- The paper demonstrates that compute-optimal TTS strategies enable a 1B LLM to surpass a 405B LLM on challenging tasks.
- The paper reveals that aligning policy models, PRMs, and problem difficulty is critical for maximizing inference performance.
- The paper suggests that tailored test-time strategies can drive cost-efficient, high-performance AI deployments.
Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling
Introduction
LLMs have achieved significant advancements across diverse domains, primarily driven by increasing model sizes. Test-Time Scaling (TTS) has emerged as a pivotal mechanism for enhancing the reasoning capabilities of LLMs by devoting additional computational resources in the inference phase. Both internal TTS approaches using long Chain-of-Thought (CoT) processes, and external TTS methods involving sampling or search-based strategies, endeavor to optimize computation allocation. Despite their promising aspects, existing studies often overlook the intricate dynamics between policy models, Process Reward Models (PRMs), and problem difficulty levels, thus limiting their potential efficacy. This paper aims to systematically address these gaps by investigating optimal scaling approaches tailored to distinct policy models, PRMs, and problem difficulty levels.
Experimental Results and Observations
The paper presents comprehensive experiments conducted on MATH-500 and challenging AIME24 tasks, probing into the computational scaling strategies that enable smaller models to outperform larger ones significantly.
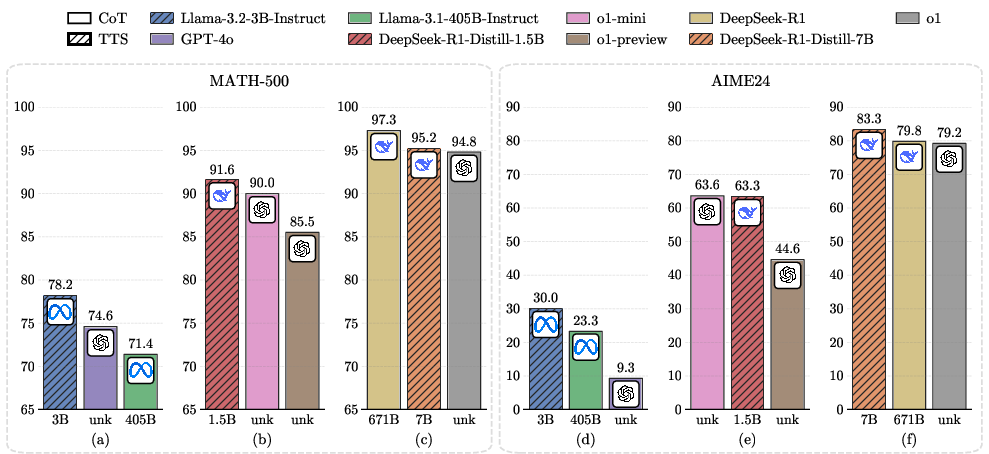
Figure 1: Comparison between the performance of smaller LLMs compute-optimal TTS and that of larger LLMs CoT on MATH-500 and AIME24.
Role of Policy Models and PRMs
The experiments delineate that the effectiveness of compute-optimal TTS strategies is intricately tied to the specific policy models and PRMs involved. Smaller models such as a 1B LLM have been observed surpassing a 405B LLM in performance on MATH-500 tasks, a finding that challenges conventional assumptions regarding model size superiority. This paradigm shift underscores the critical importance of aligning test-time computational strategies with the nuances of each policy model and PRM.
