded once the model finishes its attempt. This leaves the capability of iteratively evolving a solution (e.g., knowing which part to mutate and how, deciding when to backtrack) entirely in the scaffold rather than in the model itself. Whether the model itself could acquire this capability and reuse it across different tasks has been largely unexamined. To address this, we introduce Evolution Fine-Tuning (EFT), a mid-training paradigm that teaches LLMs to evolve solutions across tasks by converting evolutionary search trajectories into supervision. We construct Finch Collection, a 156K-trajectory dataset spanning 10 domains and 371 optimization tasks, and fine-tune open-source LLMs from 2B to 9B parameters. Empirically, EFT confers cross-task generalization: across 22 held-out tasks, our models surpass their base counterparts by 10.22% on average. Furthermore, when paired with test-time RL, our model matches state-of-the-art performance on two circle-packing tasks and outperforms its base-model counterpart on the Erdős minimum-overlap problem. EFT thus serves as a "practice phase" for general-purpose discovery agents that do not solve new problems from scratch.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper asks a simple question: Can we teach an AI not just to solve problems, but to learn how to steadily improve its own answers, the way people do when they practice? The authors show a way to do this called Evolution Fine-Tuning (EFT). It trains a LLM using “practice runs” from many different tough problems so the model learns how to make smart, step‑by‑step improvements on new tasks.
The main goal and questions
The researchers focus on optimization problems—challenges where you can score how good a solution is, but there’s no quick formula to find the best one. Examples include:
- Math puzzles (like the Erdős minimum overlap problem)
- Packing shapes tightly (circle packing)
- Speeding up computer code (GPU kernels)
- Competitive programming puzzles
- Finding scientific equations from data (symbolic regression)
Their big questions are:
- Can a model learn the skill of “evolving” solutions—trying something, checking the score, and making better changes next time—so it doesn’t have to start from zero on every new problem?
- If we train on many “evolution journeys” from lots of tasks, will the model reuse those improvement strategies on new tasks?
- Does this training help smaller, open-source models perform more like much bigger, proprietary ones?
How they did it (in everyday terms)
Think of a video game where you keep trying levels, get a score, and tweak your approach to do better next time. Now imagine saving every attempt: what you tried, the feedback you got, and how you changed your strategy. EFT turns those saved playthroughs into lessons for the AI.
Here’s the approach:
- Collect many problems and “practice runs”
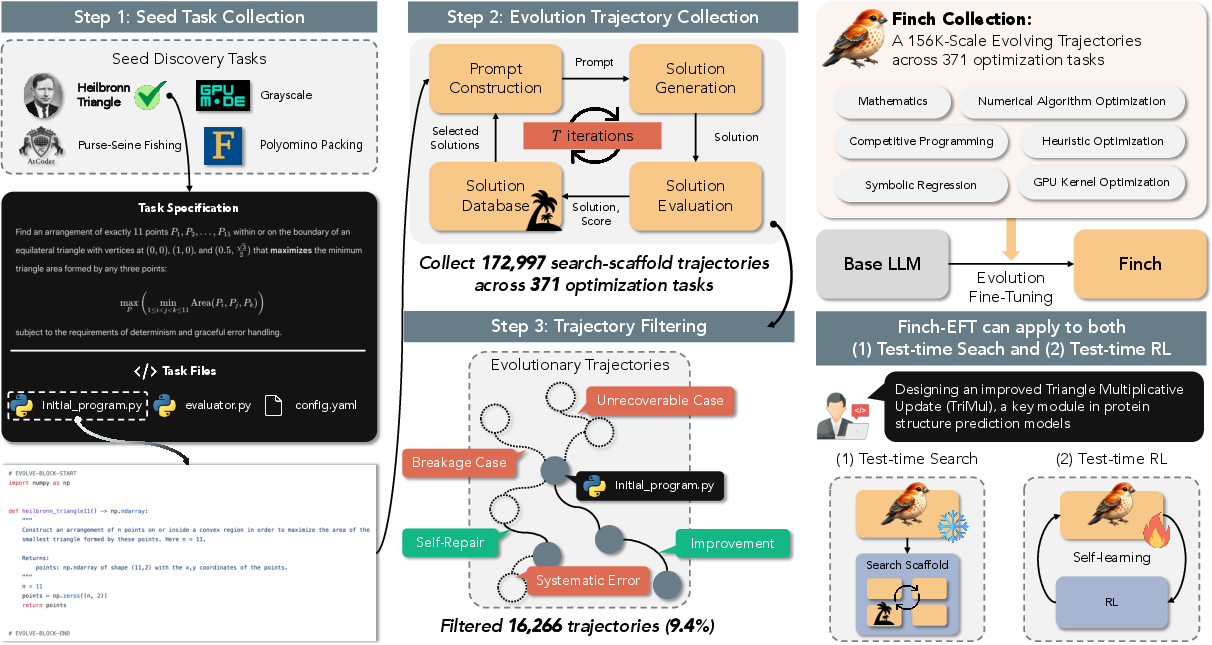
- The team gathered 371 different optimization tasks across 10 areas.
