- The paper demonstrates that small, instruction-tuned LVLMs benefit from test-time scaling, achieving up to 30% accuracy improvements in reasoning tasks.
- The study shows that chain-of-thought prompting and related techniques yield an optimal compute-vs-accuracy trade-off particularly favorable for reasoning-intensive benchmarks.
- The investigation reveals that excessive reasoning in TTS can harm performance on perception tasks due to overlong generation and diminishing image-token attention.
Comprehensive Study of Test-Time Scaling for Vision-LLMs
Introduction and Motivation
The paper "On Test-Time Scaling for Vision-LLMs" (2606.28864) presents the first thorough analysis of zero-shot test-time scaling (TTS) methods applied to Large Vision-LLMs (LVLMs). TTS refers to increasing compute at inference to elicit enhanced reasoning capacities in models, without modifying parameters. While TTS has been extensively analyzed for LLMs, its efficacy for LVLMs—especially across different scales, architectures, and benchmarks—remains underexplored. The central objective is to determine whether established TTS techniques from the LLM domain are directly transferable and beneficial for LVLMs.
Methodology
The study evaluates a comprehensive set of TTS approaches—including standard CoT prompting, plan-and-solve, self-consistency, self-aggregation, self-refinement, and prompt repetition, as well as LVLM-specific strategies like Describe-Answer and Compositional CoT—across a wide spectrum of instruction-following LVLMs, varying in scale from 2B to 72B parameters and covering series such as Qwen-2.5-VL, Qwen-3-VL, InternVL-3.5, and Molmo2.
Experimental evaluations span six diverse benchmarks: MMStar (perception and reasoning), RealWorldQA (perception-only), HallusionBench (reasoning and hallucination), WeMath (mathematical reasoning), LogicVista (logical reasoning), and A-OKVQA (perception-only). For all models, up to 1024 generation tokens were permitted, with token budgets systematically varied for ablation studies.
Main Empirical Findings
Contrary to prior LLM literature reporting minimal or negative TTS gains in small models, this work demonstrates that small, capable instruction-tuned LVLMs benefit disproportionately from TTS. For instance, a Qwen3-VL-2B model, when equipped with self-consistency prompting, achieves a +30% improvement on WeMath (from 35% to 64% accuracy), matching or surpassing the performance of much larger (32B) vanilla models. In multiple cases, small models with TTS even outperform their larger, unscaled counterparts on complex reasoning datasets.
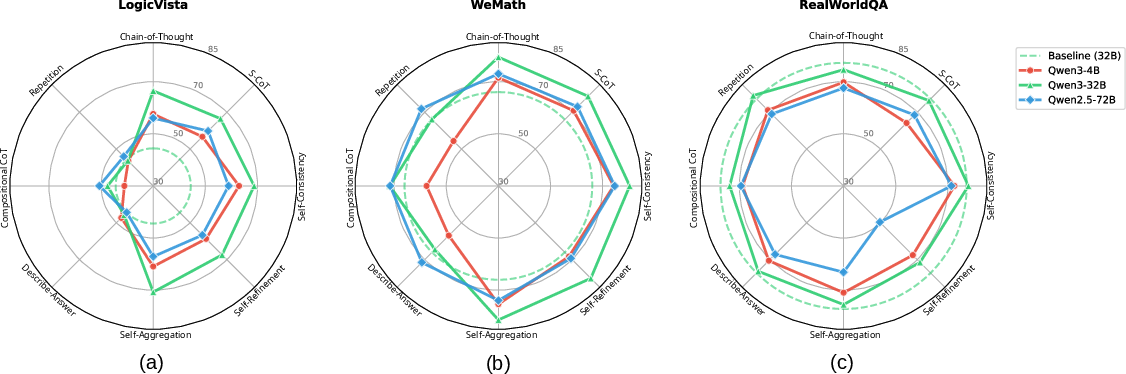
Figure 1: Eight test-time scaling methods evaluated on three benchmarks and three LVLM scales, highlighting substantial improvements in small models with TTS.
Compute-Efficiency Trade-Offs
Compute-vs-accuracy analysis reveals that under a fixed compute budget, deploying a small LVLM with TTS can yield comparable or superior results to running a larger model at baseline, particularly for reasoning tasks. Among all evaluated methods, CoT prompting frequently offers the best trade-off between runtime and accuracy improvements.