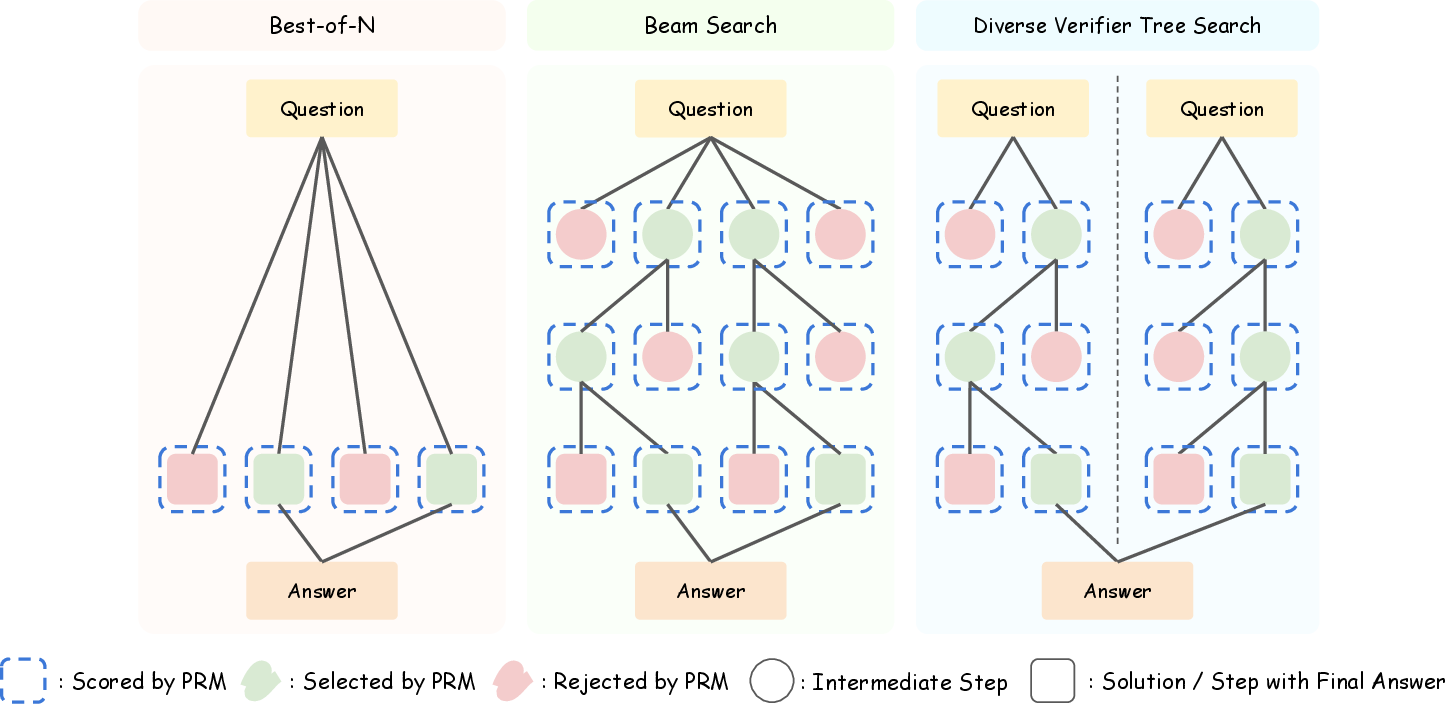
Figure 2: Comparison of different external TTS methods.
Problem Difficulty Impact
Moreover, the impact of problem difficulty on TTS efficacy cannot be overstated. It was observed that optimal TTS approaches varied significantly based on problem complexity, necessitating distinct scaling strategies for varied difficulty levels. Such adaptability is essential for maximizing the reasoning performance across different task landscapes.
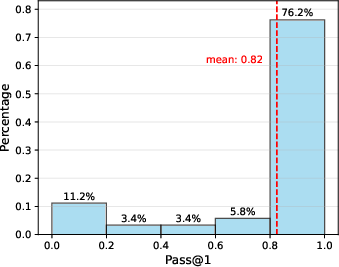
Figure 3: Distribution of Pass@1 accuracy of Qwen2.5-72B-Instruct on MATH-500, divided into five bins.
Implications for Future Developments
The findings from this study present pivotal insights that could guide future developments in AI. The ability of smaller LLMs to outperform considerably larger counterparts through tailored computational strategies suggests potential pathways for developing more resource-efficient models without compromising on performance. This could lead to substantial advancements in cost-effective AI deployments, where high computational expense and data consumption are minimized.
Additionally, the nuanced understanding of the interplay between policy models, PRMs, and problem types paves the way for developing highly specialized TTS strategies. These could be designed to cater to domain-specific challenges, further bolstering the versatility and applicability of LLMs across various sectors.
Conclusion
The paper "Can 1B LLM Surpass 405B LLM? Rethinking Compute-Optimal Test-Time Scaling" (2502.06703) profoundly influences the understanding and practical implementation of test-time computational strategies within LLM environments. By demonstrating that size is not the definitive determinant of model performance, it sets the stage for a new era of AI research focused on alignment, efficiency, and specialization. The adaptation of TTS methodologies could herald significant improvements in the reasoning capabilities and application breadth of future AI models.