- They ran a search process (called an evolutionary scaffold) that works like a coach: pick a good past attempt (“parent”), ask the AI to propose a small change (“mutation”), test it, keep the better ones, and repeat.
- A very strong “teacher” model (a large Qwen model) was used to generate these candidate changes so the practice runs would be high quality.
- Turn practice runs into training data
- Each run records: the task, the parent solution, feedback/scores, and the improved child solution.
- They filtered out broken or unhelpful runs (like crashes or timeouts), leaving about 156,000 clean “trajectories.”
- Train smaller, open-source models to imitate improvement steps
- The input: the task, the parent solution, and the feedback.
- The target: the improved child solution.
- This teaches the model, “Given what you tried and the feedback, propose a better next step.”
- Teach the model to tell good ideas from bad ones
- Beyond simple imitation, they added a preference-learning step (a kind of offline reinforcement learning) so the model learns which changes raised the score and which made it worse.
Two simple analogies:
- Evolutionary search = breeding better ideas: keep the best, make small changes (mutations), test, and repeat.
- EFT = studying highlights from many “games” so you learn patterns that help you win new games faster.
What they found and why it matters
- Better results on new tasks
- Models trained with EFT did better than the same models without EFT on 22 held-out tasks, with an average improvement of about 10%.
- In some cases, the EFT-tuned smaller models matched or beat larger base models without EFT. That means you can get more out of smaller, cheaper models by training them this way.
- Strong performance on real challenges
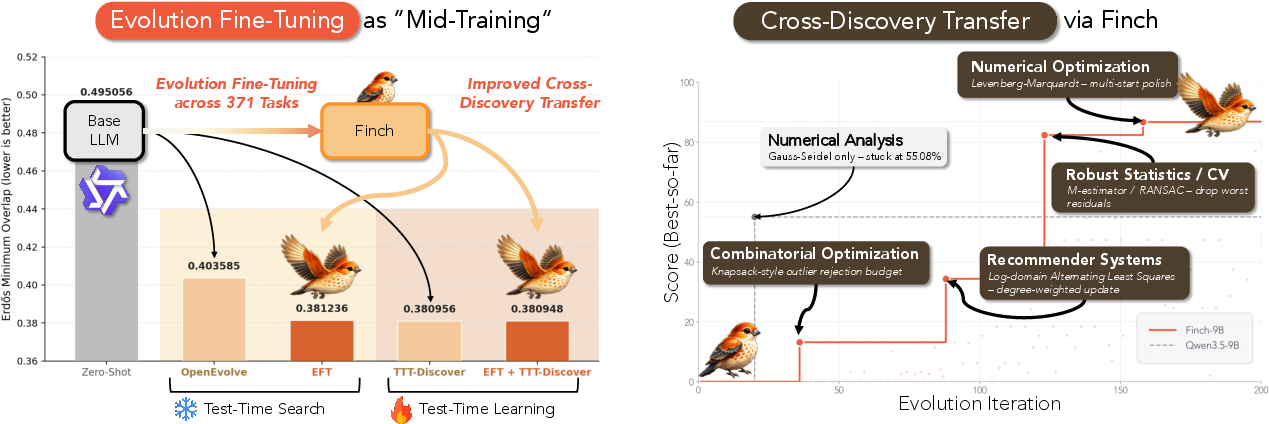
- The EFT models matched state-of-the-art results on two circle packing problems and improved on the Erdős minimum overlap problem.
- On competitive programming problems, EFT models used smarter, varied strategies learned from other domains, instead of repeating one simple trick.