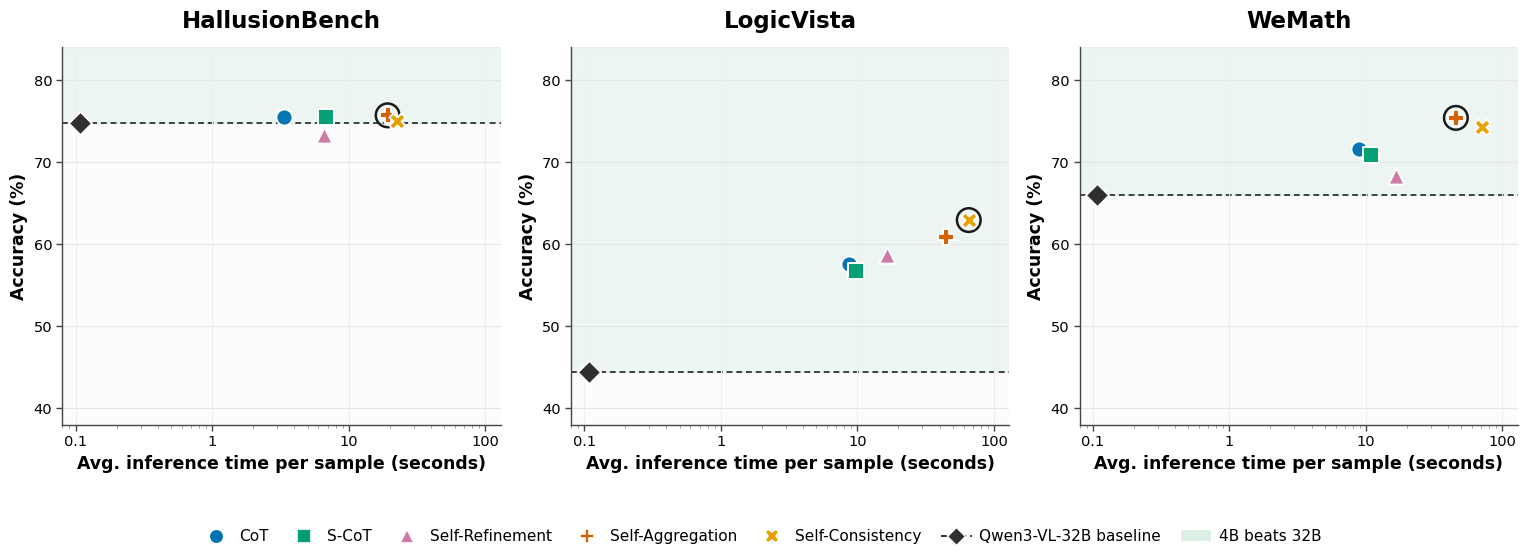
Figure 2: Compute vs Accuracy Pareto frontier, with the optimal TTS configuration circled.
Negative Effects on Perceptual Benchmarks
An important observation is that on perception-centric tasks (e.g., RealWorldQA, A-OKVQA), additional compute and verbose generation induced by TTS often degrades performance relative to the baseline. The degradation, also observed to a lesser degree in closed-source models like GPT-5.2, stems from excessive reasoning causing the model to hallucinate or drift away from visually-grounded answers.
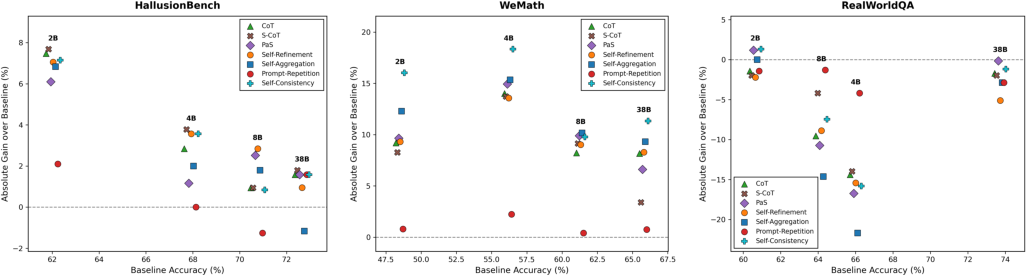
Figure 3: The impact of TTS methods on InternVL-3.5, reinforcing that smaller models benefit the most, with perceptual tasks sometimes harmed.