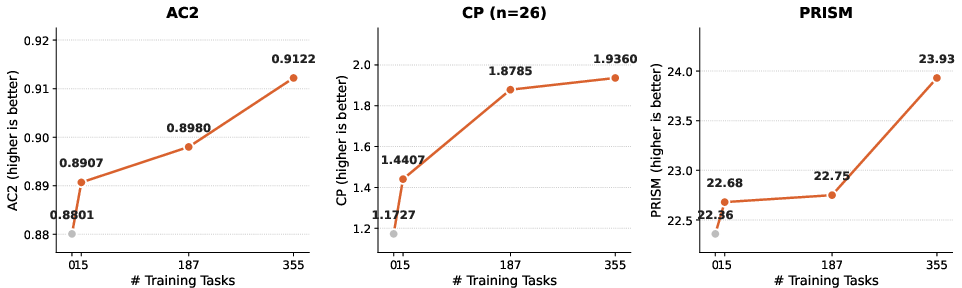
- Scales with more practice
- The more different tasks included in training, the better the model got at generalizing to new ones. This suggests adding more tasks and trajectories should keep improving discovery skills.
- Works well with test-time learning
- When they combined EFT with test-time reinforcement learning (where the model continues to learn while solving the new problem), performance improved even more. Think of EFT as a “training camp” that makes future on-the-fly learning more effective.
Why this is important:
- Instead of relying only on a clever search loop around the model, the model itself learns the art of improving—what to change, what to keep, and when to backtrack. That makes the AI more reusable across new problems and reduces how much heavy scaffolding you need each time.
What this could mean going forward
- Faster progress on tough problems: From math conjectures to faster code, models that “know how to improve” could push towards better solutions more quickly.
- More power from smaller models: Teaching improvement strategies can let smaller, open models perform closer to big, expensive ones—good for wider access and lower costs.
- A path to general-purpose “discovery” agents: EFT is like a practice phase for an AI inventor—learn from many past searches so you don’t start from scratch every time.
- Room to grow: Adding more diverse tasks, better feedback, and different search styles could make these models even better at transferring strategies across domains.
In short, this paper shows how to train AI to practice improving—so it gets better at discovering solutions across many different kinds of hard problems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased as concrete, actionable gaps for future work.
- Scaffold dependence and transferability:
- Training and evaluation both rely on OpenEvolve; it is unclear how well EFT models transfer to different evolutionary scaffolds with distinct parent selection, feedback formats, prompt templates, or proposal operators (e.g., MAP-Elites variants, bandit-based scaffolds, or multi-agent frameworks).
- The inputs include scaffold-specific histories and feedback; robustness to alternative formatting and content is not assessed.
- Held-out rigor and potential data leakage:
- The paper alternately references 16 and 22 held-out tasks without a precise mapping of overlaps with training sources; a rigorous de-duplication protocol and leakage audit (by task family, objective, and evaluator) is not provided.
- Limited evaluation breadth and statistical reliability:
- Results are reported on 22 tasks with single runs and no variance/confidence intervals; sensitivity to seeds, decoding parameters, and iteration budgets (T) is unknown.
- Small or mixed gains (and some regressions) are not analyzed with statistical tests; sample-efficiency metrics (e.g., improvement per iteration) are not reported.
- Generality beyond Python/C++ and domain coverage:
- The dataset is ~68.5% Python and ~31.5% C++; generalization to other languages (e.g., Rust, CUDA, Julia) and to more diverse domains (e.g., theorem proving, hardware-aware kernels on real devices) is untested.
- GPU kernel evaluation coverage is limited (4 tasks, 1,088 trajectories) and it is unclear whether performance is measured on real hardware or simulators.
- Teacher-dependence and stylistic imprinting:
- All trajectories are generated with a single teacher (Qwen3.5-397B-A17B); robustness to different teachers, ensemble teachers, or weaker/stronger teachers is unknown.
- Potential overfitting to teacher-specific proposal styles and prompt conventions is not examined.
- Training signal design and credit assignment:
- Supervised fine-tuning uses single-step transitions and primarily “improved” trajectories; optimal mixtures of improved/no-change/regressed examples and curricula remain unresolved.
- Offline RL uses pairwise preference learning (KTO) between improved and regressed, but does not address sequence-level credit assignment or multi-step return optimization; comparisons to alternative offline RL methods (e.g., DPO, RRHF, IQL, sequence-level reward models) are missing.
- Error handling and robustness:
- Filtering removes “unrecoverable,” “breakage,” and long examples (length > 32,768 tokens), reducing exposure to runtime errors, timeouts, and long-horizon contexts; the model’s ability to detect, recover from, or proactively avoid such failures remains untrained and unmeasured.
- How EFT models behave under stochastic or non-deterministic evaluators (in contrast to the deterministic ones used here) is unexplored.
- Measuring “internalized discovery capability”:
- The work infers internalization from downstream performance but does not directly measure behaviors like mutation-type selection, adaptive step sizing, self-evaluation quality, or explicit backtracking heuristics; new diagnostics/benchmarks for these skills are needed.
- No ablation disentangles gains from better “local refinement” versus “global exploration,” or from diff-edit versus full-rewrite behaviors.
- Synergy with test-time RL is only partially assessed:
- Test-time RL is evaluated on a few math tasks using a reproduction (nanodiscover) rather than the original TTT-Discover due to cost; generality across domains and scaffolds, and effects on stability and sample efficiency, are untested.
- The notion of EFT as “mid-training” for RL is promising, but the best way to combine EFT with online updates (e.g., interleaving, warm-start strategies, or policy regularization) is open.
- Scaling laws and data utilization:
- Scaling analyses consider number of tasks but not trajectories per task, model context length, or longer training (only one epoch used); the shape of performance–data–compute trade-offs is unknown.
- To mitigate imbalance, only one trajectory per task is used for SFT, discarding much data; principled reweighting, stratified sampling, or task-balanced batching could be more effective and remain untested.
- Failure modes and negative transfer:
- EFT degrades or yields negligible gains on some tasks (e.g., Hadamard for smaller models; slight PRISM drop at 9B); root-cause analyses (e.g., domain conflicts, overfitting to SR-heavy data, or miscalibrated mutation sizes) are absent.
- Zero-shot and minimal-scaffold capabilities:
- The paper evaluates EFT models only as mutation operators within a scaffold; it does not test whether EFT improves one-shot or few-shot solution quality without iterative search.
- Context length and memory limitations:
- Training/inference uses long contexts (up to ~30K tokens) on long-context models; the impact of shorter windows, truncation strategies, or memory-augmented architectures is not explored.
- Choosing mutation strategies and meta-decisions:
- The model is trained to produce candidates but does not learn meta-actions (e.g., whether to diff-edit vs rewrite, when to backtrack, which parent to select); mechanisms to internalize or output such decisions are uninvestigated.
- Generalization across base model families and tuning methods:
- EFT is demonstrated only on Qwen-family models with full SFT; portability to other architectures (e.g., Llama, Mistral), parameter-efficient methods (e.g., LoRA), or mixing with continued pretraining is unknown.
- Practical reproducibility and compute-cost profiling:
- Compute budgets, wall-clock times, and cost comparisons (EFT vs. non-EFT; different budgets T) are not provided; reproducibility across hardware, seeds, and evaluator versions requires further documentation and scripts.
- Dataset transparency and licensing:
- While links are provided, licensing compatibility of third-party tasks/benchmarks, evaluator reproducibility, and long-term availability are not detailed; full release of prompts, histories, and filtering criteria (with code) would strengthen reproducibility.
- Broader applicability and safety:
- Effects on safety (e.g., generating unsafe code or exploitative optimizations), robustness to adversarial evaluators, and alignment with real-world constraints (e.g., runtime, memory, energy) are not analyzed.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging the paper’s Evolution Fine-Tuning (EFT) paradigm, the FINCH-{2,4,8,9}B models, and the released trajectory dataset to internalize “discovery” capability in smaller open-source LLMs.
- Auto-optimization agents for code and systems performance
- Sector: Software, Systems, HPC
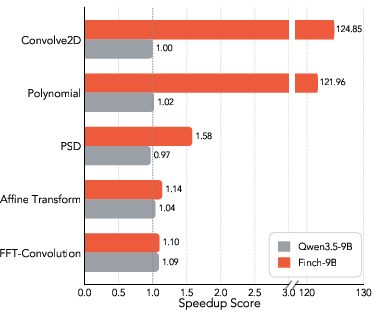
- Use case: Drop-in mutation operators for existing evolutionary search scaffolds (e.g., OpenEvolve) to iteratively improve code performance, memory usage, or accuracy within CI/CD. Examples include accelerating numerical routines (e.g., FFT convolution, 2D convolution), optimizing competitive programming solutions, and tuning system microbenchmarks (e.g., PRISM, Transaction, EPLB).