Token Budget and Overthinking
Truncating TTS-induced reasoning chains (to 300 tokens) clarifies that for reasoning tasks, performance drops—indicating that logical reasoning steps are essential to correct answers in LVLMs. In contrast, for perception tasks, shorter outputs are often optimal. The phenomenon wherein overlong generation leads to accrued errors and hallucinations, termed "losing focus," supports the need for task-adaptive TTS deployment.
Attention analysis across LVLM generation chains reveals an early, brief interval where the model intensely attends to visual tokens, encoding visual semantics into hidden states. As generation progresses, attention to image tokens drops precipitously, while focus on previously generated tokens—reflecting textual reasoning—dominates. Later reasoning steps rely almost exclusively on the representations formed early, confirming that prolonged image access is unnecessary and that long CoTs amplify text-only reasoning prone to drift.
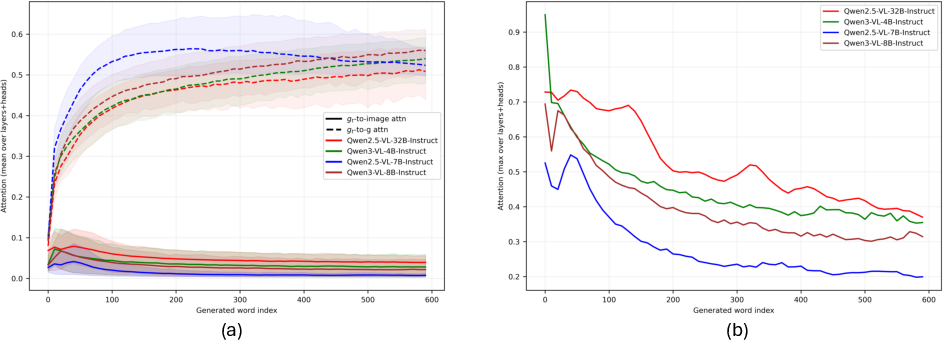
Figure 4: Attention traces during CoT reasoning for WeMath, showing rapid decay in image-token attention and a corresponding rise in self-attention.
These claims are causally supported by intervention experiments: forcibly removing image tokens at various points during generation reveals that only early-stage removal impairs accuracy, while late-stage removal (after ∼200 tokens) is almost cost-free.
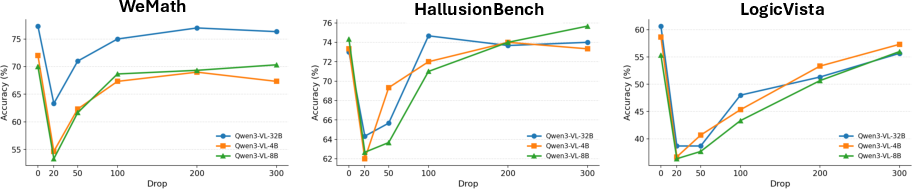
Figure 5: Accuracy as a function of image-token dropping step, illustrating the front-loading of visual encoding.
Rationale Quality and Evaluation
Comparisons of LVLM outputs and rationales against judgments from external LLM judges and human annotators indicate high agreement, especially for stronger models. Rationale sufficiency typically tracks the model's own answer accuracy, though smaller/weaker models display a gap, indicating areas for improvement in intermediate rationalization. Fine-grained temporal analysis shows that rationales transition from uncertainty to supported conclusions as the chain progresses, typically solidifying the answer towards the latter part of the generation.
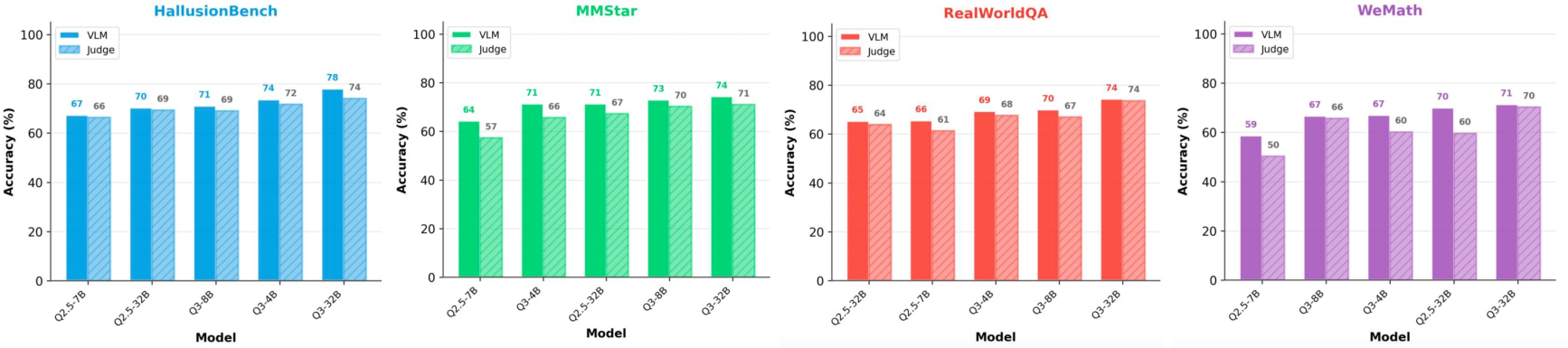
Figure 6: Agreement of rationale-derived and LVLM-native answers across benchmarks and scales.