- Tools/workflows:
- A “Performance Optimizer Bot” integrated with GitHub Actions that runs N iterations, evaluates with deterministic benchmarks, and proposes diff-based edits or full rewrites.
- FINCH-{4,8,9}B as the mutation operator; optional KTO-based offline RL to rank candidate patches by expected improvement.
- Assumptions/dependencies: Reliable, deterministic evaluators; reproducible benchmarking harness; sandboxed execution; long-context inference (up to ~30K tokens); guardrails for correctness regressions.
- GPU kernel auto-tuning
- Sector: HPC, ML infrastructure
- Use case: Iteratively propose optimized CUDA kernels (e.g., memory access patterns, block sizes) and measure speed/occupancy with hardware-in-the-loop evaluation.
- Tools/workflows: Kernel optimization loops that combine FINCH models with KernelBench/GPU Mode-style evaluators; diff-based kernel edits guided by domain-specific prompts.
- Assumptions/dependencies: Stable hardware evaluators; safe kernel execution environments; domain prompts capturing architecture constraints.
- SQL query and data pipeline tuning
- Sector: Databases, Data Engineering
- Use case: Mutate SQL queries, indexing strategies, and ETL steps to improve throughput/latency without changing semantics, reflecting gains observed on LLM-SQL and Transaction tasks.
- Tools/workflows: “SQL Optimizer Copilot” that generates alternative query plans and index configurations, validated in staging via regression and load tests.
- Assumptions/dependencies: Semantics-preserving checks; representative workloads; rollback/canary deployment; cost-aware evaluation metrics.
- Numerical algorithm and library refactoring
- Sector: Scientific Computing, ML/AI Libraries
- Use case: Replace suboptimal implementations (e.g., switching SciPy to JAX for convolution operations) or tune algorithmic parameters (e.g., PSD projections, affine transform heuristics).
- Tools/workflows: Evolutionary refactoring pipelines that auto-propose library-level changes; curated algorithmic benchmarks (AlgoTune-style) for acceptance tests.
- Assumptions/dependencies: Comprehensive test suites to ensure correctness and precision; performance benchmarking across target platforms; cross-language support (Python/C++).
- Symbolic regression for scientific law discovery
- Sector: Scientific Research (Physics, Biology, Chemistry)
- Use case: Fit governing equations to data via iterative mutation and evaluator-driven scoring (LLM-SRBench-style), accelerating hypothesis generation and model selection.
- Tools/workflows: “Equation Discovery Assistant” that evolves candidate symbolic forms; integrates with lab data pipelines.
- Assumptions/dependencies: High-quality datasets; domain constraints (e.g., dimensional consistency); validation using out-of-sample data to avoid overfitting.
- Competitive programming and algorithm design tutor
- Sector: Education, Software Engineering
- Use case: Interactive training that demonstrates cross-domain strategy transfer (e.g., log-domain ALS, Levenberg–Marquardt) while iteratively improving solutions to NP-hard problems.
- Tools/workflows: IDE plugin that runs evolutionary attempts locally, visualizes score improvements, and explains strategy choices.
- Assumptions/dependencies: Problem-specific evaluators; time/compute budgets; content aligned with curricula or contest rules.
- Organization-specific EFT mid-training
- Sector: Enterprise Software, R&D
- Use case: Construct internal evolutionary trajectory datasets for proprietary workloads (e.g., service-specific optimizers, domain libraries) and mid-train open-source LLMs to outperform general baselines on in-house tasks.
- Tools/workflows: Data pipeline modeled on the paper’s 3-step construction (seed tasks, scaffolded trajectories, filtering); SFT on improved trajectories; preference learning (KTO) on improved vs regressed examples.
- Assumptions/dependencies: Clear optimization objectives; robust evaluators; data privacy/compliance controls; training infrastructure (8× H200 or equivalent for larger models).
- Cost-efficient replacements for proprietary mutation operators
- Sector: Policy/Procurement, Public Sector IT
- Use case: Replace frontier proprietary LLMs in discovery scaffolds with smaller, open-source FINCH models while retaining competitive performance across diverse tasks.
- Tools/workflows: Reference deployments using OpenEvolve; standardized evaluator suites and reporting; governance templates for model selection and audit.
- Assumptions/dependencies: Fit-for-purpose accuracy/performance; staff training on evolutionary workflows; ongoing benchmarking to monitor drift.
Long-Term Applications
These applications require further research, scaling, or engineering—often combining EFT with larger models, richer evaluators, or tighter integration into real-world systems.
- General-purpose discovery agents for scientific and engineering breakthroughs
- Sector: Science, Engineering
- Use case: Agents that propose, test, and refine new laws, algorithms, or designs across domains, composing strategies discovered via EFT and adapting at test time via RL.
- Tools/workflows: Integrated AutoLab-style platforms; closed-loop experiment planning; multi-objective optimization and Pareto-front exploration.
- Assumptions/dependencies: Reliable experiment evaluators (physical/virtual), safety governance, provenance tracking, and compute resources for large-scale iterative discovery.
- Automated theorem exploration with formal verification
- Sector: Mathematics, Formal Methods
- Use case: Evolve candidate constructions, counterexamples, and proof sketches, coupled with proof assistants (e.g., Lean, Coq) and combinatorial evaluators (Erdős-style tasks).
- Tools/workflows: Hybrid scaffold combining EFT models, formal checkers, and counterexample generators; iterative strengthening via test-time RL.
- Assumptions/dependencies: Formal evaluator integration; scalable search; larger models for deep reasoning; rigorous correctness guarantees.
- Autonomous production system tuners
- Sector: Cloud, DevOps, SRE
- Use case: Always-on agents that tune microservice configs (e.g., thread pools, caches), database parameters, and deployment topologies with canary rollouts and automatic rollback.
- Tools/workflows: Safe experiment frameworks; policy-driven guardrails; anomaly detection; chaos engineering to validate resilience.
- Assumptions/dependencies: Robust observability; failure containment; human-in-the-loop escalation; regulatory/compliance constraints.
- Robotics/control policy optimization
- Sector: Robotics, Autonomous Systems
- Use case: Mutation-based tuning of control code and planner parameters in simulation, with sim-to-real transfer and safety constraints.
- Tools/workflows: High-fidelity simulators; hardware-in-the-loop evaluators; hybrid search + learning (EFT + test-time RL).
- Assumptions/dependencies: Accurate simulators; real-time constraints; safety certifications; domain adaptation from Python/C++ to embedded stacks.
- Energy systems and grid optimization
- Sector: Energy, Utilities
- Use case: Evolve scheduling, dispatch, and demand response strategies under multi-objective, stochastic environments (cost, reliability, emissions).
- Tools/workflows: Digital twins; multi-objective evaluators; scenario-based stress tests; policy-aware optimization.
- Assumptions/dependencies: High-quality simulators; regulatory constraints; robust objective formulations; human oversight.
- Finance: portfolio and strategy optimization
- Sector: Finance
- Use case: Propose and refine trading strategies, portfolio allocations, and risk hedges within strict risk controls and compliance frameworks.
- Tools/workflows: Backtesting engines; out-of-sample validation; constraints-aware mutation operators; explainability reports for governance.
- Assumptions/dependencies: Non-stationary markets; risk management; regulatory compliance; robust evaluators beyond backtest metrics.
- Multi-agent evolutionary discovery frameworks
- Sector: Software Tools, AI Platforms
- Use case: Scale EFT to multi-agent systems (e.g., HyperAgents/CORAL-style) where specialized agents co-evolve solutions under diversity and novelty objectives.
- Tools/workflows: Agent orchestration; quality-diversity archives; adaptive prompting; meta-evolution of scaffolds themselves.
- Assumptions/dependencies: Larger datasets/compute; stability of multi-agent dynamics; careful reward shaping.
- Public-sector optimization and procurement modernization
- Sector: Policy, Government
- Use case: Open-source discovery agents for infrastructure tuning (transport, IT systems), deploying cost-effective, transparent tools with auditable evaluators.
- Tools/workflows: Standards for evaluator design; public benchmarking; audit trails; stakeholder review processes.
- Assumptions/dependencies: Procurement reform; data governance; transparency mandates; workforce upskilling.