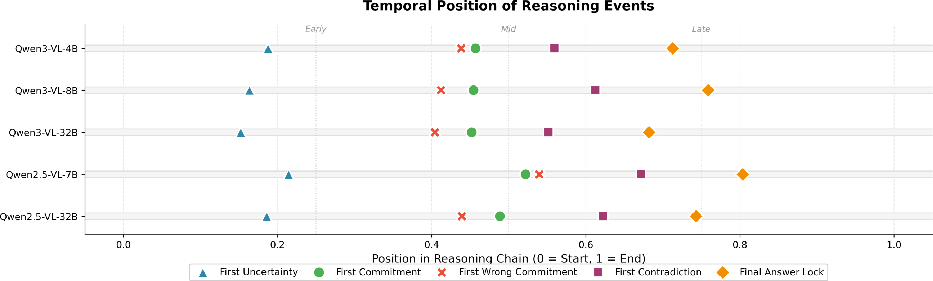
Figure 7: Fine-grained analysis of rationale sentence dynamics, revealing the temporal emergence of sufficient information.
Contradictory Findings and Implications
A particularly bold finding is the clear contradiction to accepted LLM findings: the strongest test-time scaling gains are observed in small, instruction-following LVLMs. This invalidates assumptions that TTS methods are ineffective in the low-parameter LVLM regime and demonstrates robust transferability of LLM TTS techniques to vision-language domains, conditional on high instruction compliance and reasoning capacity in the underlying LVLM architecture. By contrast, models such as LLaVA-OneVision-7B and SmolVLM2-2.2B, which exhibit poor instruction following, do not benefit from TTS. This underlines the critical role of training objectives and compliance for enabling TTS gains.
Theoretical and Practical Implications
Practically, these results suggest that for a broad range of research and industrial settings, significant inference cost savings can be achieved by deploying smaller LVLMs augmented with TTS rather than massive, computationally expensive models. However, this is only advisable when tasks have an explicit reasoning component. For pure perception or VQA-style queries, suppressing verbose reasoning at test-time is preferable, potentially by integrating a lightweight task classifier.
Architecturally, these findings highlight the need to design LVLMs whose attention mechanisms and token generation strategies are aware of the temporal window of visual grounding versus abstract reasoning, enabling efficient cache dropping or compute trimming. The causal relationship between attention decay and performance preservation supports further exploration of model-internal signals for adaptive compute allocation.
From a theoretical standpoint, the observation that visual information is "front-loaded" in the reasoning chain, with subsequent self-referential textual expansion, points to an implicit decoupling of vision and language after initial fusion. This may guide future multimodal model architectures toward more modular, timing-aware processing pipelines, with explicit mechanisms for gating image-token processing past the critical early steps.
Future Directions
Key future research avenues include developing automated, sample-level task difficulty and reasoning-type classifiers to adaptively trigger TTS only where beneficial; further dissecting the interplay between multimodal fusion depth, reasoning chain structure, and robustness to hallucination; and investigating training protocol modifications that optimize instruction compliance for maximal TTS gains in LVLMs.
Conclusion
This work significantly advances the understanding of test-time scaling for LVLMs, demonstrating strong and sometimes counterintuitive gains for small instruction-following models, elucidating the mechanisms of visual and textual attention over reasoning chains, and defining precise contexts where TTS is beneficial or ineffective. Task-aware, compute-efficient LVLM deployment is made feasible by these insights, while newly revealed dynamics invite further investigation into temporally-structured multimodal reasoning and adaptive inference strategies.