- Education platforms for strategy transfer and discovery skills
- Sector: Education
- Use case: Curricula and sandboxes where students see cross-domain strategy transfer (as observed with FINCH) and learn iterative optimization with evaluators.
- Tools/workflows: Course-integrated scaffolds; interpretable logs and visualizations; scaffolded projects spanning math, programming, and optimization.
- Assumptions/dependencies: Curated tasks with clear metrics; safe execution environments; equitable access to compute resources.
Note: Across all applications, feasibility depends on the availability of well-specified evaluators, robust scaffolds (search and/or learning), sufficient compute/budget for iterative runs, long-context model support, and guardrails to prevent regressions or unsafe mutations. Scaling benefits shown in the paper (more tasks → stronger cross-task generalization) imply that expanding trajectory datasets and model capacity will systematically improve long-term viability.
Glossary
- Alternating least squares: An iterative optimization method often used in recommender systems to factorize matrices by alternately updating one set of variables while holding the other fixed. "applying log-domain alternating least squares from recommender system, Levenberg-Marquardt from numerical optimization to solve a competitive programming problem"
- Autocorrelation inequality (AC1/AC2): Mathematical optimization tasks involving bounds on autocorrelation sequences; AC1 and AC2 denote the first and second inequalities respectively. "including the ErdÅs Minimum Overlap Problem (Erdos), First Autocorrelation Inequality (AC1), Second Autocorrelation Inequality (AC2), Circle Packing in a Unit Square with (CP), and Hadamard Maximum Determinant (Hadamard)"
- Bandit-based LLM selection: A strategy that frames choosing among multiple LLMs as a multi-armed bandit problem to allocate attempts adaptively based on performance. "combining weighted sampling, novelty rejection, and bandit-based LLM selection"
- Circle packing: A geometric optimization problem of arranging circles (e.g., in a unit square) to optimize a criterion such as minimum overlap or maximum radius. "Circle Packing in a Unit Square with (CP)"
- Combinatorial optimization: Optimization over discrete structures (e.g., graphs, sets) where the search space is combinatorial and often NP-hard. "such as combinatorial optimization, recommender systems, robust statistics/computer vision, and numerical optimization"
- Cross-task generalization: The ability of a model to transfer learned problem-solving strategies to new, unseen tasks across domains. "Empirically, EFT confers cross-task generalization: across 22 held-out tasks, our models surpass their base counterparts by 10.22\% on average."
- Diff-based edit: A mutation strategy that edits an existing solution by producing a minimal diff rather than rewriting the entire program. "we collect trajectories under two mutation strategies: diff-based edit and full rewrite"
- ErdÅs minimum-overlap problem: A long-standing combinatorial optimization problem posed by Erdős about minimizing overlaps in set constructions. "open mathematical conjectures such as the ErdÅs minimum-overlap problem"
- Evaluator: The component that executes a candidate solution and returns a score and artifacts (e.g., logs, feedback) used to guide the search. "An evaluator assigns a score and auxiliary artifacts such as logs or natural-language feedback."
- Evolution Fine-Tuning (EFT): A mid-training approach that fine-tunes LLMs on evolutionary search trajectories so they learn to generate improved solutions across tasks. "we introduce Evolution Fine-Tuning (EFT), a mid-training paradigm that teaches LLMs to evolve solutions across tasks by converting evolutionary search trajectories into supervision."
- Evolutionary scaffold: The structured loop around an LLM that handles prompting, candidate generation, evaluation, and population maintenance during evolutionary search. "Evolutionary scaffolds can discover strong solutions at test time, but the discovery procedure is typically external to the model."
- Full rewrite: A mutation strategy that discards the parent solution and asks the model to produce a completely new candidate, encouraging exploration. "full rewrite asks the model to rewrite the solution and therefore encourages broader exploration"
- Gauss-Seidel: An iterative method for solving linear systems, here referenced as a heuristic update strategy. "Gauss-Seidel uniform weight"
- Hadamard maximum determinant: An optimization problem of finding matrices (often ±1) with maximum determinant, related to Hadamard matrices. "Hadamard Maximum Determinant (Hadamard)"
- Island-based populations: A population structure in evolutionary algorithms where multiple subpopulations (islands) evolve in parallel with occasional migration. "employs MAP-Elites with island-based populations to balance exploration and exploitation"
- KTO: A preference-learning algorithm (Kahneman–Tversky Optimization) used to train models to prefer higher-quality solutions from trajectory pairs. "a preference learning algorithm (i.e., KTO~\citep{ethayarajh2024kto})"
- LLM: A neural network trained on large text corpora that generates or transforms text and can act as a mutation operator in search. "LLMs integrated into evolutionary search have recently produced state-of-the-art solutions on optimization tasks"
- Levenberg–Marquardt: A damped least-squares optimization algorithm commonly used for nonlinear least squares problems. "applying log-domain alternating least squares from recommender system, Levenberg-Marquardt from numerical optimization"
- MAP-Elites: A quality–diversity evolutionary algorithm that maintains a map of high-performing solutions across behavior characteristics. "AlphaEvolve~\citep{novikov2025alphaevolve} employs MAP-Elites with island-based populations to balance exploration and exploitation"
- Meta-learning: Learning to learn; here, teaching a model general discovery strategies that transfer across tasks. "have the LLM itself meta-learn the discovery capability (i.e., learning how to evolve solutions across optimization tasks)."
- Mid-training: An intermediate training phase conducted after pretraining but before deployment, targeted at specific capabilities. "EFT serves as ``mid-training'', boosting 's discovery capability on the Erd\H{o}s minimum overlap problem"
- Mutation operator: The component (often an LLM) that proposes new candidate solutions from parents and search context in evolutionary search. "a mutation operator , typically an LLM, to produce a new candidate"
- Novelty rejection: A selection mechanism that filters candidates based on novelty criteria to maintain exploration efficiency. "combining weighted sampling, novelty rejection, and bandit-based LLM selection"
- Offline RL: Reinforcement learning performed on fixed datasets without online interaction during training. "Effect of Offline RL (CP: avg.\ competitive programming score)."
- Online (test-time) RL: Reinforcement learning where the model updates its parameters during the search on the target task. "Performance of -0.2ex combined with online (test-time) RL scaffolds across math optimization tasks."
- OpenEvolve: An open-source evolutionary search scaffold used for trajectory collection and evaluation across tasks. "a widely used search scaffold, i.e., OpenEvolve~\citep{openevolve}"
- Pareto frontier: The set of non-dominated solutions in multi-objective optimization where improving one objective worsens another. "GEPA operates along Pareto frontiers"
- Population database: The maintained archive of candidate solutions used for selection and future mutations in evolutionary search. "store eligible candidates in a population database "
- Preference learning: Training a model to rank or choose between outputs based on relative quality signals rather than absolute labels. "a preference learning algorithm (i.e., KTO~\citep{ethayarajh2024kto})"
- Quality–diversity grid: A discretized behavior space used to preserve diverse high-quality solutions in quality–diversity algorithms. "replaces fixed qualityâdiversity grids with a sample-efficient regime"
- Reinforcement learning (RL): A learning paradigm where an agent optimizes behavior through reward feedback, used here at test time to adapt LLMs. "Test-time learning-based methods update the model through test-time RL"
- Stochastic decoding: Randomized text generation (e.g., with temperature and top-p) to explore diverse candidate solutions. "we run the scaffold multiple times per task with stochastic decoding."
- Symbolic regression: The task of discovering analytic expressions that fit data, rather than fitting numeric parameters in a fixed form. "Symbolic Regression (SR) trajectories constituting the majority"
- Temperature (sampling): A decoding parameter that controls randomness by smoothing/sharpening the probability distribution over next tokens. "Unless otherwise specified, we use temperature $0.7$, top-, and a maximum generation length of 30K tokens."
- Test-time learning: Adapting model weights during evaluation on a target task, often via RL, to specialize to that task. "Test-time learning methods additionally update the LLM's weights during the search process"
- Test-time search: Running a search procedure around a fixed model at inference, without updating weights, to discover better solutions. "Test-time search methods use a fixed, typically proprietary LLM as the mutation operator and rely on the scaffold's parent selection and prompting logic to drive improvement"
- Top-p (nucleus sampling): A decoding method that samples from the smallest set of tokens whose cumulative probability exceeds p. "Unless otherwise specified, we use temperature $0.7$, top-, and a maximum generation length of 30K tokens."
- Trajectory (evolutionary trajectory): The recorded sequence of states and mutations during search, used as supervision for EFT. "converting evolutionary search trajectories into supervision."
Collections
Sign up for free to add this paper to one or more collections.